Linux filesystem
文件系统的运作与操作系统的文件数据有关。较新的操作系统的文件数据除了文件实际内容外,通常含有非常多的属性,例如Linux操作系统的文件权限(rwx)与文件属性(属主、属组、时间参数等)。文件系统通常会将这两部分数据存放在不同的区块,权限与属性放置到inode 中,实际数据则放置到data block 中。还有一个超级区块(superblock) 会记录整个文件系统的整体信息,包括inode与block 的总量、使用量、剩余量等。
由于每个inode与block都有编号,而每个文件都会占用一个inode,inode内则存有文件数据放置的block号码,因此,如果能够找到文件的inode,自然就能知道这个文件放置数据的block 号码,当然就能读取该文件的实际数据了。这种数据存取方法称为索引式文件系统(indexed allocation)。
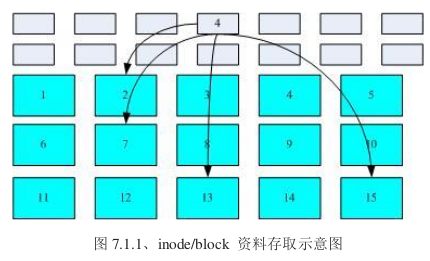
Ext2就是索引式文件系统。
文件系统一开始就将inode与block规划好了,除非重新格式化(或利用resize2fs等指令变更文件系统大小),否则inode 与block 固定后就不再变动。
data block:
data block 是用来放置文件内容数据的,在Ext2 文件系统中所支持的block 大小有1K,2K,4K 三种。在格式化时block 的大小就固定了,而且每个block 都有编号,以便inode 记录。由于block 大小的差异,会导致该文件系统能够支持的最大磁盘容量与最大单一文件容量并不相同。
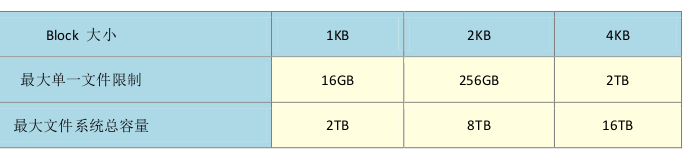
每个block 内最多只能放置一个文件的数据。
如果文件大于block 的大小,则一个文件会占用多个block。
如果文件小于block,则该block 的剩余容量就不能再存放其他文件。

至于到底该选择多大的block,师实际情况而定。
inode table:
inode 记录的文件数据至少有以下这些:
该文件的存取模式(read/write/excute)
该文件的属主与属组(owner/group)
该文件的容量
该文件创建或状态改变的时间(ctime)
最近一次的读取时间(atime)
最近一次的修改时间(mtime)
定义文件特性的flag,比如SetUID
该文件真正内容的指向(pointer)
inode 的数量与大小也在格式化时就固定了,
每个inode 大小均固定为128bytes(ext4 可设为256bytes)
每个文件只占用一个inode,因此文件系统能够建立的文件数量与inode数量有关
系统读取文件时,需要先找到inode,并分析inode 所记录的权限与用户是否符合,若符合才能够开始实际读取block 的内容。
Ext2 的inode/block 与文件大小的关系:
一个inode 大小为128bytes,而inode 记录一个block 号码要花掉4bytes。这时采取的策略是定义12个直接,一个间接,一个双间接,一个三间接记录区。


superblock:
记录的信息主要有以下这些:
block 与inode 的总量
未使用与已使用的inode/block 数量
block 与 inode 的大小(block 为1,2,4K,inode 为128,256bytes)
filesystem 的挂载时间、最近一次写入数据的时间、最近一次检验磁盘的时间等文件系统的相关信息。
一个valid bit 数值,若此文件系统已被挂载,则valid bit 为0,若未被挂载,则valid bit 为1。
superblock 的大小为1024bytes。
dumpe2fs: 查询Ext 家族superblock 信息的指令
df 与dumpe2fs 配合使用
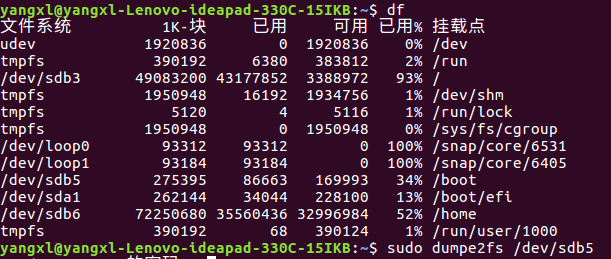
输出的部分结果:
Group 0: (Blocks 0-32767) # 第一块 block group 位置
Checksum 0x13be, unused inodes 8181
Primary superblock at 0, Group descriptors at 1-1 # 主要 superblock 的所在喔!
