JS数组循环的性能和效率分析(for、while、forEach、map、for of)
从最简单的for循环说起
for( 初始化;条件; ){
}
条件为Trusy 值时候,可以继续执行for 循环,当条件变为Falsy 时跳出for循环。
for循环常见的四种写法
const persons = ['乔丹', '艾弗森', '邓肯', '科比', '麦迪', '奥尼尔']
// 方法一
for (let i = 0; i < persons.length; i++) {
console.log(persons[i])
}
// 方法二
for (let i = 0, len = persons.length; i < len; i++) {
console.log(persons[i])
}
// 方法三
for (let i = 0, person; person = persons[i]; i++) {
console.log(person)
}
// 方法四
for (let i = persons.length; i--;) {
console.log(persons[i])
}
第一种方法是最常见的方式,不解释。
第二种方法是将persons.length缓存到变量len中,这样每次循环时就不会再读取数组的长度。
第三种方式是将取值与判断合并,通过不停的枚举每一项来循环,直到枚举到空值则循环结束。执行顺序是:
第一步:先声明索引i = 0和变量person
第二步:取出数组的第i项persons[i]赋值给变量person并判断是否为Truthy(备注:Truthy,是指判断可为true的值,例如,1,true,”s“, [1],{age:9}, Falsy, 是指 0, false ,”“, undefined, null, [], 但是{} 不是Falsy值)
第三步:执行循环体,打印person
第四步:i++。
当第二步中person的值不再是Truthy时,循环结束。方法三甚至可以这样写
for (let i = 0, person; person = persons[i++];) {
console.log(person)
}
第四种方法是倒序循环。执行的顺序是:
第一步:获取数组长度,赋值给变量i
第二步:判断i是否大于0并执行i--
第三步:执行循环体,打印persons[i],此时的i已经-1了
从后向前,直到i === 0为止。这种方式不仅去除了每次循环中读取数组长度的操作,而且只创建了一个变量i。
四种for循环方式在数组浅拷贝中的性能和速度测试
先造一个足够长的数组作为要拷贝的目标(如果`i`值过大,到亿级左右,可能会抛出JS堆栈跟踪的报错)
const ARR_SIZE = 6666666
const hugeArr = new Array(ARR_SIZE).fill(1)
然后分别用四种循环方式,把数组中的每一项取出,并添加到一个空数组中,也就是一次数组的浅拷贝。并通过[console.time](https://developer.mozilla.org/en-US/docs/Web/API/Console/time)和[console.timeEnd](https://developer.mozilla.org/en-US/docs/Web/API/Console/timeEnd)记录每种循环方式的整体执行时间。通过[process.memoryUsage()](http://www.ruanyifeng.com/blog/2017/04/memory-leak.html)比对执行前后内存中已用到的堆的差值。
