EM算法笔记
EM算法在很多地方都用使用到,比如简单的K-means算法,还有在隐马尔可夫里面,也涉及到了EM算法,可见EM算法在机器学习领域的重要地位。在这里就写一下我对于EM算法的一些理解笔记。后续有新的理解也会追加的。
EM算法的全称叫做:期望最大。EM算法的想法很简单,就像一个人有两条腿向前走,你总是需要固定一条腿动另一条腿这样交替往前走。这里面的两条腿,一个是隐变量,一个是参数θ。
在了解EM算法之前,首先需要了解一些基本的概念。
凹凸函数
这个是《最优化》里面的概念,如果它的二阶导大于0,那么就是凸函数;如果是二阶导小于0,那么就是凹函数。(我记得《最优化》数学老师说,高数的定义和最优化的定义是反着的,因为用的概念不一样,高数好像用的是前苏联的定义,最优化是用的欧洲定义。我也不知道是不是真的……)。这样可能不是很容易记住,所以就取两个很有代表性的函数,方便记忆:凸函数:x2,凹函数:−x2。这样,就是你忘记了定义,也很容易通过这两个函数想越来。更重要的是为了方便你理解下面的概念。
Jensen不等式
这个是EM里面,我认为最重要的一个概念,因为它其实是贯穿整个EM的算法里面的。Jensen不等式的概念也很简单,就是如果是凸函数:f(E(x)) < E(f(x));凹函数:f(E(x)) > E(f(x))。这个定义可能一开始没看明白是什么意思,主要问题可能是那个E(x)的期望。换一个简单的说法, 就是如果是凸函数f(x+y2)<f(x)+f(y)2。这里其实是就是把期望这个公式简化成每个变量出现的概率是1/2,然后你把这个画到f(x)=x2里面就一目了然了。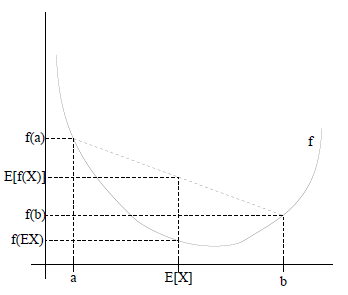
EM算法
给定的训练样本是x(1),...,x(m),我们希望求出最大的概率p(x;θ)。
我们可以求出这个模型的最大似然估计:
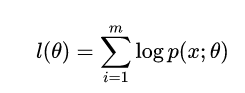
然后取对数:
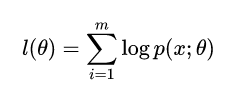
但是,在这个模型里面我们认为p(x;θ)是存在隐变量z的,于是上式改写成
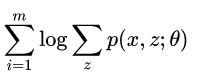
之前求最大似然是很容易,取完对数求导就可以了,但是现在不行,因为有一个隐变量了。那么应该怎么做呢,我们可以固定一个参数,先求另一个参数的最大化,然后再求之前固定的参数。
但是先固定哪个呢,还是随便固定?(这个问题在K-means里面也有,后面再解释。)
这里,我们先观察上面那个式子,直接想出θ是不可能了,因为有z。所以如果想求θ,就一定要固定z。那怎么固定z呢?EM算法就用到了Jensen不等式来估计这个这个z。log是一个凹函数,所以上面那个式子根据不等式是存在一个下界的,那么我们就可以通过下界等式成立的情况来求出最大的z对不对?所以我们可以写出
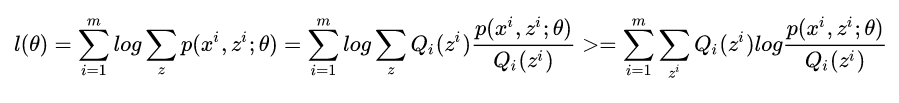
我们可以把jensen的f(x)换log就是上面那个式子了。
EM算法可以写成: 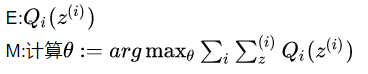
EM推导
EM要解决两个问题,一个是什么时候等式相等;二是为什么一定收敛。
什么时候等式成立呢?
x=E(x)的时候,你带入就会发现两边等式是相等的。因为都是取那一个点,而且概率也一样,所以自然相等。所以就是p(xi,zi;θ)Qi(z(i))=c
然后把Q乘过去,并对所有的z求和,得到:
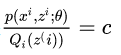
又因为∑zQi(zi)等于1所以∑zp(xi,zi;θ)=c
因此我们可以知道
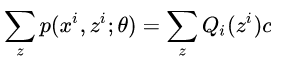
从而EM算法两步可以理解为: 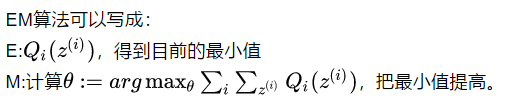
为什么一定收敛?