Reserved GDT blocks at 2-128
Block bitmap at 129 (+129), Inode bitmap at 145 (+145)
Inode table at 161-672 (+161) # inode table 的所在喔!
28521 free blocks, 8181 free inodes, 2 directories, 8181 unused inodes
Free blocks: 142-144, 153-160, 4258-32767 # 底下两行说明剩余的容量有多少
Free inodes: 12-8192

文件系统与目录树的关系
目录:
当在Linux下的文件系统创建一个目录时,文件系统会分配一个inode 与至少一块block 给该目录。其中,inode 记录该目录的相关权限与属性,并可记录分配到的那块block 号码;而block 则是记录在这个目录下的文件名与该文件名占用的inode 号码数据。

查看某目录内的文件所占用的inode 号码
ls -i
执行 ll / 命令,出现的目录几乎都是1024的整倍数,这还是与block的单位大小有关。
dr-xr-xr-x 253 root root 0 3月 20 09:42 proc/ # /proc 不占用磁盘容量,所以为0.
文件:
假设一个block 为4K,那么创建一个100K 的文件,除了分配一个inode 与25个block 来存储该文件外,还需要多一个block 来作为区块号码的记录(因为一个inode 仅有12个直接指向)
目录树读取:
inode 本身并不记录文件名,文件名的记录是在目录的block中。因此当我们要读取某个文件时,就会经过目录的inode 与block,然后才能找到那个待读取文件的inode 号码,最终才会读到文件的block 数据。
由于目录树是由根目录开始读起,因此系统通过挂载的信息可以找到挂载点的inode 号码,此时就能够得到根目录的inode 内容,并依据该inode 读取根目录的block 内的文件名数据,再一层一层往下读到正确的文件名。
以读取 /etc/passwd中的内容为例:
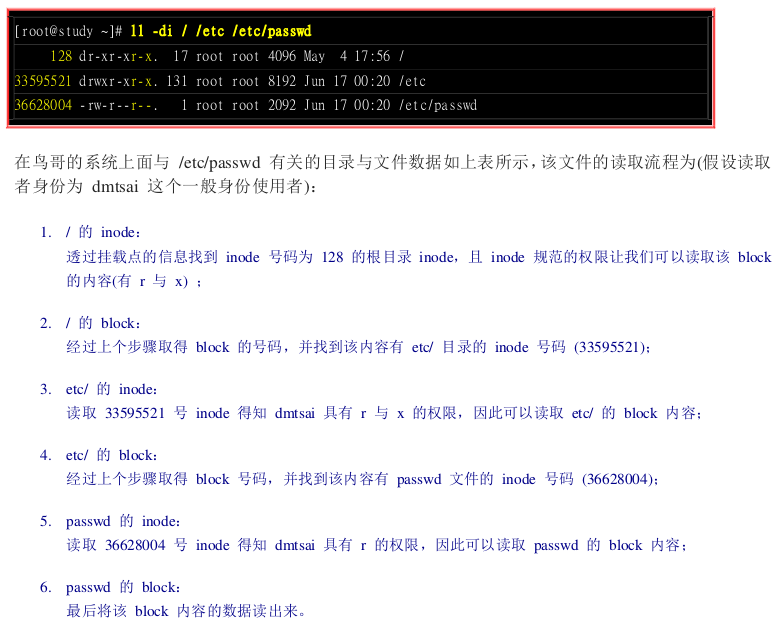
创建文件时文件系统的行为:
1). 先确定用户对于欲新增文件的目录是否具有w 和x 权限,若有的话才能新增
2). 根据inode bitmap 找到没有使用的inode 号码,并将新文件的权限/属性写入。
3). 根据block bitmap 找到没有使用的block 号码,并将实际的数据写入block 中,且更新inode 的block 指向数据。
4). 将刚刚写入的inode 与block 数据同步更新inode bitmap 与block bitmap,并更新superblock 的内容。
一般将inode table 与data table 称为数据存放区域,superblock、block bitmap、inode bitmap 称为metadata。
数据不一致状态:
