机器学习-ID3决策树算法(附matlab/octave代码)
ID3决策树算法是基于信息增益来构建的,信息增益可以由训练集的信息熵算得,这里举一个简单的例子
data=[心情好 天气好 出门
心情好 天气不好 出门
心情不好 天气好 出门
心情不好 天气不好 不出门]
前面两列是分类属性,最后一列是分类
分类的信息熵可以计算得到:
出门=3,不出门=1,总行数=4
分类信息熵 = -(3/4)*log2(3/4)-(1/4)*log2(1/4)
第一列属性有两类,心情好,心情不好
心情好 ,出门=2,不出门=0,行数=2
心情好信息熵=-(2/2)*log2(2/2)+(0/2)*log2(0/2)
同理
心情不好信息熵=-(1/2)*log2(1/2)-(1/2)*log2(1/2)
心情的信息增益=分类信息熵 - 心情好的概率*心情好的信息熵 - 心情不好的概率*心情不好的信息熵
由此可以得到每个属性对应的信息熵,信息熵最大的即为最优划分属性。
还是这个例子,加入最优划分属性为心情
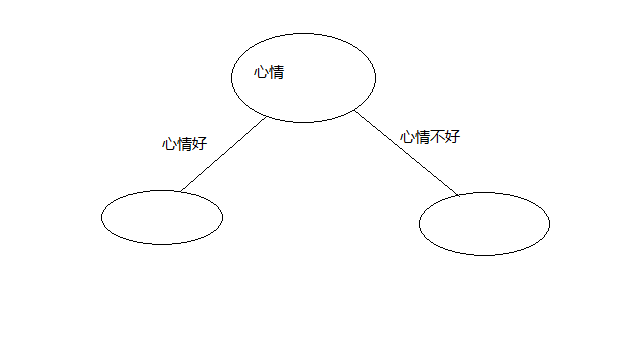
然后分别在心情属性的每个具体情况下的分类是否全部为同一种,若为同一种则该节点标记为此类别,
这里我们在心情好的情况下不管什么天气结果都是出门所以,有了
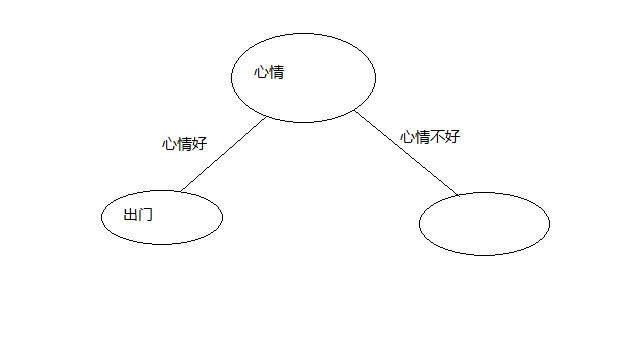
心情不好的情况下有不同的分类结果,继续计算在心情不好的情况下,其它属性的信息增益,
把信息增益最大的属性作为这个分支节点,这个我们只有天气这个属性,那么这个节点就是天气了,
天气属性有两种情况,如下图
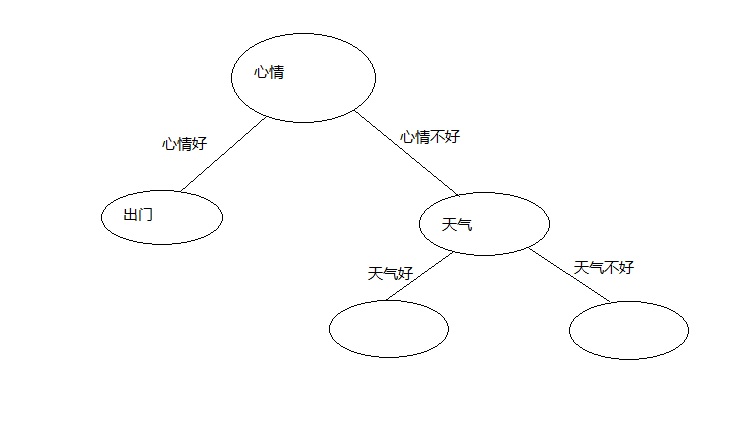
在心情不好并且天气好的情况下,若分类全为同一种,则改节点标记为此类别
有训练集可以,心情不好并且天气好为出门,心情不好并且天气不好为不出门,结果入下图
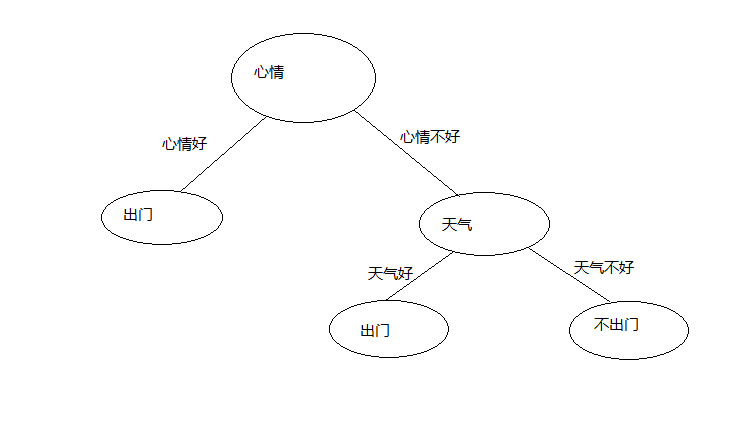
对于分支节点下的属性很有可能没有数据,比如,我们假设训练集变成
data=[心情好 晴天 出门
心情好 阴天 出门
心情好 雨天 出门
心情好 雾天 出门
心情不好 晴天 出门
心情不好 雨天 不出门
心情不好 阴天 不出门]
如下图:

在心情不好的情况下,天气中并没有雾天,我们如何判断雾天到底是否出门呢?我们可以采用该样本最多的分类作为该分类,
这里天气不好的情况下,我们出门=1,不出门=2,那么这里将不出门,作为雾天的分类结果
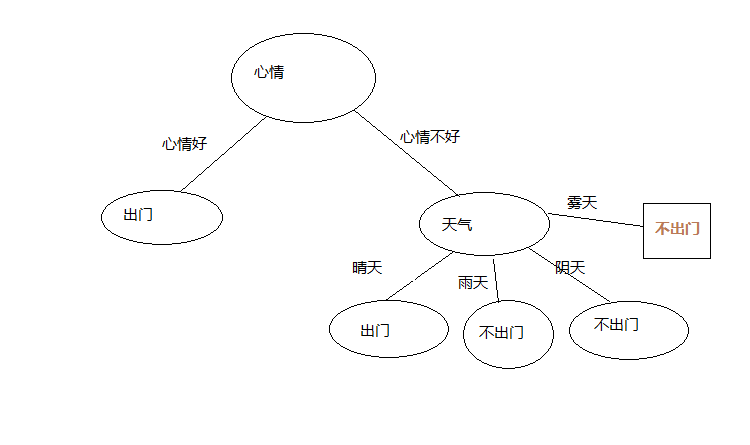
在此我们所有属性都划分了,结束递归,我们得到了一颗非常简单的决策树。
下面附上我的实现ID3决策树算法代码:(octave/matlab,该程序本人已经验证过可以执行且结果正确,这里属性集我偷了一个懒,
没有标识出具体属性名,我是使用矩阵中的列号)
著名的还有C4.5决策树算法,它是ID3的改进,作者都是同一个人,罗斯昆兰
%生成决策树ID3算法
%data:训练集
%feature:属性集
function [node] =createTree(data,feature)
type=mostType(data);
[m,n]=size(data);
%生成节点node
%value:分类结果,若为null则表示该节点是分支节点
%name:节点划分属性
%type:节点属性值
%children:子节点