/* node环境下记录方法执行前后内存中已用到的堆的差值 */
function heapRecord(fun) {
if (process) {
const startHeap = process.memoryUsage().heapUsed
fun()
const endHeap = process.memoryUsage().heapUsed
const heapDiff = endHeap - startHeap
console.log('已用到的堆的差值: ', heapDiff)
} else {
fun()
}
}
// 方法一,普通for循环
function method1() {
var arrCopy = []
console.time('method1')
for (let i = 0; i < hugeArr.length; i++) {
arrCopy.push(hugeArr[i])
}
console.timeEnd('method1')
}
// 方法二,缓存长度
function method2() {
var arrCopy = []
console.time('method2')
for (let i = 0, len = hugeArr.length; i < len; i++) {
arrCopy.push(hugeArr[i])
}
console.timeEnd('method2')
}
// 方法三,取值和判断合并
function method3() {
var arrCopy = []
console.time('method3')
for (let i = 0, item; item = hugeArr[i]; i++) {
arrCopy.push(item)
}
console.timeEnd('method3')
}
// 方法四,i--与判断合并,倒序迭代
function method4() {
var arrCopy = []
console.time('method4')
for (let i = hugeArr.length; i--;) {
arrCopy.push(hugeArr[i])
}
console.timeEnd('method4')
}
分别调用上述方法,每个方法重复执行12次,去除一个最大值和一个最小值,求平均值(四舍五入),最终每个方法执行时间的结果如下表(测试机器:`MacBook Pro (15-inch, 2017) 处理器:2.8 GHz Intel Core i7 内存:16 GB 2133 MHz LPDDR3` 执行环境:`node v10.8.0`):
- 方法一 方法二 方法三 方法四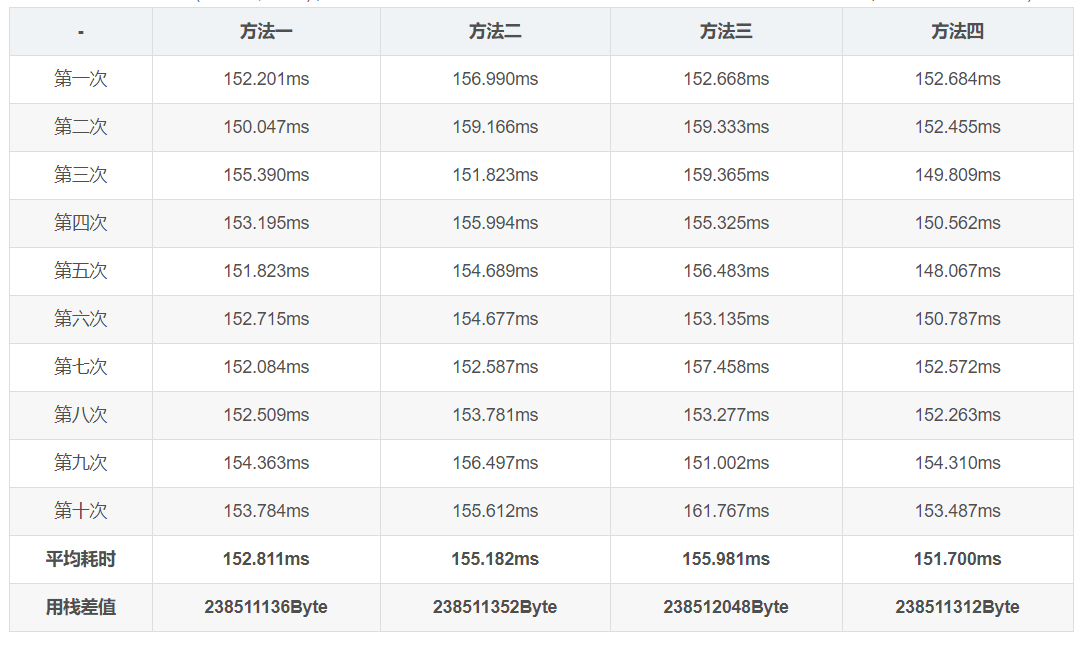
小结
在`node`下执行完成同一个数组的浅拷贝任务,耗时方面四种方法的差距微乎其微,有时候排序甚至略有波动。
考虑到在不同环境或浏览器下的性能和效率: `推荐`:第四种`i–`倒序循环的方式。`不推荐`:第三种方式。主要是因为当数组里存在非`Truthy`的值时,比如`0`和`”`,会导致循环直接结束。
while循环以及ES6+的新语法forEach、map和for of,会更快吗?
