【转载】详解一条sql语句的执行过程
转载自 https://www.cnblogs.com/cdf-opensource-007/p/6502556.html
SQL是一套标准,全称结构化查询语言,是用来完成和数据库之间的通信的编程语言,SQL语言是脚本语言,直接运行在数据库上。同时,SQL语句与数据在数据库上的存储方式无关,只是不同的数据库对于同一条SQL语句的底层实现不同罢了,但结果相同。这有点类似于java中接口的作用,一个接口可以有不同的实现类,不同的实现类对于接口中方法的实现方式可以不同,结果可以相同。这里SQL语言的作用就类似于java中的接口,数据库就类似于java中接口的实现类,SQL语句就类似于java接口中的方法。不同的是java中接口的不同实现类对于接口中方法的执行结果可以相同,也可以不同,而不同的数据库对于同一条SQL语句的执行是相同的。(这里只是做一个类比,方便我们理解)
一般情况下,大部分SQL语句在不同的数据库上是通用的,但我们知道每个数据库都有自己独有的特性,像在MySql数据库中,可以使用substr(取字符串),trim(去空格),ifnull(空值处理函数),还可以使用limit语句对数据库表进行截取,但这些都是oracle数据库没有的。(类比接口实现类中,实现类独有的方法,而接口中没有的)
这里简单介绍一下mysql数据库,mysql数据库是一款关系型数据库,所谓关系型数据库就是以二维表的形式存储数据,使用行和列方便我们对数据的增删改查。
这篇博客,我们以mysql数据库为例,对一条sql语句的执行流程进行分析。(本篇博客不涉及到表连接)
首先,创建一张student表,字段有自增主键id,学生姓名name,学科subject,成绩grade
建表语句:

DROP TABLE IF EXISTS student;
CREATE TABLE `student` (
`id` int(5) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
`subject` varchar(10) DEFAULT NULL,
`grade` double(4,1) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=40 DEFAULT CHARSET=utf8;
初始化数据:
INSERT INTO student(`name`,`subject`,grade)VALUES('aom','语文',88);
INSERT INTO student(`name`,`subject`,grade)VALUES('aom','数学',99);
INSERT INTO student(`name`,`subject`,grade)VALUES('aom','外语',55);
INSERT INTO student(`name`,`subject`,grade)VALUES('jack','语文',67);
INSERT INTO student(`name`,`subject`,grade)VALUES('jack','数学',44);
INSERT INTO student(`name`,`subject`,grade)VALUES('jack','外语',55);
INSERT INTO student(`name`,`subject`,grade)VALUES('susan','语文',56);
INSERT INTO student(`name`,`subject`,grade)VALUES('susan','数学',35);
INSERT INTO student(`name`,`subject`,grade)VALUES('susan','外语',77);
INSERT INTO student(`name`,`subject`,grade)VALUES('alice','语文',88);
INSERT INTO student(`name`,`subject`,grade)VALUES('alice','数学',77);
INSERT INTO student(`name`,`subject`,grade)VALUES('alice','外语',100);
INSERT INTO student(`name`,`subject`,grade)VALUES('rajo','语文',33);
INSERT INTO student(`name`,`subject`,grade)VALUES('rajo','数学',55);
INSERT INTO student(`name`,`subject`,grade)VALUES('rajo','外语',55);
下面我们来看一下,数据在数据库中的存储形式。
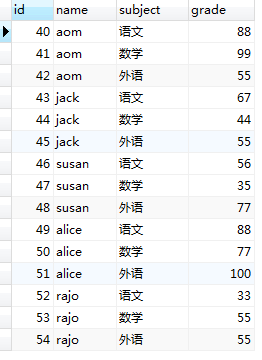
(图1.0)
现在针对这张student表中的数据提出一个问题:要求查询出挂科数目多于两门(包含两门)的前两名学生的姓名,如果挂科数目相同按学生姓名升序排列。
下面是这条查询的sql语句
SELECT `name`,COUNT(`name`) AS num FROM student WHERE grade < 60 GROUP BY `name` HAVING num >= 2 ORDER BY num DESC,`name` ASC LIMIT 0,2;