其实为什么收敛需要解决的一个问题是,是否是单调,如果是单调的话,就可以通过变化幅度来决定。

之所以l(t)<=l(t+1)是因为在M步的时候,θ让公式变大了。所以既然单调,就可以通过变化来证明收敛。
其实这两个问题,也是E与M分别需要解决的问题,E就是让等式成立,而M就是让新状态大于旧状态。
参考资料:
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
http://www.csuldw.com/2015/12/02/2015-12-02-EM-algorithms/
EM算法笔记的更多相关文章
- 读吴恩达算-EM算法笔记
最近感觉对EM算法有一点遗忘,在表述的时候,还是有一点说不清,于是重新去看了这篇<CS229 Lecture notes>笔记. 于是有了这篇小札. 关于Jensen's inequali ...
- 机器学习-EM算法笔记
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域算法的基础,比如隐式马尔科夫算法(HMM), LDA主题模型的变分推断,混合高斯模型 ...
- 学习笔记——EM算法
EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计.EM算法的每次迭代由两步组成:E步,求期望(expectation):M步,求 ...
- 猪猪的机器学习笔记(十四)EM算法
EM算法 作者:樱花猪 摘要: 本文为七月算法(julyedu.com)12月机器学习第十次次课在线笔记.EM算法全称为Expectation Maximization Algorithm,既最大 ...
- GMM高斯混合模型学习笔记(EM算法求解)
提出混合模型主要是为了能更好地近似一些较复杂的样本分布,通过不断添加component个数,能够随意地逼近不论什么连续的概率分布.所以我们觉得不论什么样本分布都能够用混合模型来建模.由于高斯函数具有一 ...
- 《统计学习方法》笔记九 EM算法及其推广
本系列笔记内容参考来源为李航<统计学习方法> EM算法是一种迭代算法,用于含有隐变量的概率模型参数的极大似然估计或极大后验概率估计.迭代由 (1)E步:求期望 (2)M步:求极大 组成,称 ...
- python机器学习笔记:EM算法
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域的基础,比如隐式马尔科夫算法(HMM),LDA主题模型的变分推断算法等等.本文对于E ...
- 统计学习方法笔记--EM算法--三硬币例子补充
本文,意在说明<统计学习方法>第九章EM算法的三硬币例子,公式(9.5-9.6如何而来) 下面是(公式9.5-9.8)的说明, 本人水平有限,怀着分享学习的态度发表此文,欢迎大家批评,交流 ...
- 《统计学习方法》笔记(9):EM算法和隐马尔科夫模型
EM也称期望极大算法(Expectation Maximization),是一种用来对含有隐含变量的概率模型进行极大似然估计的迭代算法.该算法可应用于隐马尔科夫模型的参数估计. 1.含有隐含参数的概率 ...
随机推荐
- [转]Angular 4|5 Material Dialog with Example
本文转自:https://www.techiediaries.com/angular-material-dialogs/ In this tutorial, we're going to learn ...
- asp.net mvc5轻松实现插件式开发
在研究Nopcommece项目代码的时候,发现Nop.Admin是作为独立项目开发的,但是部署的时候却是合在一起的,感觉挺好 这里把他这个部分单独抽离出来, 主要关键点: 确保你的项目是MVC5 而不 ...
- IBatisNet动态update以及DateTime类型字段处理
在维护一个老项目中碰到的问题.SQL配置如下(只简单列出两个字段): <update id="ProjectInfo.Update" parameterClass=" ...
- 【Java深入研究】8、Java中Unsafe类详解
java不能直接访问操作系统底层,而是通过本地方法来访问.Unsafe类提供了硬件级别的原子操作,主要提供了以下功能: 1.通过Unsafe类可以分配内存,可以释放内存: 类中提供的3个本地方法all ...
- MySQL ORDER BY主键id加LIMIT限制走错索引
背景及现象 report_product_sales_data表数据量2800万: 经测试,在当前数据量情况下,order by主键id,limit最大到49的时候可以用到索引report_produ ...
- netty 基础
Netty是一个高性能.异步事件驱动的NIO框架,提供了对TCP.UDP和文件传输的支持,作为一个异步NIO框架,Netty的所有IO操作都是异步非阻塞的,通过Future-Listener机制,用户 ...
- 使用iconv进行编码gb2312转utf8 转码失败的坑
iconv 编码gb2312转utf8 转码失败的坑 使用背景 项目中使用thrift进行C#程序调用c++接口,其中的协议是通过json进行传输的,由于默认thrift使用utf8进行传输,而C#和 ...
- extract-text-webpack-plugin 作用、安装、使用
作用:该插件的主要是为了抽离css样式,防止将样式打包在js中引起页面样式加载错乱的现象 安装:插件安装命令如下: npm install extract-text-webpack-plugin -- ...
- CDQ分治小结
CDQ分治小结 warning:此文仅用博主复习使用,初学者看的话后果自负.. 复习的时候才发现以前根本就没写过这种东西的总结,简单的扯一扯 cdq分治的经典应用就是解决偏序问题 比如最经典的三维偏序 ...
- tfs 禁止多人签出
好久没用tfs了,忘了怎么设置了,记录下 编辑----->高级