不啰嗦,实践是检验真理的唯一标准
// 方法五,while
function method5() {
var arrCopy = []
console.time('method5')
let i = 0
while (i < hugeArr.length) {
arrCopy.push(hugeArr[i++])
}
console.timeEnd('method5')
}
// 方法六,forEach
function method6() {
var arrCopy = []
console.time('method6')
hugeArr.forEach((item) => {
arrCopy.push(item)
})
console.timeEnd('method6')
}
// 方法七,map
function method7() {
var arrCopy = []
console.time('method7')
arrCopy = hugeArr.map(item => item)
console.timeEnd('method7')
}
}
// 方法八,for of
function method8() {
var arrCopy = []
console.time('method8')
for (let item of hugeArr) {
arrCopy.push(item)
}
console.timeEnd('method8')
}
测试方法同上,测试结果: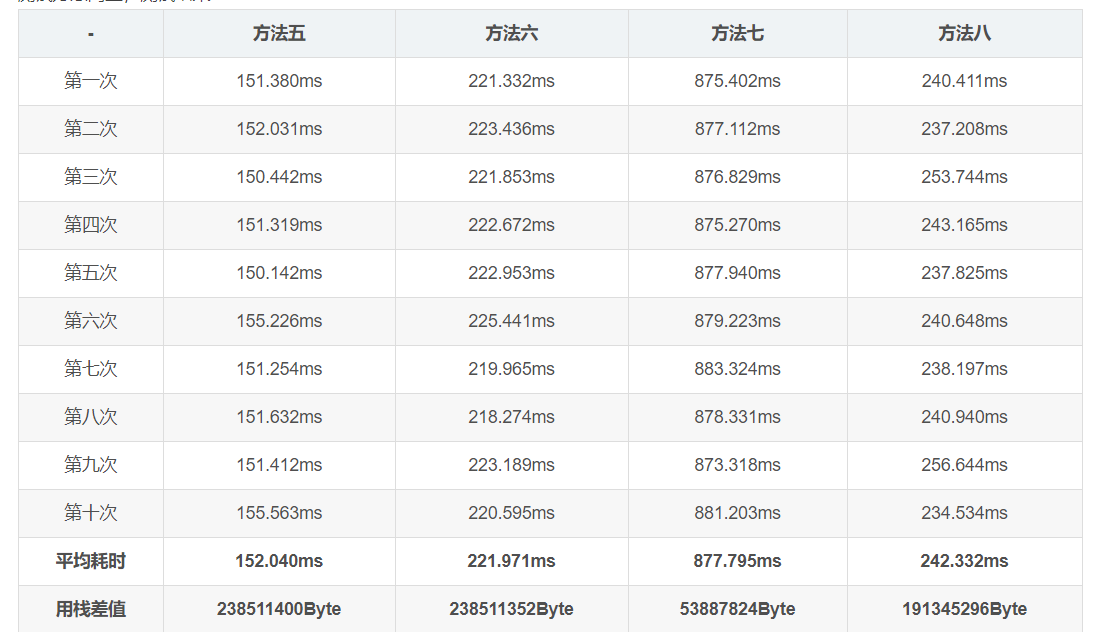
在`node`下,由上面的数据可以很明显的看出,`forEach`、`map`和`for of` 这些`ES6+`的语法并没有传统的`for`循环或者`while`循环快,特别是`map`方法。但是由于`map`有返回值,无需额外调用新数组的`push`方法,所以在执行浅拷贝任务上,内存占用很低。而`for of`语法在内存占用上也有一定的优势。
但是随着执行环境和浏览器的不同,这些语法在执行速度上也会出现偏差甚至反转的情况,直接看图: `谷歌浏览器` `火狐浏览器` `safari浏览器下` 可以看出:
谷歌浏览器中ES6+的循环语法会普遍比传统的循环语法慢,但是火狐和safari中情况却几乎相反。
谷歌浏览器的各种循环语法的执行耗时上差距并不大。但map特殊,速度明显比其他几种语法慢,而在火狐和safari中却出现了反转,map反而比较快!
顺便提一下:`for循环 while循环 for of 循环`是可以通过`break`关键字跳出的,而`forEach map`这种循环是无法跳出的。
总结
之前有听到过诸如“缓存数组长度可以提高循环效率”或者“ES6的循环语法更高效”的说法。抛开业务场景和使用便利性,单纯谈性能和效率是没有意义的。 ES6新增的诸多数组的方法确实极大的方便了前端开发,使得以往复杂或者冗长的代码,可以变得易读而且精炼,而好的for循环写法,在大数据量的情况下,确实也有着更好的兼容和多环境运行表现。当然本文的讨论也只是基于观察的一种总结,并没有深入底层。而随着浏览器的更新,这些方法的孰优孰劣也可能成为玄学。目前发现在Chrome Canary 70.0.3513.0下for of 会明显比Chrome 68.0.3440.84快。
本文的测试环境:node v10.8.0、Chrome 68.0.3440.84、Safari 11.1.2 (13605.3.8)、Firefox 60.0
原文:https://blog.csdn.net/haochuan9421/article/details/81414532
JS数组循环的性能和效率分析(for、while、forEach、map、for of)的更多相关文章
- js数组的五种迭代遍历方式 every filter forEach map some
ECMAScript 5 为数组定义了 5 个迭代方法. 每个方法都接收两个参数 数组项的值和索引 every():对数组中的每一项运行给定函数,如果该函数对每一项都返回 true,则返回 tru ...
