MapReduce的原理及执行过程
MapReduce简介
- MapReduce是一种分布式计算模型,是Google提出的,主要用于搜索领域,解决海量数据的计算问题。
- MR有两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
MapReduce执行流程
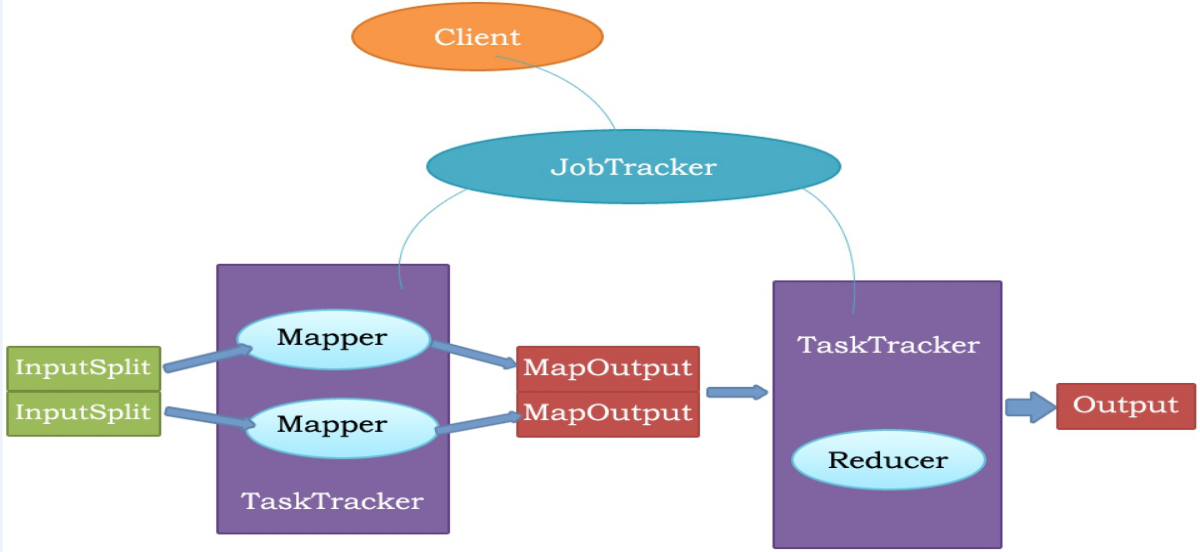
MapReduce原理
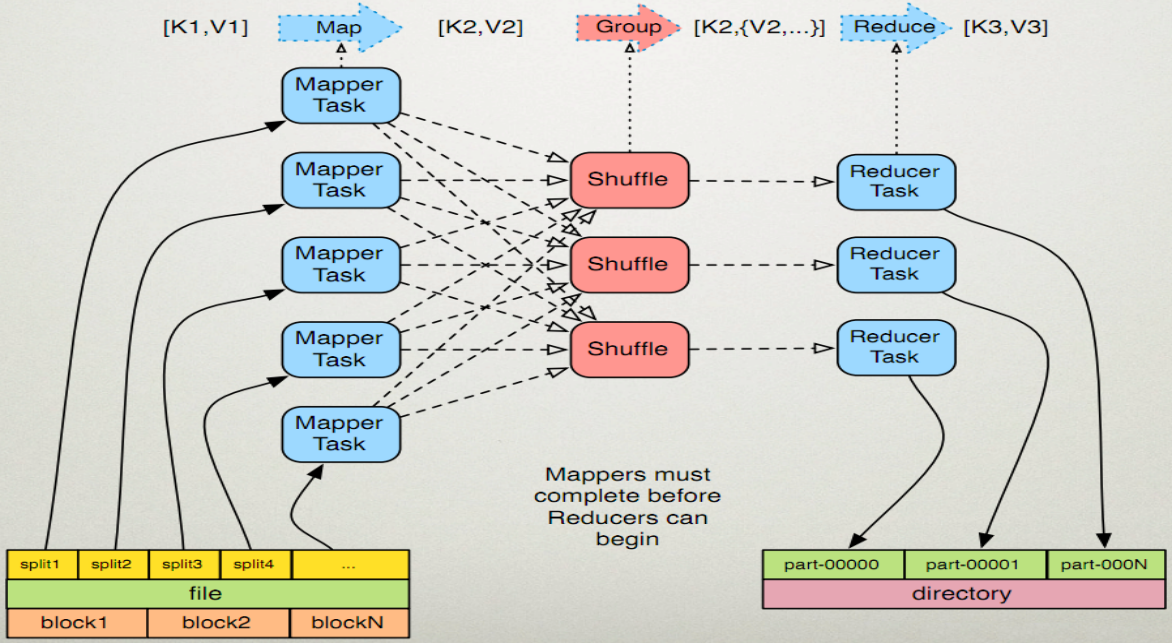
MapReduce的执行步骤:
1、Map任务处理
1.1 读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数。 <0,hello you> <10,hello me>
1.2 覆盖map(),接收1.1产生的<k,v>,进行处理,转换为新的<k,v>输出。 <hello,1> <you,1> <hello,1> <me,1>
1.3 对1.2输出的<k,v>进行分区。默认分为一个区。详见《Partitioner》
1.4 对不同分区中的数据进行排序(按照k)、分组。分组指的是相同key的value放到一个集合中。 排序后:<hello,1> <hello,1> <me,1> <you,1> 分组后:<hello,{1,1}><me,{1}><you,{1}>
1.5 (可选)对分组后的数据进行归约。详见《Combiner》
2、Reduce任务处理
2.1 多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点上。(shuffle)详见《shuffle过程分析》
2.2 对多个map的输出进行合并、排序。覆盖reduce函数,接收的是分组后的数据,实现自己的业务逻辑, <hello,2> <me,1> <you,1>
处理后,产生新的<k,v>输出。
2.3 对reduce输出的<k,v>写到HDFS中。
Java代码实现
注:要导入org.apache.hadoop.fs.FileUtil.java。
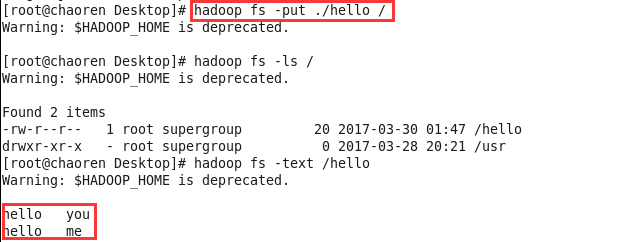
1、先创建一个hello文件,上传到HDFS中
2、然后再编写代码,实现文件中的单词个数统计(代码中被注释掉的代码,是可以省略的,不省略也行)
package mapreduce; import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCountApp {
static final String INPUT_PATH = "hdfs://chaoren:9000/hello";
static final String OUT_PATH = "hdfs://chaoren:9000/out"; public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
Path outPath = new Path(OUT_PATH);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
} Job job = new Job(conf, WordCountApp.class.getSimpleName()); // 1.1指定读取的文件位于哪里
FileInputFormat.setInputPaths(job, INPUT_PATH);
// 指定如何对输入的文件进行格式化,把输入文件每一行解析成键值对
//job.setInputFormatClass(TextInputFormat.class); // 1.2指定自定义的map类
