全局唯一ID生成器
分布式环境中,如何保证生成的id是唯一不重复的?
twitter,开源出了一个snowflake算法,现在很多企业都按照该算法作为参照,实现了自己的一套id生成器。
该算法的主要思路为:
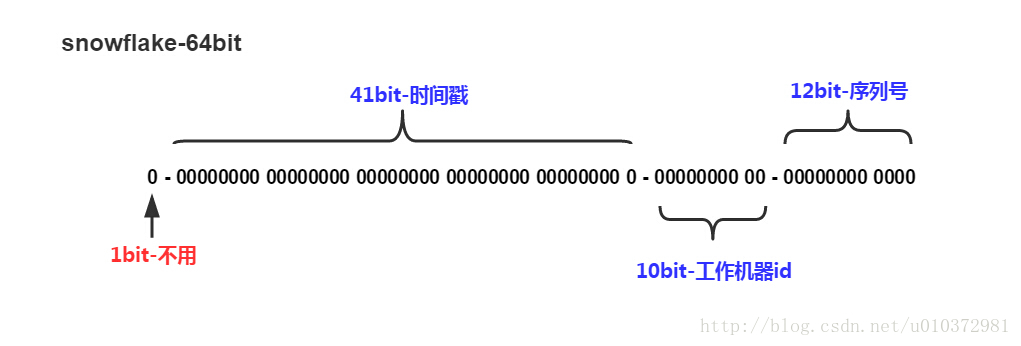
刚好64位的long型数据。
上图中主要由4个部分组成:
第一部分,1位为标识位,不用。
第二部分,41位,用来记录当前时间与标记时间twepoch的毫秒数的差值,41位的时间截,可以使用69年,T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69
第三部分,10位,用来记录当前节点的信息,支持2的10次方台机器
第四部分,12位,用来支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号
java代码
- /**
- * Twitter_Snowflake<br>
- * SnowFlake的结构如下(每部分用-分开):<br>
- * 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br>
- * SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分)
- */
- public class SnowflakeIdWorker {
- /** 开始时间截 (2015-01-01) */
- private final long twepoch = 1420041600000L;
- /** 机器id所占的位数 */
- private final long workerIdBits = 5L;
- /** 数据标识id所占的位数 */
- private final long datacenterIdBits = 5L;
- /** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
- private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
- /** 支持的最大数据标识id,结果是31 */
- private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
- /** 序列在id中占的位数 */
- private final long sequenceBits = 12L;
- /** 机器ID向左移12位 */
- private final long workerIdShift = sequenceBits;
- /** 数据标识id向左移17位(12+5) */
- private final long datacenterIdShift = sequenceBits + workerIdBits;
- /** 时间截向左移22位(5+5+12) */
- private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
- /** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
- private final long sequenceMask = -1L ^ (-1L << sequenceBits);
- /** 工作机器ID(0~31) */
- private long workerId;
- /** 数据中心ID(0~31) */
- private long datacenterId;
- /** 毫秒内序列(0~4095) */
- private long sequence = 0L;
- /** 上次生成ID的时间截 */
- private long lastTimestamp = -1L;
- /**
- * 构造函数
- * @param workerId 工作ID (0~31)
- * @param datacenterId 数据中心ID (0~31)
- */
- public SnowflakeIdWorker(long workerId, long datacenterId) {
- if (workerId > maxWorkerId || workerId < 0) {
- throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
- }
- if (datacenterId > maxDatacenterId || datacenterId < 0) {
- throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
- }
- this.workerId = workerId;
- this.datacenterId = datacenterId;
- }
- /**
- * 获得下一个ID (该方法是线程安全的)
- * @return SnowflakeId
- */
- public synchronized long nextId() {
- long timestamp = timeGen();
- //如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
- if (timestamp < lastTimestamp) {
- throw new RuntimeException(
- String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
- }
- //如果是同一时间生成的,则进行毫秒内序列
- if (lastTimestamp == timestamp) {
- sequence = (sequence + 1) & sequenceMask;
- //毫秒内序列溢出
- if (sequence == 0) {
- //阻塞到下一个毫秒,获得新的时间戳
- timestamp = tilNextMillis(lastTimestamp);
- }
- }
- //时间戳改变,毫秒内序列重置
- else {
- sequence = 0L;
- }
- //上次生成ID的时间截
- lastTimestamp = timestamp;
- //移位并通过或运算拼到一起组成64位的ID
- return ((timestamp - twepoch) << timestampLeftShift) //
