学习使用scrapy itemspipeline过程
开始非常不理解from https://www.jianshu.com/p/18ec820fe706 找到了一个比较完整的借鉴,然后编写自己的煎蛋pipeline
首先在items里创建
image_urls = scrapy.Field() #
images = scrapy.Field() #这两个是必须的
image_paths = scrapy.Field() #这个是因为在pipeline中设置了image_paths,所以这里要有,但不是必须的
然后在settings里面打开pipeline
ITEM_PIPELINES = {'jiandan.pipelines.JianPipeline': 1} #这里是打开pipeline
IMAGES_STORE =r'F:\jiandan' #这里是存储位置,绝对路径;
然后在pipeline里编写jianpipeline
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem class JianPipeline(ImagesPipeline): def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield scrapy.Request(image_url) def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths #在这里写了image_paths,所以要在items里面声明item
return item
#此段完全摘抄自别人的代码,然后在自己里面用,
在spider主程序中只要生成item就好了,别的不用管
yield JiandanItem({
'image_urls':urls , #只要生成这个image_urls,pipeline会自动下载这里面的链接
})
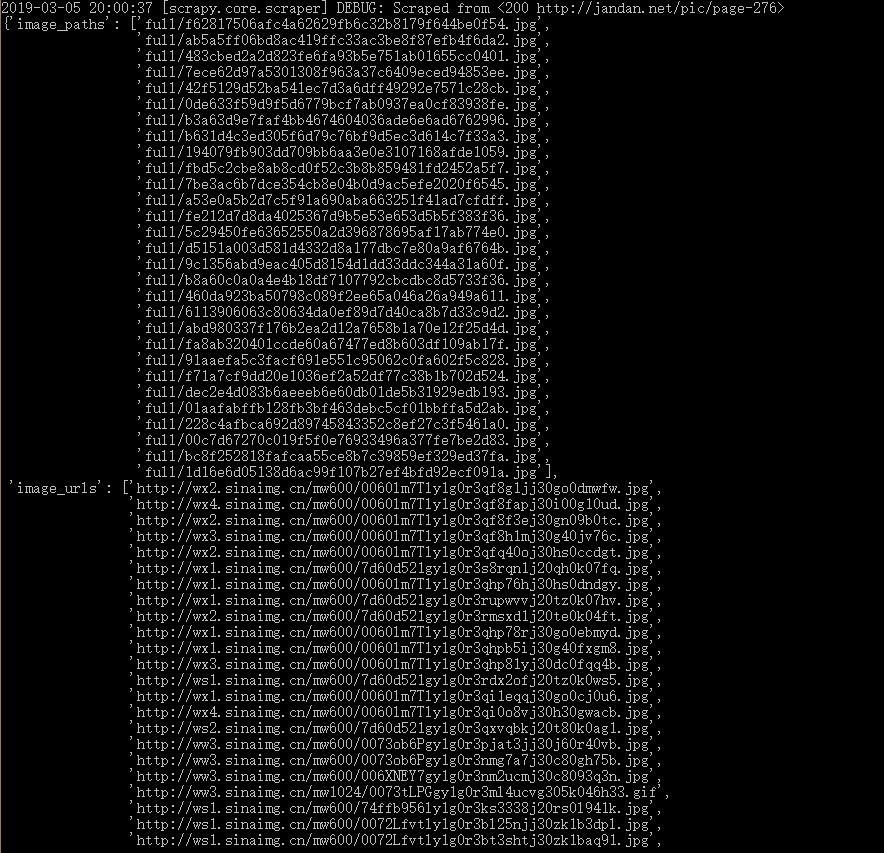
上面为实际运行情况
但是imagepipeline不能下载gif图片
******************************************************************************************************************************
改成filepipeline,更改path,这里传递的只是一个path,name,
def file_path(self, request, response=None, info=None):
path = super().file_path(request, response=None, info=None)
file_store = os.path.join(settings.FILES_STORE,'images')
if not os.path.exists(file_store):
os.mkdir(file_store)
file_name = os.path.join(file_store,path) # file_guid = request.url.split('/')[-1]
# filename = u'full/{0[name]}/{0[albumname]}/{1}'.format(item, file_guid)
return file_name
学习使用scrapy itemspipeline过程的更多相关文章
- 学习 Git的使用过程
原文链接: http://www.cnblogs.com/NickQ/p/8882726.html 学习 Git的使用过程 初次使用 git config --global user.name &qu ...