node=struct('value','null','name','null','type','null','children',[]);
temp_type=data(1,n);
temp_b=true;
for i=1:m
if temp_type!=data(i,n)
temp_b=false;
end
end
%样本中全为同一分类结果,则node节点为叶子节点
if temp_b==true
node.value=data(1,n);
return;
end
%属性集合为空,将结果标记为样本中最多的分类
if sum(feature)==0
node.value=type;
return;
end
feature_bestColumn=bestFeature(data);
best_feature=getData()(:,feature_bestColumn);
best_distinct=unique(best_feature);
best_num=length(best_distinct);
best_proc=zeros(best_num,2);
best_proc(:,1)=best_distinct(:,1);
%循环该属性的每一个值
for i=1:best_num
Dv=[];
Dv_index=1;
%为node创建一个bach_node分支,设样本data中改属性值为best_proc(i,1)的集合为Dv
bach_node=struct('value','null','name','null','type','null','children',[]);
for j=1:m
if best_proc(i,1)==data(j,feature_bestColumn)
Dv(Dv_index,:)=data(j,:);
Dv_index=Dv_index+1;
end
end
%Dv为空则将结果标记为样本中最多的分类
if length(Dv)==0
bach_node.value=type;
bach_node.type=best_proc(i,1);
bach_node.name=feature_bestColumn;
node.children(i)=bach_node;
return;
else
feature(feature_bestColumn)=0;
%递归调用createTree方法
bach_node=createTree(Dv,feature);
bach_node.type=best_proc(i,1);
bach_node.name=feature_bestColumn;
node.children(i)=bach_node;
end
end
end %获取最优划分属性
function [column] = bestFeature(data)
[m,n]=size(data);
featureSize=n-1;
gain_proc=zeros(featureSize,2);
entropy=getEntropy(data);
for i=1:featureSize
gain_proc(i,1)=i;
gain_proc(i,2)=getGain(entropy,data,i);
end
for i=1:featureSize
if gain_proc(i,2)==max(gain_proc(:,2))
column=i;
break;
end
end
end %计算样本最多的结果
function [res] = mostType(data)
[m,n]=size(data);
