hdfs调优
本文章来自 hackershell.cn,转载请标注出处
描述
这篇文章主要从一些配置设置相关方面去调优Hadoop集群的笔记,内容来自网上或一些实践经验
1.HDFS审计日志
HDFS审计日志是一个和进程分离的日志文件,默认是没有开启的,开启之后,用户的每个请求都会记录到审计日志当中,通过审计日志可以发现哪些ip,哪些用户对哪些目录做了哪些操作,比如:那些数据在哪些在什么时候删除,和分析哪些Job在密集的对NameNode进行访问,我们自己的版本中对访问记录了job的Id,在新版的HDFS中,新增加了callcontext的功能,也做了类似操作:HDFS-9184 Logging HDFS operation’s caller context into audit logs.
如何开启,修改Hadoop-env.sh
-Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender}改为
-Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,RFAAUDIT}对应的log4j.properties可以新增保存个数
#
# hdfs audit logging
#
hdfs.audit.logger=INFO,NullAppender
hdfs.audit.log.maxfilesize=2560MB
hdfs.audit.log.maxbackupindex=30
log4j.logger.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=${hdfs.audit.logger}
log4j.additivity.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=false
log4j.appender.RFAAUDIT=org.apache.log4j.RollingFileAppender
log4j.appender.RFAAUDIT.File=/data1/hadoop-audit-logs/hdfs-audit.log
log4j.appender.RFAAUDIT.layout=org.apache.log4j.PatternLayout
log4j.appender.RFAAUDIT.layout.ConversionPattern=[%d{yyyy-MM-dd'T'HH:mm:ss.SSSXXX}] [%p] %c{3}.%M(%F %L) [%t] : %m%n
log4j.appender.RFAAUDIT.MaxFileSize=${hdfs.audit.log.maxfilesize}
log4j.appender.RFAAUDIT.MaxBackupIndex=${hdfs.audit.log.maxbackupindex}开启异步的审计日志
使用异步的log4j appender可以提升NameNode的性能,尤其是请求量在10000 requests/second,可以设置hdfs-site.xml
<property>
<name>dfs.namenode.audit.log.async</name>
<value>true</value>
</property>2.开启Service RPC端口
在默认情况下,service RPC端口是没有使用的,client和DataNode汇报,zkfc的健康检查都会公用RPC Server,当client的请求量比较大或者DataNode的汇报量很大,会导致他们之间相互影响,导致访问非常缓慢,开启之后,DN的汇报和健康检查请求都会走Service RPC端口,避免了因为client的大量访问影响,影响服务之间的请求,在HA集群中,可以在hdfs-site.xml中设置
<property>
<name>dfs.namenode.servicerpc-address.mycluster.nn1</name>
<value>mynamenode1.example.com:8021</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.mycluster.nn2</name>
<value>mynamenode2.example.com:8021</value>
</property>开启之后,需要重置zkfc
hdfs zkfc –formatZK注意:
修改这个端口需要重启集群,请自行评估带来的影响
3.关闭多余的日志
有时候,NameNode上日志打印会严重影响NN的性能,出问题时也会造成没必要的干扰,所以可以修改log4j的文件,对没必要的日志进行日志级别的调整,例如
log4j.logger.BlockStateChange=WARN
log4j.logger.org.apache.hadoop.ipc.Server=WARN社区上也有很多日志的优化方案
- HDFS-9434
- HADOOP-12903
- HDFS-9941
- HDFS-9906
4.RPC FairCallQueue
