Python获取网页指定内容(BeautifulSoup工具的使用方法)
Python用做数据处理还是相当不错的,如果你想要做爬虫,Python是很好的选择,它有很多已经写好的类包,只要调用,即可完成很多复杂的功能,此文中所有的功能都是基于BeautifulSoup这个包。
1 Pyhton获取网页的内容(也就是源代码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址所对应的源代码,urllib2是需要用到的包,以上三句代码就能获得网页的整个源代码
2 获取网页中想要的内容(先要获得网页源代码,再分析网页源代码,找所对应的标签,然后提取出标签中的内容)
2.1 以豆瓣电影排名为例子
网址是http://movie.douban.com/top250?format=text,进入网址后就出现如下的图
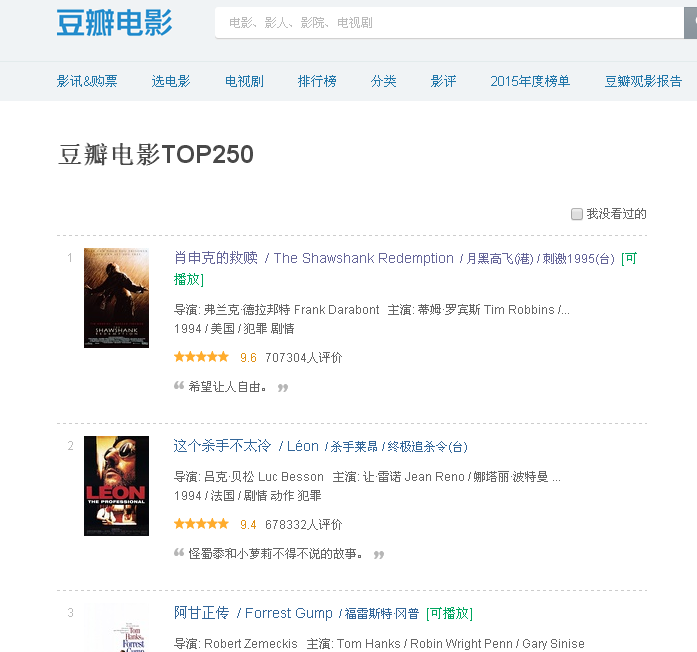
现在我需要获得当前页面的所有电影的名字,评分,评价人数,链接

由上图画红色圆圈的是我想得到的内容,画蓝色横线的为所对应的标签,这样就分析完了,现在就是写代码实现,Python提供了很多种方法去获得想要的内容,在此我使用BeautifulSoup来实现,非常的简单
控制台输出,你也可以写入文件中
前三行代码获得整个网页的源代码,之后开始使用BeautifulSoup进行标签分析,find_all方法是找到所有此标签的内容,然后在在此标签中继续寻找,如果标签有特殊的属性声明则一步就能找出来,如果没有特殊的属性声明就像此图中的评价人数前面的标签只有一个‘span’那么就找到所有的span标签,按顺序从中选相对应的,在此图中是第三个,所以这种方法可以找特定行或列的内容。代码比较简单,很容易就实现了,如果有什么地方不对,还请大家指出,大家共同学习。

源代码地址:http://download.csdn.net/detail/danielntz/9577390
转自:https://blog.csdn.net/danielntz/article/details/51861168
Python获取网页指定内容(BeautifulSoup工具的使用方法)的更多相关文章
- java 获取网页指定内容
import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.HttpURLConnection; ...
- [python]获取网页中内容为汉字的字符串的判断
实际上是这样,将获取到网页中表单内容与汉字字符串作比较,即: a = request.POST['a'] if a == '博客园': print 'ok' else: print 'false' a ...
- java 获取网页指定内容-2(实践+修改)
import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.HttpURLConnection; ...
- 黄聪:C#获取网页HTML内容的三种方式
C#通常有三种方法获取网页内容,使用WebClient.WebBrowser或者HttpWebRequest/HttpWebResponse. 方法一:使用WebClient static void ...
- Python获取网页Html文本
Python爬虫基础 1.获取网页文本 通过urllib2包,根据url获取网页的html文本内容并返回 #coding:utf-8 import requests, json, time, re, ...
- telnet建立http连接获取网页HTML内容
利用telnet可以与服务器建立http连接,获取网页,实现浏览器的功能.它对于需要对http header进行观察和测试到时候非常方便.因为浏览器看不到http header. 步骤如下: 1. 运 ...
- python 获取excel表内容 生成php数组
需求: 生成:同时处理数字类型,比如3 不能显示为3.0 [ ['type'=>3,'da_name'=>福建省平潭拓至美装饰工程有限公司,'da_aka'=>福建省平潭拓至美装饰工 ...
- MVC爬取网页指定内容到数据库
控制器 //获取并插入 //XPath获取 public JsonResult Add(string url) { HtmlWeb web = new HtmlWeb(); HtmlDocument ...
- python获取网页编码问题(encoding和apparent_encoding)
在requests获取网页的编码格式时,有两种方式,而结果也不同,通常用apparent_encoding更合适 注:推荐一个大佬写的关于获取网页编码格式以及requests中text()和conte ...
随机推荐
- 华为NB-IOT报告
转 https://blog.csdn.net/np4rHI455vg29y2/article/details/78958137 [NB-IoT]华为NB-IoT网络报告(完整版) 2018年01月0 ...
- 20175234 2018-2019-2 《Java程序设计》第三周学习总结
20175234 2018-2019-2 <Java程序设计>第三周学习总结 教材学习内容重难点总结 关于驼峰式的认识 为了增加程序的可读性,除了在代码之间增加注释之外,程序员大都把代码中 ...
- Linux驱动之输入子系统简析
输入子系统由驱动层.输入子系统核心.事件处理层三部分组成.一个输入事件,如鼠标移动.键盘按下等通过Driver->Inputcore->Event handler->userspac ...
- linux 安装mysql相关和openjdk
新装的centos 6.9虚拟机 修改yum 服务器源 cd /etc/yum.repos.d/ rename repo repo.bak_$(date +%F) * 阿里的yum库 https:/ ...
- 用户认证--auth模块实现
转载文章,如有不妥之处请谅解 相关介绍 auth auth模块是Django提供的标准权限管理系统,可以提供用户身份认证, 用户组和权限管理. auth可以和admin模块配合使用, 快速建立网站的管 ...
- nc 画界面,触发效果(第一种)
package nc.ui.hzctr.sellctr.action; import java.awt.BorderLayout; import java.awt.Dimension; import ...
- jQuery对象和DOM对象相互转换
DOM对象转为DOM对象: obj = document.getElementById('id') 使用$()包括对象即可 $(obj) jQuery对象转为DOM对象: 在对象后面添加[0] $(' ...
- 用windows性能监视器检测sqlserver 常见指标
转载地址:https://www.cnblogs.com/xdong/p/4296072.html
- OpenSessionViewFilter
OpenSessionViewFilter是spring提供的一个针对hibernate的一个支持类,其主要的意思是=在发起一个页面请求的时候打开session,并且保持session直到请求结束,具 ...
- 在datasnap 中使用unidac 访问数据(服务器端)
从delphi 6 开始,datasnap 作为delphi 自带的多层框架,一直更新到最新的delphi 10.3 .同时逐步增加了很多新的功能 ,比如支持REST 调用,支持 IIS ,apach ...