sklearn 可视化模型的训练测试收敛情况和特征重要性
show the code:
# Plot training deviance
def plot_training_deviance(clf, n_estimators, X_test, y_test):
# compute test set deviance
test_score = np.zeros((n_estimators,), dtype=np.float64)
for i, y_pred in enumerate(clf.staged_predict(X_test)):
test_score[i] = clf.loss_(y_test, y_pred)
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title('Deviance')
train_score = clf.train_score_
logging.info("len(train_score): %s" % len(train_score))
logging.info(train_score)
logging.info("len(test_score): %s" % len(test_score))
logging.info(test_score)
plt.plot(np.arange(n_estimators) + 1, train_score, 'b-',
label='Training Set Deviance')
plt.plot(np.arange(n_estimators) + 1, test_score, 'r*', label='Test Set Deviance')
plt.legend(loc='upper right')
plt.xlabel('Boosting Iterations')
plt.ylabel('Deviance')
plt.show() # Plot feature importance
def plot_feature_importance(clf, feature_names):
feature_importance = clf.feature_importances_
# make importances relative to max importance
feature_importance = 100.0 * (feature_importance / feature_importance.max())
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + .5
plt.subplot(1, 2, 2)
plt.barh(pos, feature_importance[sorted_idx], align='center')
# plt.yticks(pos, feature_names[sorted_idx])
plt.yticks(pos, [feature_names[idx] for idx in sorted_idx])
plt.xlabel('Relative Importance')
plt.title('Variable Importance')
plt.show() class Train(object):
def __init__(self, data_file):
self.data_file = data_file
self.x_fields = ["xxx", "xxx", "xxx"]
self.x_features, self.y_labels = self.load_data() def load_data(self):
x_features, y_labels = [], []
# ......
return x_features, y_labels def train_model(self):
model = GradientBoostingRegressor(random_state=42)
model.fit(self.x_features, self.y_labels)
y_pred = model.predict(self.x_features)
logging.info("mean_squared_error: %.6f" % mean_squared_error(self.y_labels, y_pred))
logging.info("mean_squared_log_error: %.6f" % mean_squared_log_error(self.y_labels, y_pred)) plot_training_deviance(clf=model, n_estimators=model.get_params()["n_estimators"], X_test=self.x_features, y_test=self.y_labels) # 输出feature重要性
logging.info("feature_importances_: %s" % model.feature_importances_)
plot_feature_importance(clf=model, feature_names=self.x_fields)
参考的是sklearn中的样例: Gradient Boosting regression — scikit-learn 0.19.2 documentation
画出的图如下所示:
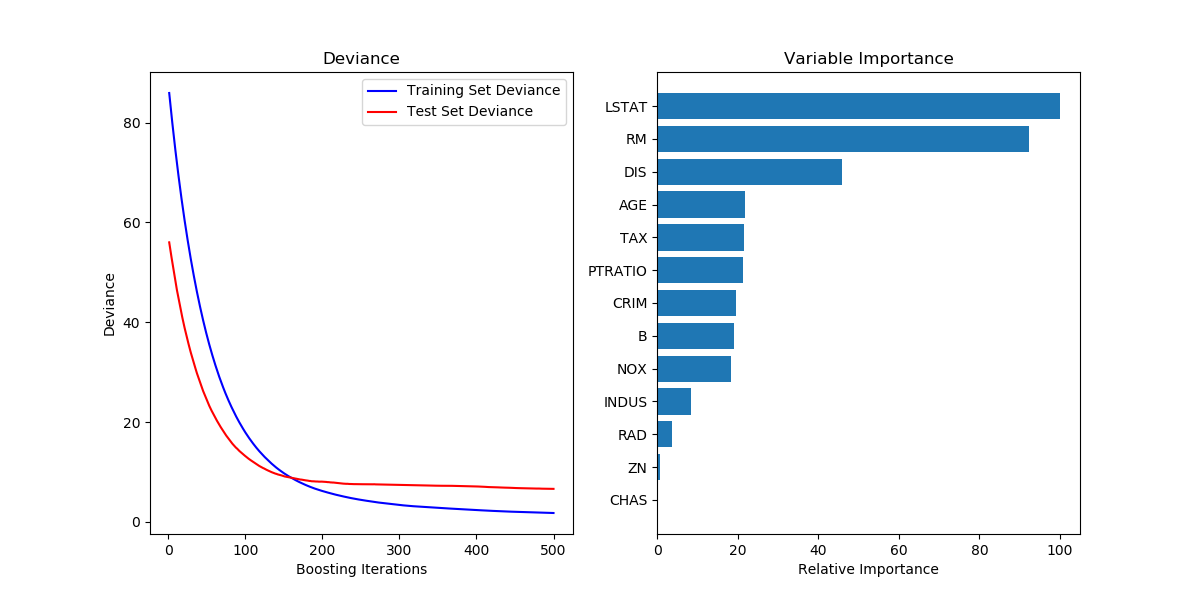
sklearn 可视化模型的训练测试收敛情况和特征重要性的更多相关文章
- 【集成学习】sklearn中xgboost模块中plot_importance函数(绘图--特征重要性)
直接上代码,简单 # -*- coding: utf-8 -*- """ ################################################ ...