这个是基于上面第二点开启Service RPC继续说的,这是较新版本的Hadoop的新特性,RPC FairCallQueue替换了之前的单一的RPC queue的模式,RPC Server会维护并按照请求的用户进行分组,Handler会按照队列的优先级去消费queue里面的RPC Call,这个功能它可以防止因为某个用户的cleint的大量请求导致NN无法响应,整个集群瘫痪的状态,开启了之后,请求多的用户请求会被降级,这样不会造成多租户下,影响他用户的访问,后续会有文章介绍,相关的JIRA HDFS-10282
如果开启,需要修改core-site.xml
<property>
<name>ipc.8020.callqueue.impl</name>
<value>org.apache.hadoop.ipc.FairCallQueue</value>
</property>
<property>
<name>ipc.8020.faircallqueue.decay-scheduler.period-ms</name>
<value>60000</value>
</property>注意
不能对DataNode和NN通信的端口进行开启
5.磁盘吞吐量
对于NameNode来说,HDFS NameNode性能也依赖于flush edit logs到磁盘的速度,任何延迟将会导致将会影响RPC的处理线程,并对Hadoop集群造成连锁的性能影响。
你应该使用专用的硬盘时存储edit logs,如果hdfs-site.xml中没有配置,将等于dfs.name.name.dir的值
<property>
<name>dfs.namenode.name.dir</name>
<value>/mnt/disk1,/mnt/disk2</value>
</property>对于DN来说,默认的Du,会产生大量的du -sk的操作,会造成集群严重的IO Wait增加,从而导致任务会变得缓慢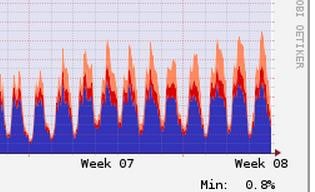
负载图
产生大量的DU操作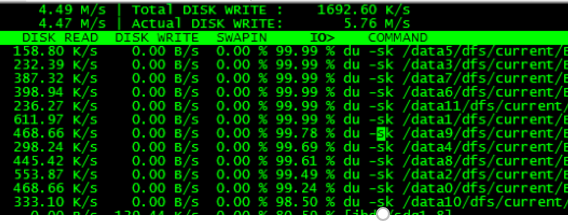
解决方案是
将同时产生的du操作,加个随机数,随机到集群的不同时间段,并且每天只du一次,这样虽然可能会造成hdfs上显示的使用率会有延时,但基本可以满足要求HADOOP-9884
打patch之后,修改hdfs-site.xml
<property>
<name>fs.getspaceused.jitterMillis</name>
<value>3600000</value>
</property>
<property>
<name>fs.du.interval</name>
<value>86400000</value>
</property>
<property>
<name>dfs.datanode.cached-dfsused.check.interval.ms</name>
<value>14400000</value>
</property>6.避免读取stale DataNodes
修改hdfs-site.xml
dfs.namenode.avoid.read.stale.datanode=true
dfs.namenode.avoid.write.stale.datanode=true7.开启short circuit reads
开启短路读之后,当client读取数据时,如果在改节点,会直接通过文件描述符去读取文件,而不用通过tcp socket的方式
修改hdfs-site.xml
dfs.client.read.shortcircuit=true
dfs.domain.socket.path=/var/lib/hadoop-hdfs/dn_socket8.关闭操作系统的Transparent Huge Pages (THP)
操作系统默认开启THP,会导致整个Hadoop集群cpu sys态变高,详细步骤可以参考
9.设置系统的vm.swappiness
避免使用交换区
添加vm.swappiness=0到/etc/sysctl.conf重启生效,或者sysctl -w vm.swappiness=0
10.设置系统CPU为performance
设置cpu的scaling governors为performance模式,你可以运行cpufreq-set -r -g performance或者修改/sys/devices/system/cpu/cpu*/cpufreq/scaling_governor文件,并设置为performance
参考文章
https://support.huawei.com/enterprise/en/doc/EDOC1100043056/ddc366b3/optimizing-hdfs-namenode-rpc-qos
OS Configurations for Better Hadoop Performance
hdfs调优的更多相关文章
- HBase 中读 HDFS 调优
HDFS Read调优 在基于 HDFS 存储的 HBase 中,主要有两种调优方式: 绕过RPC的选项,称为short circuit reads 开启让HDFS推测性地从多个datanode读数据 ...
- hadoop 性能调优与运维
hadoop 性能调优与运维 . 硬件选择 . 操作系统调优与jvm调优 . hadoop运维 硬件选择 1) hadoop运行环境 2) 原则一: 主节点可靠性要好于从节点 原则二:多路多核,高频 ...