job.setMapperClass(MyMapper.class);
// map输出的<k,v>类型。如果<k3,v3>的类型与<k2,v2>类型一致,则可以省略
//job.setOutputKeyClass(Text.class);
//job.setOutputValueClass(LongWritable.class); // 1.3分区
//job.setPartitionerClass(org.apache.hadoop.mapreduce.lib.partition.HashPartitioner.class);
// 有一个reduce任务运行
//job.setNumReduceTasks(1); // 1.4排序、分组 // 1.5归约 // 2.2指定自定义reduce类
job.setReducerClass(MyReducer.class);
// 指定reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); // 2.3指定写出到哪里
FileOutputFormat.setOutputPath(job, outPath);
// 指定输出文件的格式化类
//job.setOutputFormatClass(TextOutputFormat.class); // 把job提交给jobtracker运行
job.waitForCompletion(true);
} /**
*
* KEYIN 即K1 表示行的偏移量
* VALUEIN 即V1 表示行文本内容
* KEYOUT 即K2 表示行中出现的单词
* VALUEOUT 即V2 表示行中出现的单词的次数,固定值1
*
*/
static class MyMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable k1, Text v1, Context context)
throws java.io.IOException, InterruptedException {
String[] splited = v1.toString().split("\t");
for (String word : splited) {
context.write(new Text(word), new LongWritable(1));
}
};
} /**
* KEYIN 即K2 表示行中出现的单词
* VALUEIN 即V2 表示出现的单词的次数
* KEYOUT 即K3 表示行中出现的不同单词
* VALUEOUT 即V3 表示行中出现的不同单词的总次数
*/
static class MyReducer extends
Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(Text k2, java.lang.Iterable<LongWritable> v2s,
Context ctx) throws java.io.IOException,
InterruptedException {
long times = 0L;
for (LongWritable count : v2s) {
times += count.get();
}
ctx.write(k2, new LongWritable(times));
};
}
}
3、运行成功后,可以在Linux中查看操作的结果

MapReduce的原理及执行过程的更多相关文章
- 通过源码了解ASP.NET MVC 几种Filter的执行过程
一.前言 之前也阅读过MVC的源码,并了解过各个模块的运行原理和执行过程,但都没有形成文章(所以也忘得特别快),总感觉分析源码是大神的工作,而且很多人觉得平时根本不需要知道这些,会用就行了.其实阅读源 ...
