在hue平台上使用oozie工作流调度
在实习期间,公司使用的hue平台做的数仓,下面就简单介绍一下hue的一些使用的注意事项,主要是工作流的使用和调度
进入hue首页:
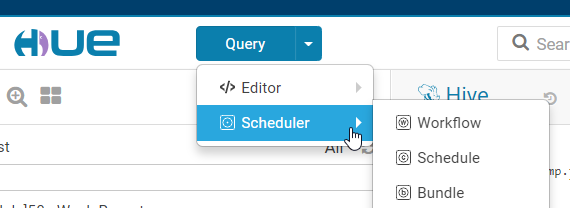
Workflow是工作流,Schedule是调度工作流的,如设置工作流何时跑,周期是多久,等等,下面会详细介绍,Bundle是绑定多个调度,暂时我没有用上
等使用后再更新

上面有一栏,有hive,hive2,spark,java,shell等等,直接拖入到Drop your action here这个阴影框中即可
下面的都以hive2为例,

选择文件添加即可,同时下面还有很多选项
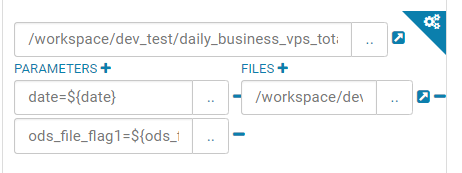
友情提示,虽然已经选择了文件,但是我建议还是在选择一次,右边的是添加文件依赖,
左边是参数设置,比如工作流按时间跑,设置是时间等等,根据需求设置即可
工作流建立完成之后,单个脚本或者代码可以单独执行,进行测试,再右上角
或者整个工作流进行运行,也是在右上角
这是工作流的配置,下面讲调度
进入调度

选择一个workflow工作流
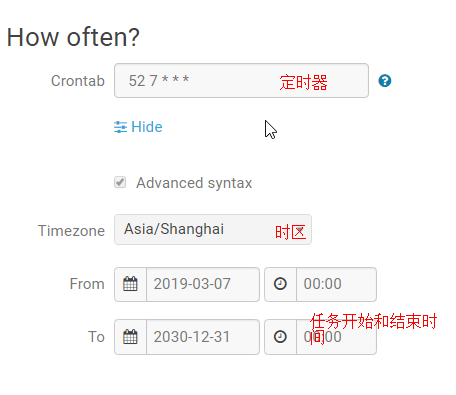
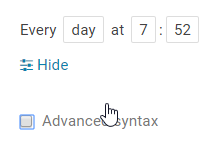
注意hue,oozie是有时区的设置的,默认是零时区时间,换成东八区时间要+8小时,设置配置时间同步
由于公司没有设置,所以是在建立调度上自己注意的,这里的时间都是零时区的时间
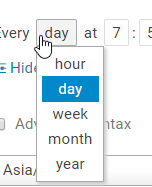 可以按小时,天,周,月,年进行定时调度
可以按小时,天,周,月,年进行定时调度
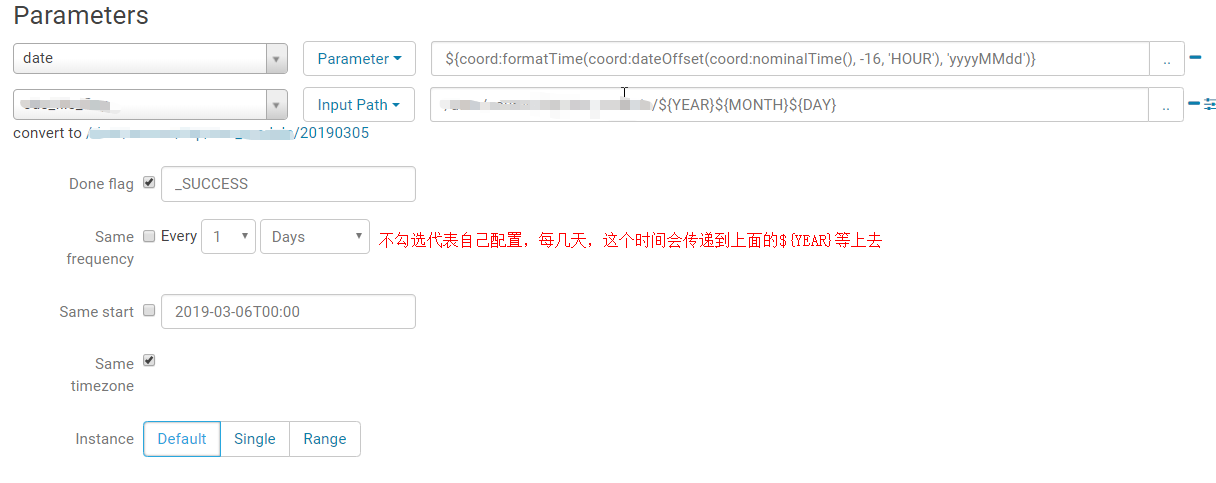
因为是今天跑昨天的数据,所以数据是昨天的,时间要减,因为是零时区的时间和东八区的时间差了8个小时,所以减了16个小时
下面的是输入文件,起到标识作用,有了这个文件任务才能启动,也是一种依赖文件
还有一种情况