- | (datacenterId << datacenterIdShift) //
- | (workerId << workerIdShift) //
- | sequence;
- }
- /**
- * 阻塞到下一个毫秒,直到获得新的时间戳
- * @param lastTimestamp 上次生成ID的时间截
- * @return 当前时间戳
- */
- protected long tilNextMillis(long lastTimestamp) {
- long timestamp = timeGen();
- while (timestamp <= lastTimestamp) {
- timestamp = timeGen();
- }
- return timestamp;
- }
- /**
- * 返回以毫秒为单位的当前时间
- * @return 当前时间(毫秒)
- */
- protected long timeGen() {
- return System.currentTimeMillis();
- }
- }
/**
* Twitter_Snowflake<br>
* SnowFlake的结构如下(每部分用-分开):<br>
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br>
* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分)
*/
public class SnowflakeIdWorker { /** 开始时间截 (2015-01-01) */
private final long twepoch = 1420041600000L; /** 机器id所占的位数 */
private final long workerIdBits = 5L; /** 数据标识id所占的位数 */
private final long datacenterIdBits = 5L; /** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
private final long maxWorkerId = -1L ^ (-1L << workerIdBits); /** 支持的最大数据标识id,结果是31 */
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); /** 序列在id中占的位数 */
private final long sequenceBits = 12L; /** 机器ID向左移12位 */
private final long workerIdShift = sequenceBits; /** 数据标识id向左移17位(12+5) */
private final long datacenterIdShift = sequenceBits + workerIdBits; /** 时间截向左移22位(5+5+12) */
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits; /** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
private final long sequenceMask = -1L ^ (-1L << sequenceBits); /** 工作机器ID(0~31) */
private long workerId; /** 数据中心ID(0~31) */
private long datacenterId; /** 毫秒内序列(0~4095) */
private long sequence = 0L; /** 上次生成ID的时间截 */
private long lastTimestamp = -1L; /**
* 构造函数
* @param workerId 工作ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public SnowflakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
} /**
* 获得下一个ID (该方法是线程安全的)
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen(); //如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
} //如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
} //上次生成ID的时间截
lastTimestamp = timestamp; //移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
} /**
* 阻塞到下一个毫秒,直到获得新的时间戳
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
} /**
* 返回以毫秒为单位的当前时间
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
}
全局唯一ID生成器的更多相关文章
- Spring Boot集成全局唯一ID生成器
流水号生成器(全局唯一 ID生成器)是服务化系统的基础设施,其在保障系统的正确运行和高可用方面发挥着重要作用.而关于流水号生成算法首屈一指的当属 Snowflake雪花算法,然而 Snowflake本 ...
- 全局唯一ID生成器(Snowflake ID组成) 分析
Snowflake ID组成 Snowflake ID有64bits长,由以下三部分组成: time—42bits,精确到ms,那就意味着其可以表示长达(2^42-1)/(1000360024*365 ...
- 常见的生成全局唯一id有哪些?他们各有什么优缺点?
分布式系统中全局唯一id是我们经常用到的,生成全局id方法由很多,我们选择的时候也比较纠结.每种方式都有各自的使用场景,如果我们熟悉各种方式及优缺点,使用的时候才会更方便.下面我们就一起来看一下常见的 ...
- 全局唯一ID设计
在分布式系统中,经常需要使用全局唯一ID查找对应的数据.产生这种ID需要保证系统全局唯一,而且要高性能以及占用相对较少的空间. 全局唯一ID在数据库中一般会被设成主键,这样为了保证数据插入时索引的快速 ...