- 通过源码了解ASP.NET MVC 几种Filter的执行过程 在Winform中菜单动态添加“最近使用文件”
通过源码了解ASP.NET MVC 几种Filter的执行过程 一.前言 之前也阅读过MVC的源码,并了解过各个模块的运行原理和执行过程,但都没有形成文章(所以也忘得特别快),总感觉分析源码是大神 ...
- MapReduce概述,原理,执行过程
MapReduce概述 MapReduce是一种分布式计算模型,运行时不会在一台机器上运行.hadoop是分布式的,它是运行在很多的TaskTracker之上的. 在我们的TaskTracker上面跑 ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- Web APi之过滤器执行过程原理解析【二】(十一)
前言 上一节我们详细讲解了过滤器的创建过程以及粗略的介绍了五种过滤器,用此五种过滤器对实现对执行Action方法各个时期的拦截非常重要.这一节我们简单将讲述在Action方法上.控制器上.全局上以及授 ...
- 四、Struts2的执行过程和原理
执行过程和原理(可能面试题) 学习目标:熟知struts2的执行过程(下图记住).源码可以不看 a.过滤器的初始化 .StrutsPrepareAndExecuteFilter是一个过滤器,过滤器就有 ...
- 分析MapReduce执行过程
分析MapReduce执行过程 MapReduce运行的时候,会通过Mapper运行的任务读取HDFS中的数据文件,然后调用自己的方法,处理数据,最后输出. Reducer任务会接收Mapper任务输 ...
- JSP起源、JSP的运行原理、JSP的执行过程
JSP起源 在很多动态网页中,绝大部分内容都是固定不变的,只有局部内容需要动态产生和改变. 如果使用Servlet程序来输出只有局部内容需要动态改变的网页,其中所有的静态内容也需要程序员用Java程序 ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
随机推荐
- ActiveMQ基本详解与总结& 消息队列-推/拉模式学习 & ActiveMQ及JMS学习
转自:https://www.cnblogs.com/Survivalist/p/8094069.html ActiveMQ基本详解与总结 基本使用可以参考https://www.cnblogs.co ...
- The Difference Between Big Data and a Lot of Data
The Difference Between Big Data and a Lot of Data The term “big data” has been around for a while no ...
- angularJS $http $q $promise
一天早晨,爹对儿子说:“宝儿,出去看看天气如何!” 每个星期天的早晨,爹都叫小宝拿着超级望远镜去家附近最高的山头上看看天气走势如何,小宝说没问题,我们可以认为小宝在离开家的时候给了他爹一个promis ...
- SSM简单整合教程&测试事务
自打来了博客园就一直在看帖,学到了很多知识,打算开始记录的学习到的知识点 今天我来写个整合SpringMVC4 spring4 mybatis3&测试spring事务的教程,如果有误之处,还请 ...
- [NOIP2015提高&洛谷P2678]跳石头 题解(二分答案)
[NOIP2015提高&洛谷P2678]跳石头 Description 这项比赛将在一条笔直的河道中进行,河道中分布着一些巨大岩石.组委会已经选择好了两块岩石作为比赛起点和终点.在起点和终点之 ...
- 配置ODBC DSN数据源,导出数据库数据到Excel过程记录
一.前言 工作中我们可能遇到这样的需要:查询数据库中的信息,并将结果导出到Excel文件.这本来没什么,但数据量比较大时,用PLSQL.toad导出Excel会出现内存不足等情况,使用odbc+Mic ...
- SQL Server 将Id相同的字段合并,并且以逗号隔开
例如:有表MO_Cook,字段:FoodRoom,name 有如下数据: 要求:将FoodRoom中值相同的字段合并成一行,并将name的值用逗号隔开. 需要用到:STUFF函数. 查询语句如下: ...
- win7.wifi热点
使用本地连接上网,将网卡设为wifi热点 cmd 管理员身份运行 netsh wlan set hostednetwork mode=allow ssid=4Gtest key=12345678 网络 ...
- JS设计模式——7.工厂模式(概念)
工厂模式 本章讨论两种工厂模式: 简单工厂模式 使用一个类(通常是一个单体)来生成实例. 使用场景:假设你想开几个自行车商店(创建自行车实例,组装它,清洗它,出售它),每个店都有几种型号的自行车出售. ...
- 【多视图几何】TUM 课程 第6章 多视图重建
课程的 YouTube 地址为:https://www.youtube.com/playlist?list=PLTBdjV_4f-EJn6udZ34tht9EVIW7lbeo4 .视频评论区可以找到课 ...