使用Java实现网络爬虫
网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取
网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整
个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。所以要想抓取网络上的数据,不仅需要爬虫程序还需要一个可以接
受”爬虫“发回的数据并进行处理过滤的服务器,爬虫抓取的数据量越大,对服务器的性能要求则越高。
1 聚焦爬虫工作原理以及关键技术概述
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上
的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析
算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上
述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚
焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。

相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
(1) 对抓取目标的描述或定义;
(2) 对网页或数据的分析与过滤;
(3) 对URL的搜索策略。
分类
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、
增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。 实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
网络爬虫的实现原理
根据这种原理,写一个简单的网络爬虫程序 ,该程序实现的功能是获取网站发回的数据,并提取之中的网址,获取的网址我们存放在一个文件夹中,关于如何就从网
站获取的网址进一步循环下去获取数据并提取其中其他数据这里就不在写了,只是模拟最简单的一个原理则可以,实际的网站爬虫远比这里复杂多,深入讨论就太多
了。除了提取网址,我们还可以提取其他各种我们想要的信息,只要修改过滤数据的表达式则可以。以下是利用Java模拟的一个程序,提取新浪页面上的链接,存放
在一个文件里
源代码如下
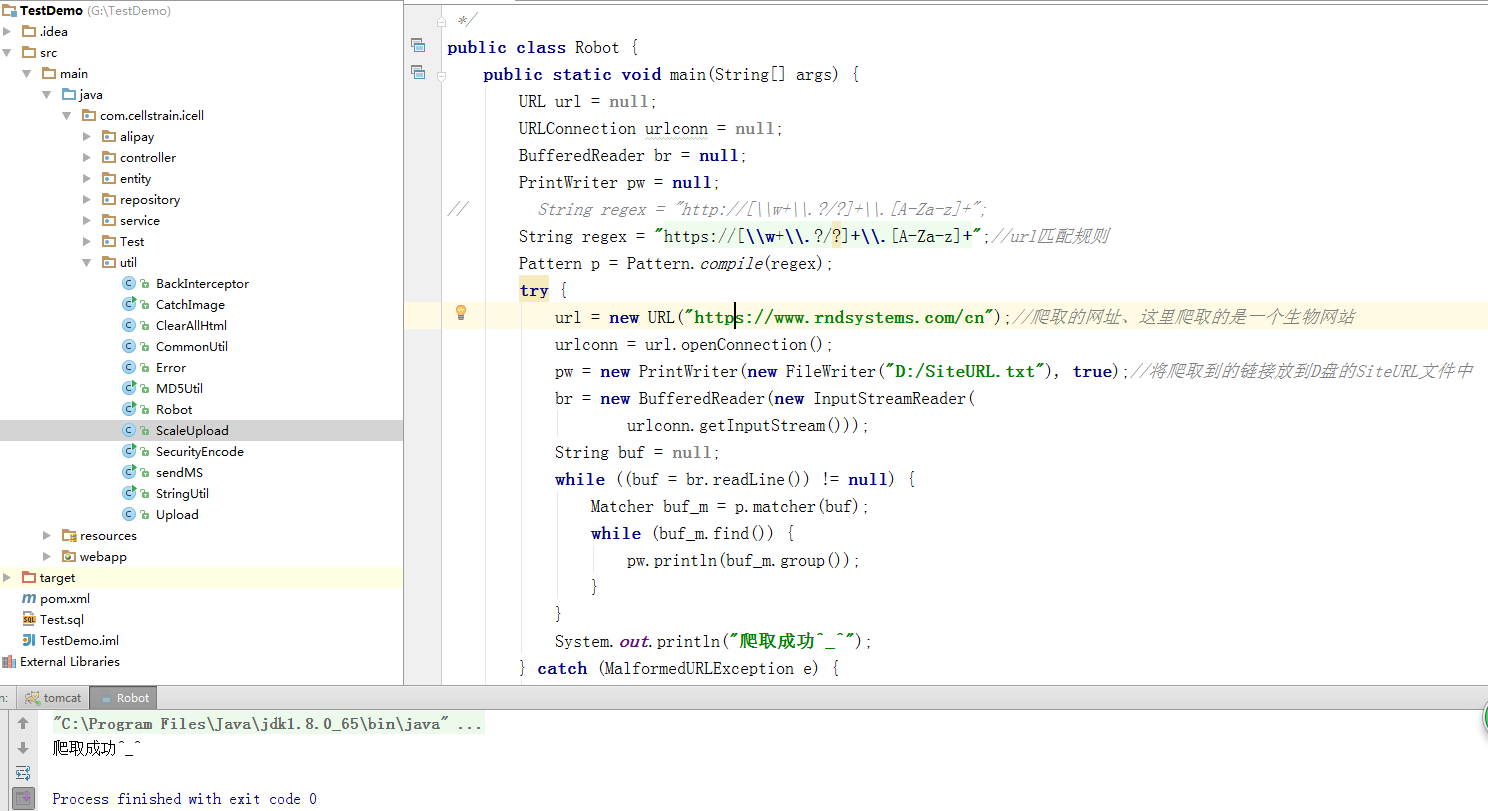
package com.cellstrain.icell.util; import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern; /**
* java实现爬虫
*/
public class Robot {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
// String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";//url匹配规则
Pattern p = Pattern.compile(regex);
try {
url = new URL("https://www.rndsystems.com/cn");//爬取的网址、这里爬取的是一个生物网站
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("D:/SiteURL.txt"), true);//将爬取到的链接放到D盘的SiteURL文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
在idea的运行结果如下:
看一下D盘有没有SiteURL.txt文件