一般情况下,上述新增动作可以顺利完成。但也有万一,例如在文件写入文件系统时,因为突然断电、系统核心发生错误等原因导致系统中断,所以写入的数据仅有inode table 及data block,而最后一个同步更新步骤没有完成,就会发生metadata 的内容与实际数据存放区产生不一致。
在早起的Ext2 文件系统中,如果发生数据不一致问题,那么系统在重新启动时,就会藉由superblock 中记录的valid bit(是否有挂载) 与filesystem state(clearn 与否)等状态来判断是否强制进行数据一致性检查。这个过程是很费时的。这就催生了日志式文件系统(Journaling filesystem)。
日志式文件系统:
在文件系统中另开辟一个区块,专门记录写入或修改时的步骤。
1). 预备:当系统要写入一个文件时,会先在日志记录区块中记录某个文件准备要写入的信息;
2). 实际写入:开始写入文件的权限与数据;更新metadata 的数据;
3. 结束:完成数据与metadata 的更新后,在日志记录区块中完成该文件的记录。
这样,在数据出现问题时,只要去检查日志记录区块,就可以知道哪个文件发生了问题,然后针对该问题做一致性检查即可,速度大大加快。
Ext3、Ext4就是日志式文件系统。通过dumpe2fs 可以看到superblock 里面含有下面的信息:
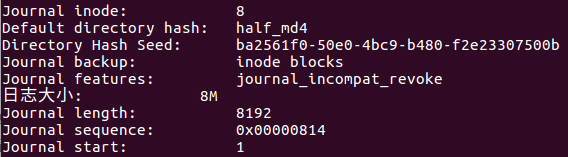
通过inode 8 记录journal 区块的block 指向,而且有8MB 的容量在处理日志。
磁盘写入的速度比内存慢得多,这会影响读写效率。为了解决这个问题,Linux有一个异步处理的方式。
当系统加载一个文件到内存后,如果该文件没有被更动过,则在内存区段的文件数据会被设定为干净的(clean)的。如果内存中文件数据被更动了,内存中的数据就会被设定为脏的(dirty),此时所有的动作都还在内存中,并没有写入磁盘,系统会不定时地将内存中设定为dirty的数据写回磁盘,以保持磁盘与内存数据的一致性。可以利用sync 指令来手动写入磁盘。
若正常关机,关机指令会主动调用sync 来将内存中的数据回写到磁盘。
每个filesystem 都有独立的inode/ block/ superblock 等信息,这个文件系统要能够链接到目录树才能被使用。将文件系统与目录树结合的动作称为挂载。挂载点一定是目录,该目录是进入该文件系统的入口。
查看系统支持哪些文件系统:
$ ls -l /lib/modules/$(uname -r)/kernel/fs
查看系统目前已加载到内存中文件系统:
$ cat /proc/filesystems
Linux 通过一个名叫Virtual Filesystem Switch(VFS) 的核心功能去管理filesystem。
Linux filesystem的更多相关文章
- 转载--linux filesystem structures
In this article, let us review the Linux filesystem structures and understand the meaning of individ ...