- 【HBase调优】Hbase万亿级存储性能优化总结
背景:HBase主集群在生产环境已稳定运行有1年半时间,最大的单表region数已达7200多个,每天新增入库量就有百亿条,对HBase的认识经历了懵懂到熟的过程.为了应对业务数据的压力,HBase入 ...
- Hadoop、Hbase基本命令及调优方式
HDFS基本命令 接触大数据挺长时间了,项目刚刚上完线,趁着空闲时间整理下大数据hadoop.Hbase等常用命令以及各自的优化方式,当做是一个学习笔记吧. HDFS命令基本格式:Hadoop fs ...
- CM记录-Hadoop参数调优
1.HDFS调优 a.设置合理的块大小(dfs.block.size) b.将中间结果目录设置为分布在多个磁盘以提升写入速度(mapred.local.dir) c.设置DataNode处理RPC的线 ...
- hdfs性能调优(cloudera)
参照官方文档:http://www.cloudera.com/content/cloudera/en/documentation/core/latest/topics/cdh_ig_yarn_tuni ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- spark参数调优
摘要 1.num-executors 2.executor-memory 3.executor-cores 4.driver-memory 5.spark.default.parallelism 6. ...
- Spark调优
因为Spark是内存当中的计算框架,集群中的任何资源都会让它处于瓶颈,CPU.内存.网络带宽.通常,内存足够的情况之下,网络带宽是瓶颈,这时我们就需要进行一些调优,比如用一种序列化的方式来存储RDD来 ...
随机推荐
- router基本使用
摘自:https://blog.csdn.net/qq_39894133/article/details/78992923 1.vue2 路由的使用流程: 1.vue2中的路由定义层:<rout ...
- 20145122 《Java程序设计》第4周学习总结
教材学习内容总结 第六章 1.在java中,子类只能继承一个父类. 2.在java中,继承时使用extends关键字,private成员也会被继承. 3.检查多态语法逻辑是否正确,方式是从=号右边往左 ...
- JAVA实验一20145315
JAVA实验一实验报告 实验名称 Java开发环境的熟悉 实验内容 1.使用JDK编译.运行简单的Java程序: 2.使用IDEA 编辑.编译.运行.调试Java程序. 实验知识点 JVM.JRE.J ...
- 在linux上安装Drupal
前言:国内用drupal的并不太多,网上资料也很少.要注意的是drupal尽量别使用apt来安装,特别是ubuntu平台的drupal做出了一定的更改,会妨碍后期的学习和使用.在安装drupal前要先 ...
- linux下如何使用split
答: 切割文件hello,以每个文件最大10MiB来切割,切割好的文件名前缀为hello.,后缀为二位的数字,切割之后的名字为hello.01,hello.02等等 split -b 10M - ...
- ACM赛前准备——模板(排版篇)
ACM赛前准备--模板(排版篇) 更新 前言 效果演示 封面 目录页 模板页(不分栏) 模板页(分栏) 结果文件 快速使用 准备工作 安装TexLive (可选)安装minted包 创建模板 文件结构 ...
- Gym - 100676H H. Capital City (边双连通分量缩点+树的直径)
https://vjudge.net/problem/Gym-100676H 题意: 给出一个n个城市,城市之间有距离为w的边,现在要选一个中心城市,使得该城市到其余城市的最大距离最短.如果有一些城市 ...
- Observer(观察者)
意图: 定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时, 所有依赖于它的对象都得到通知并被自动更新. 适用性: 当一个抽象模型有两个方面, 其中一个方面依赖于另一方面.将这二者封装在独立 ...
- 强大的XML
2018-04-23 20:29:26 XML:Extensible Markup Language,也就是可扩展标记语言.XML和HTML格式是古老的标记通用语言SGML的衍生语言. XML文件是可 ...
- Linux 最好是禁用IPV6
看着不爽, 还容易出事. 编辑文件 – /etc/sysctl.conf $ sudo gedit /etc/sysctl.conf 在文件的最后加入下面的行. # IPv6 disabled net ...