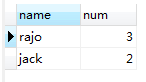
执行结果:
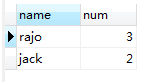
图(1.1)
以上这条sql语句基本上概括了单表查询中所有要注意的点,那么我们就以这条sql为例来分析一下一条语句的执行流程。
1,一条查询的sql语句先执行的是 FROM student 负责把数据库的表文件加载到内存中去,如图1.0中所示。(mysql数据库在计算机上也是一个进程,cpu会给该进程分配一块内存空间,在计算机‘服务’中可以看到,该进程的状态)

图(1.2)
2,WHERE grade < 60,会把(图1.0)所示表中的数据进行过滤,取出符合条件的记录行,生成一张临时表,如下图所示。
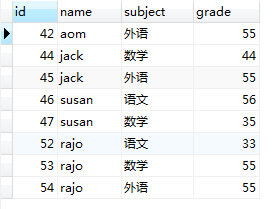
图(1.3)
3,GROUP BY `name`会把图(1.3)的临时表切分成若干临时表,我们用下图来表示内存中这个切分的过程。

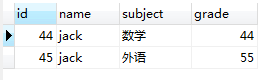
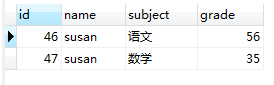
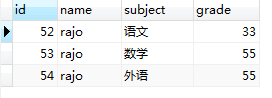
图(1.4) 图(1.5) 图(1.6) 图(1.7)
4,SELECT 的执行读取规则分为sql语句中有无GROUP BY两种情况。
(1)当没有GROUP BY时,SELECT 会根据后面的字段名称对内存中的一张临时表整列读取。
(2)当查询sql中有GROUP BY时,会对内存中的若干临时表分别执行SELECT,而且只取各临时表中的第一条记录,然后再形成新的临时表。这就决定了查询sql使用GROUP BY的场景下,SELECT后面跟的一般是参与分组的字段和聚合函数,否则查询出的数据要是情况而定。另外聚合函数中的字段可以是表中的任意字段,需要注意的是聚合函数会自动忽略空值。
我们还是以本例中的查询sql来分析,现在内存中有四张被GROUP BY `name`切分成的临时表,我们分别取名为 tempTable1,tempTable2,tempTable3,tempTable4分别对应图(1.4)、图(1.5)、图(1.6),图(1.7)下面写四条"伪SQL"来说明这个查询过程。
SELECT `name`,COUNT(`name`) AS num FROM tempTable1;
SELECT `name`,COUNT(`name`) AS num FROM tempTable2;
SELECT `name`,COUNT(`name`) AS num FROM tempTable3;
SELECT `name`,COUNT(`name`) AS num FROM tempTable4;
最后再次成新的临时表,如下图:

图(1.8)
5,HAVING num >= 2对上图所示临时表中的数据再次过滤,与WHERE语句不同的是HAVING 用在GROUP BY之后,WHERE是对FROM student从数据库表文件加载到内存中的原生数据过滤,而HAVING 是对SELECT 语句执行之后的临时表中的数据过滤,所以说column AS otherName ,otherName这样的字段在WHERE后不能使用,但在HAVING 后可以使用。但HAVING的后使用的字段只能是SELECT 后的字段,SELECT后没有的字段HAVING之后不能使用。HAVING num >= 2语句执行之后生成一张临时表,如下:
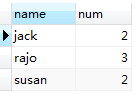
图(1.9)
6,ORDER BY num DESC,`name` ASC对以上的临时表按照num,name进行排序。
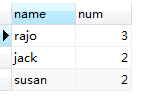
7,LIMIT 0,2取排序后的前两个。
以上就是一条sql的执行过程,同时我们在书写查询sql的时候应当遵守以下顺序。
SELECT XXX FROM XXX WHERE XXX GROUP BY XXX HAVING XXX ORDER BY XXX LIMIT XXX;
最后说一点,我们作为程序员,研究问题还是要仔细深入一点的。当你对原理了解的有够透彻,开发起来也就得心应手了,很多开发中的问题和疑惑也就迎刃而解了,而且在面对其他问题的时候也可做到触类旁通。当然在开发中没有太多的时间让你去研究原理,开发中要以实现功能为前提,可等项目上线的后,你有大把的时间或者空余的时间,你大可去刨根问底,深入的去研究一项技术,为觉得这对一名程序员的成长是很重要的事情。
【转载】详解一条sql语句的执行过程的更多相关文章
- mysql(1)—— 详解一条sql语句的执行过程
SQL是一套标准,全称结构化查询语言,是用来完成和数据库之间的通信的编程语言,SQL语言是脚本语言,直接运行在数据库上.同时,SQL语句与数据在数据库上的存储方式无关,只是不同的数据库对于同一条SQL ...
- 详解一条sql语句的执行过程
SQL是一套标准,全称结构化查询语言,是用来完成和数据库之间的通信的编程语言,SQL语言是脚本语言,直接运行在数据库上.同时,SQL语句与数据在数据库上的存储方式无关,只是不同的数据库对于同一条SQL ...