- buildroot linux filesystem 初探
/****************************************************************************** * buildroot linux fi ...
- RH033读书笔记(15)-Lab 16 The Linux Filesystem
Lab 16 The Linux Filesystem Goal: Develop a better understanding of Linux filesystem essentials incl ...
- Linux & Filesystem Hierarchy Standard
Linux & Filesystem Hierarchy Standard The Filesystem Hierarchy Standard of Linux https://zhuanla ...
- Linux filesystem structures.
1. / – Root Every single file and directory starts from the root directory. Only root user has write ...
- Linux filesystem detection
16 down vote accepted The reason you can't find it is because, for the most part, it's not in the ke ...
- Linux 基础
命令说明 $ type cmd # 获取命令类型 $ which cmd # 命令的位置 $ help cmd / cmd --help / man cmd # 获取命令帮助 $ whatis cmd ...
- Oracle Linux 5.7安装VMware Tools的问题
案例环境介绍: 虚拟机的版本:VMware® Workstation 8.0.3 build-703057 操作系统版本:Oracle Linux Server release 5.7 ...
- Linux File Recovery Study
Background Today I did stupid things that I went into the ~/Downloads/ and pressed [Alt] + [A] then ...
随机推荐
- HttpReponse
属性: django将请求报文中的请求行.头部信息.内容主体封装成 HttpRequest 类中的属性. 除了特殊说明的之外,其他均为只读的. 0.HttpRequest.scheme 表示请 ...
- 第八节,Opencv的基本使用------存取图像、视频功能、简单信息标注工具
1.存取图像 import cv2 img=cv2.imread('test.jpg') cv2.imwrite('test1.jpg',img) 2.图像的仿射变换 图像的仿射变换涉及图像的形状位置 ...
- php in_array() 循环大量数组时效率特别慢问题
in_array() 会循环数组内部元素逐个匹配,特别耗时,换成以下方式,效率大大提升
- Pytorch报错记录
1.BrokenPipeError 执行以下命令时: a,b = iter(train_loader).next() 报错:BrokenPipeError: [Errno 32] Broken pip ...
- Lua中的一些库(2)
[前言] 在<Lua中的一些库(1)>这篇文章中,总结了一部分Lua中的库函数,一篇文章肯定是总结不完的,所以,就来一个<Lua中的一些库(2)>.希望大家能忍住.来吧. 操作 ...
- Android开发之字体设置
默认字体 Android SDK自带了四种字体:"normal"“monospace",“sans”, “serif”,如下: 字体 看这四兄弟长的还是蛮像,我是看不 ...
- UI设计师给的px尺寸单位,安卓如何换算成dp?
很多UI工程师为了适配IOS,常常拿IOS手机作用参考模型,设计出来的UI稿只有PX标注的.他们也不懂Android的dp和sp单位是怎么回事.这个时候我们Android工程师如果不注意怎么转换的话, ...
- 阿里云学生服务器搭建网站-Ubuntu16.04安装php开发环境
阿里云学生服务器搭建网站(2)-Ubuntu16.04安装php开发环境 优秀博文:https://www.linuxidc.com/Linux/2016-10/136327.htm https:/ ...
- thinkPHP中M()和D()的区别
在实例化的过程中,经常使用D方法和M方法,这两个方法的区别在于M方法实例化模型无需用户为每个数据表定义模型类,如果D方法没有找到定义的模型类,则会自动调用M方法.通俗一点说:M实例化参数是数据库的表名 ...
- Python学习(三十七)—— 模板语言之自定义filter和中间件
一.模板语言之自定义filter 自定义filter文件存放位置 模板中自定义函数 - 在已注册的app中创建一个名字叫 templatetags 文件夹 - 任意创建一个py文件 - 创建名字交 r ...