已经成功生成SiteURL文件,打开可以看到里面都是抓取到的url

以上就是一个简单的java爬取网站的url实例,希望能够帮到你哦

使用Java实现网络爬虫的更多相关文章
- Java之网络爬虫WebCollector2.1.2+selenium2.44+phantomjs2.1.1
Java之网络爬虫WebCollector2.1.2+selenium2.44+phantomjs2.1.1 一.简介 版本匹配: WebCollector2.12 + selenium2.44.0 ...
- java之网络爬虫介绍
文章大纲 一.网络爬虫基本介绍二.java常见爬虫框架介绍三.WebCollector实战四.项目源码下载五.参考文章 一.网络爬虫基本介绍 1. 什么是网络爬虫 网络爬虫(又被称为网页蜘蛛, ...
- 基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库)
原文地址http://blog.csdn.net/qy20115549/article/details/52203722 本文为原创博客,仅供技术学习使用.未经允许,禁止将其复制下来上传到百度文库等平 ...
- Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途! 今天接触了一款有意思的框架,作用是网络爬虫,他可以像操作JS一样对网页内容进行提取 初体验Jsoup <!-- Ma ...
- Java版网络爬虫基础(转)
网络爬虫不仅仅可以爬取网站的网页,图片,甚至可以实现抢票功能,网上抢购,机票查询等.这几天看了点基础,记录下来. 网页的关系可以看做是一张很大的图,图的遍历可以分为深度优先和广度优先.网络爬虫采取的广 ...
- Java版网络爬虫基础
网络爬虫不仅仅可以爬取网站的网页,图片,甚至可以实现抢票功能,网上抢购,机票查询等.这几天看了点基础,记录下来. 网页的关系可以看做是一张很大的图,图的遍历可以分为深度优先和广度优先.网络爬虫采取的广 ...
- 用Java实现网络爬虫
myCrawler.java package WebCrawler; import java.io.File; import java.util.ArrayList; import java.util ...
- java实现网络爬虫
import java.io.IOException; import java.util.HashSet; import java.util.Set; import java.util.r ...
- JAVA平台上的网络爬虫脚本语言 CrawlScript
JAVA平台上的网络爬虫脚本语言 CrawlScript 网络爬虫即自动获取网页信息的一种程序,有很多JAVA.C++的网络爬虫类库,但是在这些类库的基础上开发十分繁琐,需要大量的代码才可以完成一 个 ...
随机推荐
- nginx 域名绑定
单个域名 upstream web{ server ;//这里绑定你要访问的服务器地址 keepalive ; } server { listen ; server_name www.xxxx.con ...
- PowerDesigner 连接oracle数据库
TNS Service Name 不是监听名称,填写这个格式就可以了 10.0.0.2:1521/orcl
- Eclipse launch configuration----Eclipse运行外部工具
虽然我们已经有了像 Eclipse 这样高级的 IDE,但是我们有时候也是需要在开发的时候使用 Windows 的命令行,来运行一些独立的程序.在两个程序中切换来切换去是很麻烦的.所以 Eclipse ...
- 超简单,webpack配置
有看过我的博客的童鞋可能有看到我最近有在利用闲暇时间做一个前后台均涵盖的音乐播放器项目,但是呢,我是一个小小的前端,对后台的了解可以说只停留在很初级的阶段,当然了音乐播放器的音乐列表是后台轮循出来的, ...
- python传参数
Python参数传递采用的肯定是“传对象引用”的方式.这种方式相当于传值和传引用的一种综合.如果函数收到的是一个可变对象(比如字典或者列表)的引用,就能修改对象的原始值--相当于通过“传引用”来传递对 ...
- mtr 命令详解
一般在windows 来判断网络连通性用ping 和tracert,ping的话可以来判断丢包率,tracert可以用来跟踪路由,在Linux中有一个更好的网络连通性判断工具,它可以结合ping ns ...
- hadoop无法启动常见原因
1.Could not chdir to home directory /home/USER: Permission denied 启动datanode时会报这个错误,尝试利用ssh登录datanod ...
- spring 中c3p0的优化配置
jdbc.properties driverClass=com.mysql.jdbc.Driver jdbcUrl=jdbc:mysql://localhost:3306/testdb user=ro ...
- testng + Ignore 忽略测试方法
使用testng的时候,有时候会忽略掉某些测试方法,暂时不跑,简单整理一下一些方法.转载还请说明下 1.使用@Test(enable=false)方法 @Feature("查询") ...
- python作业(第十一周)基于RabbitMQ rpc实现的主机管理
作业需求: 可以对指定机器异步的执行多个命令 例子: >>:run "df -h" --hosts 192.168.3.55 10.4.3.4 task id: 453 ...