- 一条sql语句的执行过程
一条select语句执行流程 第一步:连接器 连接器负责跟客户端建立连接.获取权限.维持和管理连接.如果用户名密码验证通过后,连接器会到权限表里面查出你拥有的权限.之后该连接的权限验证都依赖于刚查出来 ...
- mysql一条sql语句如何执行的?
mysql 一条sql语句如何执行的? 文章内容源自:极客时间-林晓彬老师-MySQL实战45讲 学习整理 在了解一条查询语句如何执行之前,需要了解下MySQL的基本架构是怎样的,如下图所示: 可以看 ...
- ORACLE数据库SQL语句的执行过程
SQL语句在数据库中处理过程是怎样的呢?执行顺序呢?在回答这个问题前,我们先来回顾一下:在ORACLE数据库系统架构下,SQL语句由用户进程产生,然后传到相对应的服务端进程,之后由服务器进程执行该SQ ...
- 共享内存shared pool (5):详解一条SQL在library cache中解析
前面介绍的 shared pool,library cache结构,都是为了说明一条SQL是如何被解析的.先看下面的图: 图中涉及的各结构简单介绍 父HANDLE,里面有父游标堆0的地址.. 父游标堆 ...
- 共享池之八:软解析、硬解析、软软解析 详解一条SQL在library cache中解析涉及的锁
先来张大图: 结合上图来说明一下解析的各个步骤涉及的锁. 软解析.硬解析.软软解析区别的简单说明: 为了将用户写的sql文本转化为oracle认识的且可执行的语句,这个过程就叫做解析过程. 解析分为硬 ...
- 详细分析SQL语句逻辑执行过程和相关语法
本文目录: 1.SQL语句的逻辑处理顺序 1.2 各数据库系统的语句逻辑处理顺序 1.2.1 SQL Server和Oracle的逻辑执行顺序 1.2.2 MariaDB的逻辑执行顺序 1.2.3 M ...
- 深入学习MySQL 01 一条查询语句的执行过程
在学习SpringCloud的同时,也在深入学习MySq中,听着<mysql45讲>,看着<高性能MySQL>,本系列文章是本人学习过程的总结,水平有限,仅供参考,若有不对之处 ...
随机推荐
- 2019年11个javascript机器学习库
Credits: aijs.rocks 虽然python或r编程语言有一个相对容易的学习曲线,但是Web开发人员更喜欢在他们舒适的javascript区域内做事情.目前来看,node.js已经开始向每 ...
- 使用sshpass同时更新一台ubuntu和一台CentOS
1.在ubuntu上安装sshpass sudo apt install sshpass 2.分别在两台的root路径下放上升级脚本: cent:/root/upgrade.sh #!/bin/bas ...
- 大规模使用 Apache Kafka 的20个最佳实践
必读 | 大规模使用 Apache Kafka 的20个最佳实践 配图来源:书籍<深入理解Kafka> Apache Kafka是一款流行的分布式数据流平台,它已经广泛地被诸如New Re ...
- [CTSC2017]网络
[CTSC2017]网络 连一条长度为len的边,使得基环树的直径最小 结论:一定连在某条直径两个点上(否则更靠近不劣) 然后二分答案判定. dp[i]:链上一个点往下延伸的最大深度 考虑对于任意两个 ...
- mysql 严格模式 Strict Mode说明(text 字段不能加默认或者 不能加null值得修改方法)
mysql 严格模式 Strict Mode说明 1.开启与关闭Strict Mode方法找到mysql安装目录下的my.cnf(windows系统则是my.ini)文件 在sql_mode中加入ST ...
- hbase-default.xml(Hbase 默认参数翻译)
hbase.tmp.dir \({java.io.tmpdir}/hbase-\){user.name} 本地文件系统上的临时目录.将'/tmp'改为其他可以持久保存文件的位置,通常能够解决java. ...
- JAVA之锁-cas
CAS是什么? CAS是英文单词CompareAndSwap的缩写,中文意思是:比较并替换.CAS需要有3个操作数:内存地址V,旧的预期值A,即将要更新的目标值B. CAS指令执行时,当且仅当内存地址 ...
- Thunk
Thunk https://en.wikipedia.org/wiki/Thunk In computer programming, a thunk is a subroutine used to i ...
- hibernate之一对多,多对一
配置文件 <!--一对多--><!--name:集合属性名字 column:外键列名 class:与它相关的对象的完整列名 cascade:级联操作:分3种 save-update: ...
- pyQt5不让进度条卡住
这里我们用一个更新程序做示例, 下载文件的过程中让进度条实时显示下载进度. 如果下载和更新进度条的工作都放在一个线程中,会出现进度条卡顿的情况. Qt中正确的做法是把界面刷新和工作任务交给不同的线程去 ...