平衡二叉树、B树、B+树、B*树、LSM树简介
平衡二叉树是基于分治思想采用二分法的策略提高数据查找速度的二叉树结构。非叶子结点最多只能有两个子结点,且左边子结点点小于当前结点值,右边子结点大于当前结点树,并且为保证查询性能增增删结点时要保证左右两边结点层级相差不大于1,具体实现有AVL、Treap、红黑树等。Java中TreeMap就是基于红黑树实现的。
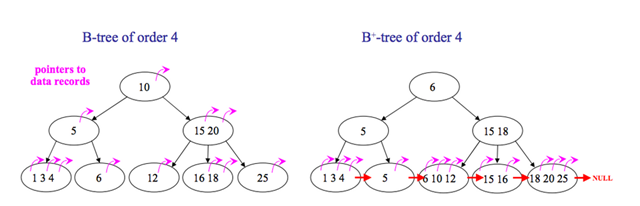
B树与平衡二叉树区别是它是平衡多路查找树,它每个节点包含的关键字增多了,在应用时可利用磁盘块的原理把结点大小限制在磁盘大小范围内从而优化读写速度,同时树的关键字增多后层级比原理的二叉树少量,减少了数据查找次数和复杂度。
B+树是B树基础上为了更充分的利用结点空间,让遍历查询速度更稳定而扩展的结构,它规定只在叶子节点存数据,非叶子结点只存索引,且叶子结点用一个链表连接起来。
(1)B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,这样使得B+树每个节点所能保存的关键字大大增加;
(2)B+树叶子节点保存了父节点的所有关键字和关键字记录的指针,每个叶子节点的关键字从小到大链接;
(3)B+树的根节点关键字数量和其子节点个数相等;
(4)B+的非叶子节点只进行数据索引,不会存实际的关键字记录的指针,所有数据地址必须要到叶子节点才能获取到,所以每次数据查询的次数都一样;
在B树的基础上每个节点存储的关键字数更多,树的层级更少所以查询数据更快,所有指关键字指针都存在叶子节点,所以每次查找的次数都相同所以查询速度更稳定;
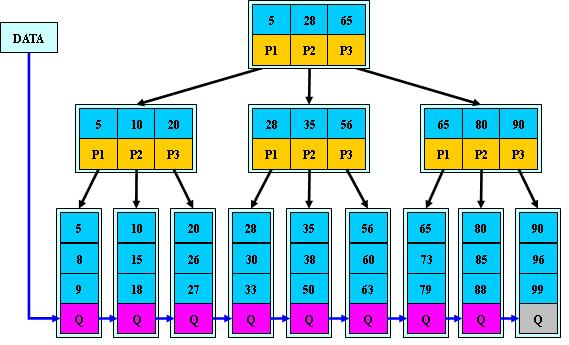
B*树是在B+基础上给非根非叶子结点增加指向兄弟结点的指针,因此可以向兄弟结点转移关键字使其分解次数变得更少。
https://zhuanlan.zhihu.com/p/27700617
LSM树是内存中完成增、删、改操作从而写性能更高,使用索引修改比读更频繁的场景。
https://blog.csdn.net/u010853261/article/details/78217823
为什么说B+tree比B树更适合实际应用中操作系统的文件索引和数据库索引?
(1) B+tree的磁盘读写代价更低
B+tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
(2)B+tree的查询效率更加稳定
由于非叶子结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。(3)B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
LSM树
目前常见的主要的三种存储引擎是:哈希、B+树、LSM树:
- 哈希存储引擎:是哈希表的持久化实现,支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统。对于key-value的插入以及查询,哈希表的复杂度都是O(1),明显比树的操作O(n)快,如果不需要有序的遍历数据,哈希表性能最好。
- B+树存储引擎是B+树的持久化实现,不仅支持单条记录的增、删、读、改操作,还支持顺序扫描(B+树的叶子节点之间的指针),对应的存储系统就是关系数据库(Mysql等)。
- LSM树(Log-Structured MergeTree)存储引擎和B+树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
上面三种引擎中,LSM树存储引擎的代表数据库就是HBase.
LSM树核心思想的核心就是放弃部分读能力,换取写入的最大化能力。LSM Tree ,这个概念就是结构化合并树的意思,它的核心思路其实非常简单,就是假定内存足够大,因此不需要每次有数据更新就必须将数据写入到磁盘中,而可以先将最新的数据驻留在内存中,等到积累到足够多之后,再使用归并排序的方式将内存内的数据合并追加到磁盘队尾(因为所有待排序的树都是有序的,可以通过合并排序的方式快速合并到一起)。
日志结构的合并树(LSM-tree)是一种基于硬盘的数据结构,与B+tree相比,能显著地减少硬盘磁盘臂的开销,并能在较长的时间提供对文件的高速插入(删除)。然而LSM-tree在某些情况下,特别是在查询需要快速响应时性能不佳。通常LSM-tree适用于索引插入比检索更频繁的应用系统。
LSM树和B+树的差异主要在于读性能和写性能进行权衡。在牺牲的同时寻找其余补救方案:
(a)LSM具有批量特性,存储延迟。当写读比例很大的时候(写比读多),LSM树相比于B树有更好的性能。因为随着insert操作,为了维护B+树结构,节点分裂。读磁盘的随机读写概率会变大,性能会逐渐减弱。
(b)B树的写入过程:对B树的写入过程是一次原位写入的过程,主要分为两个部分,首先是查找到对应的块的位置,然后将新数据写入到刚才查找到的数据块中,然后再查找到块所对应的磁盘物理位置,将数据写入去。当然,在内存比较充足的时候,因为B树的一部分可以被缓存在内存中,所以查找块的过程有一定概率可以在内存内完成,不过为了表述清晰,我们就假定内存很小,只够存一个B树块大小的数据吧。可以看到,在上面的模式中,需要两次随机寻道(一次查找,一次原位写),才能够完成一次数据的写入,代价还是很高的。
(c)LSM优化方式:
- Bloom filter: 就是个带随机概率的bitmap,可以快速的告诉你,某一个小的有序结构里有没有指定的那个数据的。于是就可以不用二分查找,而只需简单的计算几次就能知道数据是否在某个小集合里啦。效率得到了提升,但付出的是空间代价。
- compact:小树合并为大树:因为小树性能有问题,所以要有个进程不断地将小树合并到大树上,这样大部分的老数据查询也可以直接使用log2N的方式找到,不需要再进行(N/m)*log2n的查询了
平衡二叉树、B树、B+树、B*树、LSM树简介的更多相关文章
- LSM树由来、设计思想以及应用到HBase的索引
讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来: 哈希存储引擎 是哈希表的持久化实现,支持增.删.改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储 ...