res_distinct = unique(data(:,n));
res_proc = zeros(length(res_distinct),2);
res_proc(:,1)=res_distinct(:,1);
for i=1:length(res_distinct)
for j=1:m
if res_proc(i,1)==data(j,n)
res_proc(i,2)=res_proc(i,2)+1;
end
end
end
for i=1:length(res_distinct)
if res_proc(i,2)==max(res_proc(:,2))
res=res_proc(i,1);
break;
end
end
end %计算信息熵
function [entropy] = getEntropy(data)
entropy=0;
[m,n]=size(data);
label=data(:,n);
label_distinct=unique(label);
label_num=length(label_distinct);
proc=zeros(label_num,2);
proc(:,1)=label_distinct(:,1);
for i=1:label_num
for j=1:m
if proc(i,1)==data(j,n)
proc(i,2)=proc(i,2)+1;
end
end
proc(i,2)=proc(i,2)/m;
end
for i=1:label_num
entropy=entropy-proc(i,2)*log2(proc(i,2));
end
end %计算信息增益
function [gain] = getGain(entropy,data,column)
[m,n]=size(data);
feature=data(:,column);
feature_distinct=unique(feature);
feature_num=length(feature_distinct);
feature_proc=zeros(feature_num,2);
feature_proc(:,1)=feature_distinct(:,1);
f_entropy=0;
for i=1:feature_num
feature_data=[];
feature_proc(:,2)=0;
feature_row=1;
for j=1:m
if feature_proc(i,1)==data(j,column)
feature_proc(i,2)=feature_proc(i,2)+1;
end
if feature_distinct(i,1)==data(j,column)
feature_data(feature_row,:)=data(j,:);
feature_row=feature_row+1;
end
end
f_entropy=f_entropy+feature_proc(i,2)/m*getEntropy(feature_data);
end
gain=entropy-f_entropy;
机器学习-ID3决策树算法(附matlab/octave代码)的更多相关文章
- day-8 python自带库实现ID3决策树算法
前一天,我们基于sklearn科学库实现了ID3的决策树程序,本文将基于python自带库实现ID3决策树算法. 一.代码涉及基本知识 1. 为了绘图方便,引入了一个第三方treePlotter模块进 ...