- 高并发分布式系统中生成全局唯一Id汇总
数据在分片时,典型的是分库分表,就有一个全局ID生成的问题.单纯的生成全局ID并不是什么难题,但是生成的ID通常要满足分片的一些要求: 1 不能有单点故障. 2 以时间为序,或者ID里包含时间 ...
- 如何在高并发分布式系统中生成全局唯一Id(转)
http://www.cnblogs.com/heyuquan/p/global-guid-identity-maxId.html 又一个多月没冒泡了,其实最近学了些东西,但是没有安排时间整理成博文, ...
- 游戏服务器生成全局唯一ID的几种方法
在服务器系统开发时,为了适应数据大并发的请求,我们往往需要对数据进行异步存储,特别是在做分布式系统时,这个时候就不能等待插入数据库返回了取自动id了,而是需要在插入数据库之前生成一个全局的唯一id,使 ...
- (转)如何在高并发分布式系统中生成全局唯一Id
又一个多月没冒泡了,其实最近学了些东西,但是没有安排时间整理成博文,后续再奉上.最近还写了一个发邮件的组件以及性能测试请看 <NET开发邮件发送功能的全面教程(含邮件组件源码)> ,还弄了 ...
- 全局唯一ID发号器的几个思路
标识(ID / Identifier)是无处不在的,生成标识的主体是人,那么它就是一个命名过程,如果是计算机,那么它就是一个生成过程.如何保证分布式系统下,并行生成标识的唯一与标识的命名空间有着密不可 ...
随机推荐
- Redis笔记(二):Redis数据类型
Redis 数据类型 Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合). String(字符串) st ...
- 用企业微信实现预警(shell + python)
目录 一 注册企业微信 注册企业微信必备条件 注册 二 创建消息 创建部门 邀请成员加入 创建应用 关注微工作平台 三 实现预警 通过shell 脚本实现监控预警 通过python 脚本实现监控预警 ...
- C/C++内存管理详解
内存管理是C++最令人切齿痛恨的问题,也是C++最有争议的问题,C++高手从中获得了更好的性能,更大的自由,C++菜鸟的收获则是一遍一遍的检查代码和对C++的痛恨,但内存管理在C++中无处不在,内存泄 ...
- Nodejs学习笔记(七)—Node.js + Express 构建网站简单示例
前言 上一篇学习了一些构建网站会用到的一些知识点:https://www.cnblogs.com/flyingeagle/p/9192936.html 这一篇主要结合前面讲到的知识,去构建一个较为完整 ...
- redis实战笔记(2)-第2章 使用 Redis构建Web应用
第2章 使用 Redis构建Web应用 本章主要内容 1.登录cookie 2.购物车cookie 3.缓存生成的网页 4.缓存数据库行 5.分析网页访问记录 本章的所有内容都是围绕着发现并解 ...
- 遇见CUBA CLI
原文:Meet CLI for CUBA Platform 翻译:CUBA China CUBA-Platform 官网 : https://www.cuba-platform.com CUBA Ch ...
- Redis--redis集群环境搭建
1.redis-cluster架构图 Redis 自3.0以后开始支持集群.从上图我们可以看出,redis集群的每个节点之间都进行相互通信,在redis集群中,不存在代理层,即没有固定的入口.redi ...
- JBoss 实战(2)
转自:https://www.cnblogs.com/aiwz/p/6154591.html JBOSS HTTP的Thread Group概念 JBOSS是一个企业级的J2EE APP Contai ...
- redis on windows
https://github.com/MSOpenTech/redis 下载解压 在/bin/release里还有一个压缩包,这个压缩包是生成好的 解压 运行redis-server 乌拉乌拉说了一堆 ...
- 360手机新品牌5月6日公布 周鸿祎席地而坐谈AK47
今年年初,周鸿祎又做了一个艰难的决定,南下做手机!经过好一番折腾终于搞出点动静,奔驰S600L也卖了(炒作的味道很浓重),一款代号为AK47的产品被确认,就连邀请函也充分的体现了周鸿祎的老兵情节.最近 ...