如果是周计划,或者月计划,需要依赖多个,如7个,30个文件,不可能一一配置
选择上面的range,-6代表从任务执行的是时间-6,因为时区原因,如果是星期一启动任务,则到了上周星期一,0到了上周日
这是跑周计划中依赖一周的文件,其他情况可以参考上面的,可能会一些时区或者平台的问题有一些出入,配置根据具体情况而定
任务运行后可以查看执行情况: 在右上角,
在右上角,
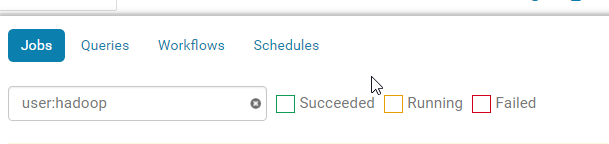
自己选择查看类型,里面也有日志,执行task,执行参数,时间等等
在hue平台上使用oozie工作流调度的更多相关文章
- 工作流调度引擎---Oozie
Oozie使用教程 一. Oozie简介 Apache Oozie是用于Hadoop平台的一种工作流调度引擎. 作用 - 统一调度hadoop系统中常见的mr任务启动hdfs操作.shell调度. ...
- 高可用Hadoop平台-Oozie工作流之Hadoop调度
1.概述 在<高可用Hadoop平台-Oozie工作流>一篇中,给大家分享了如何去单一的集成Oozie这样一个插件.今天为大家介绍如何去使用Oozie创建相关工作流运行与Hadoop上,已 ...
- HUE通过oozie工作流执行shell脚本
HUE通过oozie工作流执行shell脚本 2018年01月17日 16:20:38 阅读数:217 首先上传对应的jar包和storm.sh脚本到hdfs,脚本内容如下: 脚本主要内容是:从hdf ...
- 高可用Hadoop平台-Oozie工作流
1.概述 在开发Hadoop的相关应用使用,在业务不复杂,任务不多的情况下,我们可以直接使用Crontab去完成相关应用的调度.今天给大家介绍的是统一管理各种调度任务的系统,下面为今天分享的内容目录: ...
- 工作流调度器azkaban(以及各种工作流调度器比对)
1:工作流调度系统的作用: (1):一个完整的数据分析系统通常都是由大量任务单元组成:比如,shell脚本程序,java程序,mapreduce程序.hive脚本等:(2):各任务单元之间存在时间先后 ...
- azkaban工作流调度器及相关工具对比
本文转载自:工作流调度器azkaban,主要用于架构选型,安装请参考:Azkaban安装与简介,azkaban的简单使用 为什么需要工作流调度系统 一个完整的数据分析系统通常都是由大量任务单元组成: ...
- 工作流调度器azkaban
为什么需要工作流调度系统 一个完整的数据分析系统通常都是由大量任务单元组成: shell脚本程序,java程序,mapreduce程序.hive脚本等 各任务单元之间存在时间先后及前后依赖关系 为了很 ...
- 工作流调度器azkaban2.5.0的安装和使用
为什么需要工作流调度系统 一个完整的数据分析系统通常都是由大量任务单元组成: shell脚本程序,java程序,mapreduce程序.hive脚本等 各任务单元之间存在时间先后及前后依赖关系 为了很 ...
- Azkaban 工作流调度器
Azkaban 工作流调度器 1 概述 1.1 为什么需要工作流调度系统 a)一个完整的数据分析系统通常都是由大量任务单元组成,shell脚本程序,java程序,mapreduce程序.hive脚本等 ...
随机推荐
- Android ListView的XML属性
1.ListView的XML属性 android:divider //在列表条目之间显示的drawable或color android:dividerHeight //用来指定divider的高度 a ...
- Pig join用法举例
jnd = join a by f1, b by f2; join操作默认的是内连接,只有两边都匹配才会保留 需要用null补位的那边需要知道它的模式: 如果是左外连接,需要知道右边的数据集的 ...
- zookeeper应用 - 配置服务
一端不停的更新配置,另一端监听这个配置的变化. 需要注意的是:监听端不一定读取到所有的变化.在zk服务器发送通知到客户端,客户端读取数据注册监听之间可能发生了多次数据变化,这些数据变化是得不到 ...
- Java设计模式----观察者模式详解
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/3 ...
- maven(19)-生命周期和内置插件
生命周期和依赖一样,是maven中最重要的核心概念.平时在使用maven时并不一定需要知道生命周期,但是只有明白了生命周期,才能真正理解很多重要的命令和插件配置. default生命周期 defaul ...
- Linux 加载卷组
root 用户下执行: vgchange -ay vgdatamount /u01 vgdisplay 查看卷组
- Sql Server中的谓词和运算符
谓词和运算符配合使用是我们得到理想数据的最佳途径. 一.浅谈谓词 谓词的概念:一个运算结果为True.False或Unknown的逻辑表达式.它的运用范围有:where子句.Having子句.Chec ...
- a标签 按钮化使用
a标签 按钮化使用 a href="javascript:void(0);" onclick="js_method()" a href="javasc ...
- 教你如何获取ipa包中的开发文件
教你如何获取ipa包中的开发文件 1. 从iTunes获取到ipa包 2. 修改ipa包然后获取里面的开发文件
- 铁乐学python_day05-作业
1,有如下变量(tu是个元祖),请实现要求的功能 tu = ("alex", [11, 22, {"k1": 'v1', "k2": [&q ...