- python机器学习笔记 ID3决策树算法实战
前面学习了决策树的算法原理,这里继续对代码进行深入学习,并掌握ID3的算法实践过程. ID3算法是一种贪心算法,用来构造决策树,ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性 ...
- ID3决策树算法原理及C++实现(其中代码转自别人的博客)
分类是数据挖掘中十分重要的组成部分.分类作为一种无监督学习方式被广泛的使用. 之前关于"数据挖掘中十大经典算法"中,基于ID3核心思想的分类算法C4.5榜上有名.所以不难看出ID3 ...
- 就是要你明白机器学习系列--决策树算法之悲观剪枝算法(PEP)
前言 在机器学习经典算法中,决策树算法的重要性想必大家都是知道的.不管是ID3算法还是比如C4.5算法等等,都面临一个问题,就是通过直接生成的完全决策树对于训练样本来说是“过度拟合”的,说白了是太精确 ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
- ID3决策树算法实现(Python版)
# -*- coding:utf-8 -*- from numpy import * import numpy as np import pandas as pd from math import l ...
- 机器学习回顾篇(7):决策树算法(ID3、C4.5)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 建模分析之机器学习算法(附python&R代码)
0序 随着移动互联和大数据的拓展越发觉得算法以及模型在设计和开发中的重要性.不管是现在接触比较多的安全产品还是大互联网公司经常提到的人工智能产品(甚至人类2045的的智能拐点时代).都基于算法及建模来 ...
- 决策树算法——ID3
决策树算法是一种有监督的分类学习算法.利用经验数据建立最优分类树,再用分类树预测未知数据. 例子:利用学生上课与作业状态预测考试成绩. 上述例子包含两个可以观测的属性:上课是否认真,作业是否认真,并以 ...
随机推荐
- Swift - WebKit示例解读
如果你曾经在你的App中使用UIWebView加载网页内容的话,你应该体会到了它的诸多不尽人意之处.UIWebView是基于移动版的Safari的,所以它的性能表现十分有限.特别是在对几乎每个Web应 ...
- Thrift Expected protocol id ffffff82 but got 0
如果服务端配的也是noblock=false;客户端不能改成noblock=true;
- #cat ora11g_ora_.trc
Trace file /u02/app/diag/rdbms/ora11g/ora11g/trace/ora11g_ora_31212.trc Oracle Database 11g Enterpri ...
- Linux系统下 Supervisor 安装搭建
在 web 应用部署到线上后,需要保证应用一直处于运行状态,在遇到程序异常.报错等情况,导致 web 应用终止时,需要保证程序可以立刻重启,继续提供服务. 所以,就需要一个工具,时刻监控 web 应用 ...
- 转!idea 破解版 安装
原博文地址:https://blog.csdn.net/everest_man/article/details/78985879 1.官网下载 Ultimate版本 2.http://idea.la ...
- RPN网络
Region Proposal Network RPN的实现方式:在conv5-3的卷积feature map上用一个n*n的sliding window(论文中n=3)生成一个长度为256(ZF网络 ...
- How many ways??---hdu2157(矩阵快速幂)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2157 题意:有一个有向图,含有n个节点,m条边,Q个询问,每个询问有 s,t,p,求 s 到 t ...
- 修改hosts搭建本地站点
想要搭建本地站点.例如想要将www.nbb.com映射到本地服务器,而不是网络的.需要修改hosts文件 1 打开hosts所在目录 C:\Windows\System32\drivers\etc ...
- linux IO多路复用POLL机制深入分析
POLL机制的作用这里就不进行介绍,根据linux man手册,解释为在一个文件描述符上等待某个事件.按照抽象一点的理解,当某个事件被触发(条件被满足),文件描述符变为有状态,那么用户空间可以根据此进 ...
- YOGA Tablet 2 1371f 触屏失效,无声卡,蓝牙键盘都无法使用的解决办法
安装驱动! 下载地址 http://www.lenovocare.com.cn/Handler/Download.ashx?fileid=1234 安装后电源管理,声卡,触摸屏即可使用! 蓝牙键盘连接 ...