- js 数组循环和迭代
(之前一直没怎么注意数组循环,今天做一道题时,用到forEach循环发现它并没有按照我想象的样子执行,总结一下数组循环) 一.第一种方法就是for()循环 for( var index = 0; ...
- js 各种循环的区别与用法(for in,forEach,for of)
1,forEach循环 不能跳过或者终止循环 const a = ["a","ss","cc"] a.dd="11" ...
- js数组去重与性能分析(时间复杂度很重要)
随着js的深入和实际项目对性能的要求,算法的简单实现已经不能满足需要,在不同的应用场景下,时间复杂度很重要. 首先是创建数组与性能处理函数: // 保证时间差的明显程度,创建不同量级的数组,size为 ...
- mustache.js 数组循环的索引
在使用mustache作为模板引擎时,想要利用数组中的对象的索引排序,却发现mustache中无法获得数组索引,在一番搜索之后,发现在数组的对象中加入索引,就可以了,示例如下 /html {{#dat ...
- js数组与对象性能比较
js的数组可以看成特殊的对象,获取指定项的行为跟获取对象中指定key对应项的行为是一致的. 一般都是hash map实现的,因而复杂度是常数级的.
- js 数组循环删除元素或对象
1.根据不同条件,删除数组中的元素或对象 for(var i=0,flag=true,len=attrList.length;i<len;flag ? i++ : i){ if(attrList ...
- 解决js数组循环删除出错
for(var i=0,flag=true,len=arr.length;i<len;flag ? i++ : i){ if( arr[i]&&arr[i].status==0 ...
- JS --- 数组循环要用length
socket.on("receive", function (data) { deviceone.print("返回的数据:"+data) // 发送异常 va ...
随机推荐
- Bmob后端云学习(未完)
Bmob后端云学习 BaaS(后端即服务:Backend as a Service)公司为移动应用开发者提供整合云后端的边界服务. 这种服务的一个代表就是Bmob后端云,BAT和亚马逊 ,都有这类产品 ...
- Tomcat zabbix监控、jmx监控、zabbix_java_gateway
几种方式监控tomcat,如标题. 下面就是参考的网上的连接.自己可以试一下. 由于牵扯到jvm的很多东西, 在这里就只是粘贴处连接参考. http://www.cnblogs.com/chrisDu ...
- sed 使用行号与关键字匹配限定行范围
1.打印匹配数字4 到最后一行 [111 sed]$ cat input [111 sed]$ sed -n '/4/,$p' input
- 027_git添加多账号设置
一. 注意事项: (1)公钥文件权限设置问题 现象: Permissions 0644 for '/Users/arunyang/.ssh/id_rsa_ele_me.pub' are too ope ...
- 023_supervisorctl管理服务注意事项
一. (1)问题 我在线上使用supervisorctl管理服务时遇到程序文件更新了,但是下次supervisorctl执行的时候并没有更新, 原因是supervisor更新后必须重新读取加载文件才行 ...
- Hibernate查询返回自定义VO的两种方式
说明:createQuery用的hql语句进行查询,createSQLQuery用sql语句查询: 前者以hibernate生成的Bean为对象装入list返回:后者则是以对象数组进行存储: 一.通过 ...
- 服务器与本地的控制工具unison
中文文档:https://wiki.archlinux.org/index.php/Unison_(%E7%AE%80%E4%BD%93%E4%B8%AD%E6%96%87) 下载:http://un ...
- python3列表(list)
一.列表(List) 定义:有序的可变的元素集合:通过range函数构造,在python3 中用的时候才会去构造 list = [1,2,3,4,5,'abc',['a',1,2,3],6,7] ...
- Web微信模拟
一.概要 目的:实现一个具有web微信类似功能的项目 框架:Django 模块:render.HttpResponse.BeautifulSoup.re.time.requests.json.rand ...
- GA:利用GA对一元函数进行优化过程,求x∈(0,10)中y的最大值——Jason niu
x = 0:0.01:10; y = x + 10*sin(5*x)+7*cos(4*x); figure plot(x, y) xlabel('independent variable') ylab ...