- linux内核学习之六 进程创建过程学习
一 关于linux进程概念的补充 关于进程的基本概念这里不多说,把自己的学习所得作一些补充: 1. 在linux内核中,系统最多可以有64个进程同时存在. 2.linux进程包含的关键要素:一段可执行 ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- 强化学习-MDP(马尔可夫决策过程)算法原理
1. 前言 前面的强化学习基础知识介绍了强化学习中的一些基本元素和整体概念.今天讲解强化学习里面最最基础的MDP(马尔可夫决策过程). 2. MDP定义 MDP是当前强化学习理论推导的基石,通过这套框 ...
- go微服务框架go-micro深度学习 rpc方法调用过程详解
摘要: 上一篇帖子go微服务框架go-micro深度学习(三) Registry服务的注册和发现详细解释了go-micro是如何做服务注册和发现在,服务端注册server信息,client获取serv ...
- 1.1(java学习笔记) 面向过程与面向对象
面向过程思考时,我们会先思考具体的步骤,第一步走什么,第二步做什么. 比如电脑新建文件夹,第一步:打开电脑 第二步:按下鼠标右键. 第三步:找到新建选项 第四步:点击新建选项下的文件夹 c语言是典型的 ...
- 七天从零基础学习android(3)--实现过程
首先这是我对自己编写程序的认识,要实现一个程序,根据之前编写C++的经验,要对所编写的软件有一个模糊的了解. 一个记账本软件,要实现的过程是,添加收支,显示本日,本月或本年的收支状态.然而基于是完全没 ...
- RocketMQ事务消息学习及刨坑过程
一.背景 MQ组件是系统架构里必不可少的一门利器,设计层面可以降低系统耦合度,高并发场景又可以起到削峰填谷的作用,从单体应用到集群部署方案,再到现在的微服务架构,MQ凭借其优秀的性能和高可靠性,得到了 ...
- USB2.0协议学习笔记---USB工作过程(类的方法)
前面学习了那么多的概念,这里需要记住一点分层概念即设备 ---> 配置 ---> 接口 ---> 端点,这种分层的概念结构 . 也可以理解为端点构成接口,接口组成配置,配置组成设备. ...
随机推荐
- java改单个插入为批量插入
单条insert into table value() 13W数据需要执行7小时 变成inert into table value(),(),(),(),() inert into table val ...
- Linux 环境变量_006
***Linux 环境变量指系统运行程序或命令的能快速找到其位置等其它功能,不用输入复杂命令.以$PATH环境变量为例子, $PATH决定了shell指定寻找命令或程序的路径,比较执行ls命令,如果没 ...
- ThinkPHP 文件上传到阿里云OSS上(干货)
参考:http://www.thinkphp.cn/extend/789.html 1.前往阿里云github下载SDK包:https://github.com/aliyun/aliyun-oss-p ...
- 通过User-agent进行SQL注入
声明:本文由Bypass整理并翻译,仅用于安全研究和学习之用. 文章来源:https://hackerone.com/reports/297478 我发现了一个SQL注入漏洞 /dashboard/d ...
- 安装 RabbitMQ
Ubuntu 16.04 安装 RabbitMQ #1 更新 $ sudo apt-get update $ sudo apt-get upgrade #2 安装Erlang $ cd /tmp $ ...
- ruby 基础知识 - Class 与 Module
原文 1. 因為 Ruby 並沒有「屬性」(property/attribute)這樣的設計,要取用實體變數,需要另外定義的方法才行: class Cat def initialize(name, g ...
- 1、js基础内容
js基础内容 1. 编辑器 编译环境 浏览器 编辑软件 sublime DW H5Build Atom ==[注]尽可能多的去使用编辑器去编辑代码.== Html+css ==JS 逻辑== 比作建设 ...
- java爬取网站信息和url实例
https://blog.csdn.net/weixin_38409425/article/details/78616688(出自此為博主) 具體代碼如下: import java.io.Buffer ...
- 关于js执行机制的理解
js是单线程语言.指的是js的所以程序执行通过仅有的这一个主线程来执行. 但是还有辅助线程,包括定时器线程,ajax请求线程和事件线程. js的异步我理解的是: 主线程执行时候,从上到下依次执行,遇到 ...
- ssm项目中KindEditor的图片上传插件,浏览器兼容性问题
解决办法: 原因:使用@ResponseBody注解返回java对象,在浏览器中是Content-Type:application/json;charset=UTF-8 我们需要返回字符串(Strin ...