- LSM树由来、设计思想以及应用到HBase的索引(转)
转自: http://www.cnblogs.com/yanghuahui/p/3483754.html 讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来: 哈希存储引擎 是哈 ...
- 面对key数量多和区间查询低效问题:Hash索引趴窝,LSM树申请出场
摘要:Hash索引有两个明显的限制:(1)当key的数量很多时,维护Hash索引会给内存带来很大的压力:(2)区间查询很低效.如何对这两个限制进行优化呢?这就轮到本文介绍的主角,LSM树,出场了. 我 ...
- LSM树以及在hbase中的应用
转自:http://www.cnblogs.com/yanghuahui/p/3483754.html 讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来: 哈希存储引擎 是哈希 ...
- LSM树——放弃读能力换取写能力,将多次修改放在内存中形成有序树再统一写入磁盘
LSM树(Log-Structured Merge Tree)存储引擎 代表数据库:nessDB.leveldb.hbase等 核心思想的核心就是放弃部分读能力,换取写入的最大化能力.LSM Tree ...
- 关于时间序列数据库的思考——(1)运用hash文件(例如:RRD,Whisper) (2)运用LSM树来备份(例如:LevelDB,RocksDB,Cassandra) (3)运用B-树排序和k/v存储(例如:BoltDB,LMDB)
转自:http://0351slc.com/portal.php?mod=view&aid=12 近期网络上呈现了有关catena.benchmarking boltdb等时刻序列存储办法的介 ...
- LSM树存储模型
----<大规模分布式存储系统:原理解析与架构实战>读书笔记 之前研究了Bitcask存储模型,今天来看看LSM存储模型,两者尽管同属于基于键值的日志型存储模型.可是Bitcask使用哈希 ...
- HBase LSM树存储引擎详解
1.前提 讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来: 哈希存储引擎. B树存储引擎. LSM树(Log-Structured Merge Tree)存储引擎. 2. 哈希 ...
- hbase——b树,b+树,lsm树
b树 b树,又叫做平衡多路查找树.一个m阶的b树的特性如下: 树中的每个节点,最多有m个子节点. 除了根节点之外,其他的每个节点至少有ceil(m/2)个子节点,ceil函数为取上限函数. 所有的叶子 ...
随机推荐
- STM32F10x_StdPeriph_Driver_3.5.0(中文版).chm的使用
以熟悉的固件库函数说明中函数GPIO_Init(GPIO_TypeDef *GPIOx, GPIO_IintTypeDef *GPIO_InitStructure)为例 GPIOA...G ...
- java实现简单的算法
排序大的分类可以分为两种:内排序和外排序.在排序过程中,全部记录存放在内存,则称为内排序,如果排序过程中需要使用外存,则称为外排序.下面讲的排序都是属于内排序. 内排序有可以分为以下几类: (1).插 ...
- sprak pom
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven ...
- Go -- go语言指针
package main import "fmt" type Test struct { Name string } func change2(t *Test) { t.Name ...
- windows redis 服务安装坑
环境 winserver 2012 最新版的redis:3.0.503 redis-server.exe --service-install redis.windows.conf --m ...
- ffmpeg实时编码解码部分代码
程序分为编码端和解码端,两端通过tcp socket通信,编码端一边编码一边将编码后的数据发送给解码端.解码端一边接收数据一边将解码得到的帧显示出来. 代码中的编码端编码的是实时屏幕截图. 代码调用 ...
- iOS 合并.a文件,制作通用静态库
lipo -create SQY/iOS/iphoneos/libGamePlusAPI.a SQY/iOS/iphonesimulator/libGamePlusAPI.a - output ...
- Elasticsearch shield权限管理详解
Elasticsearch shield权限管理详解 学习了:https://blog.csdn.net/napoay/article/details/52201558 现在(20180424)改名为 ...
- AppCan移动应用开发平台新增9个超有用插件(内含演示样例代码)
使用AppCan平台进行移动开发.你所须要具备的是Html5+CSS +JS前端语言基础.此外.Hybrid混合模式应用还需结合原生语言对功能模块进行封装,对于没有原生基础的开发人员,怎样实现App里 ...
- [java][db]JAVA分布式事务原理及应用
JTA(Java Transaction API)同意应用程序运行分布式事务处理--在两个或多个网络计算机资源上訪问而且更新数据.JDBC驱动程序的JTA支持极大地增强了数据訪问能力. 本文的目的是 ...