- 使用 TensorBoard 可视化模型、数据和训练
使用 TensorBoard 可视化模型.数据和训练 在 60 Minutes Blitz 中,我们展示了如何加载数据,并把数据送到我们继承 nn.Module 类的模型,在训练数据上训练模型,并在测 ...
- sklearn——train_test_split 随机划分训练集和测试集
sklearn——train_test_split 随机划分训练集和测试集 sklearn.model_selection.train_test_split随机划分训练集和测试集 官网文档:http: ...
- 机器学习使用sklearn进行模型训练、预测和评价
cross_val_score(model_name, x_samples, y_labels, cv=k) 作用:验证某个模型在某个训练集上的稳定性,输出k个预测精度. K折交叉验证(k-fold) ...
- pytorch seq2seq模型训练测试
num_sequence.py """ 数字序列化方法 """ class NumSequence: """ ...
- 学习笔记TF016:CNN实现、数据集、TFRecord、加载图像、模型、训练、调试
AlexNet(Alex Krizhevsky,ILSVRC2012冠军)适合做图像分类.层自左向右.自上向下读取,关联层分为一组,高度.宽度减小,深度增加.深度增加减少网络计算量. 训练模型数据集 ...
- Python 3 利用 Dlib 19.7 和 sklearn机器学习模型 实现人脸微笑检测
0.引言 利用机器学习的方法训练微笑检测模型,给一张人脸照片,判断是否微笑: 使用的数据集中69张没笑脸,65张有笑脸,训练结果识别精度在95%附近: 效果: 图1 示例效果 工程利用pytho ...
- sklearn保存模型的两种方式
sklearn 中模型保存的两种方法 一. sklearn中提供了高效的模型持久化模块joblib,将模型保存至硬盘. from sklearn.externals import joblib # ...
- sklearn保存模型-【老鱼学sklearn】
训练好了一个Model 以后总需要保存和再次预测, 所以保存和读取我们的sklearn model也是同样重要的一步. 比如,我们根据房源样本数据训练了一下房价模型,当用户输入自己的房子后,我们就需要 ...
随机推荐
- vue学习之一vue初识
一.vue.js是什么 Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架.与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用.Vue 的核心库只关注视图层 ...
- google浏览器插件安装
1:安装本地插件,直接将下载好的crx插件拖入到 chrome://extensions/ 的空白处 http://www.cnplugins.com/tool/outline-instal ...
- 2.2 The Object Model -- Reopening Classes and Instances
1. 你不需要一开始定义一个类的全部内容,你可以通过使用reopen方法重新打开一个类并定义新的属性. Person.reopen({ isPerson: true }); Person.create ...
- (16)Cocos2d-x 多分辨率适配完全解析
Overview 从Cocos2d-x 2.0.4开始,Cocos2d-x提出了自己的多分辨率支持方案,废弃了之前的retina相关设置接口,提出了design resolution概念. 3.0中有 ...
- 安装memcached扩展 验证过了可行
. 安装libmemached 复制代码 代码如下: wget https://launchpad.net/libmemcached/1.0/1.0.16/+download/libmemcached ...
- 去掉每行最后n个字符
awk '{sub(/.{n}$/,"")}1' nation.tbl > nation.tbl2 把n替换成具体长度
- source insight 4.0的基本使用方法(转)
源:source insight 4.0的基本使用方法 source insight 4设置
- web实现负载均衡的几种实现方式
摘要: 负载均衡(Load Balance)是集群技术(Cluster)的一种应用.负载均衡可以将工作任务分摊到多个处理单元,从而提高并发处理能力.目前最常见的负载均衡应用是Web负载均衡.根据实现的 ...
- 20145325张梓靖 《Java程序设计》第6周学习总结
20145325张梓靖 <Java程序设计>第6周学习总结 教材学习内容总结 串流设计 输入串流(将数据从来源取出),代表对象为java.io.InputStream实例,输出串流(将数据 ...
- Python3基础 print %d 输出整数
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...