Redis 和 I/O 多路复用
最近在看 UNIX 网络编程并研究了一下 Redis 的实现,感觉 Redis 的源代码十分适合阅读和分析,其中 I/O 多路复用(mutiplexing)部分的实现非常干净和优雅,在这里想对这部分的内容进行简单的整理。
几种 I/O 模型
为什么 Redis 中要使用 I/O 多路复用这种技术呢?
首先,Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现的。
Blocking I/O
先来看一下传统的阻塞 I/O 模型到底是如何工作的:当使用 read 或者 write 对某一个文件描述符(File Descriptor 以下简称 FD)进行读写时,如果当前 FD 不可读或不可写,整个 Redis 服务就不会对其它的操作作出响应,导致整个服务不可用。
这也就是传统意义上的,也就是我们在编程中使用最多的阻塞模型:

阻塞模型虽然开发中非常常见也非常易于理解,但是由于它会影响其他 FD 对应的服务,所以在需要处理多个客户端任务的时候,往往都不会使用阻塞模型。
I/O 多路复用
虽然还有很多其它的 I/O 模型,但是在这里都不会具体介绍。
阻塞式的 I/O 模型并不能满足这里的需求,我们需要一种效率更高的 I/O 模型来支撑 Redis 的多个客户(redis-cli),这里涉及的就是 I/O 多路复用模型了:
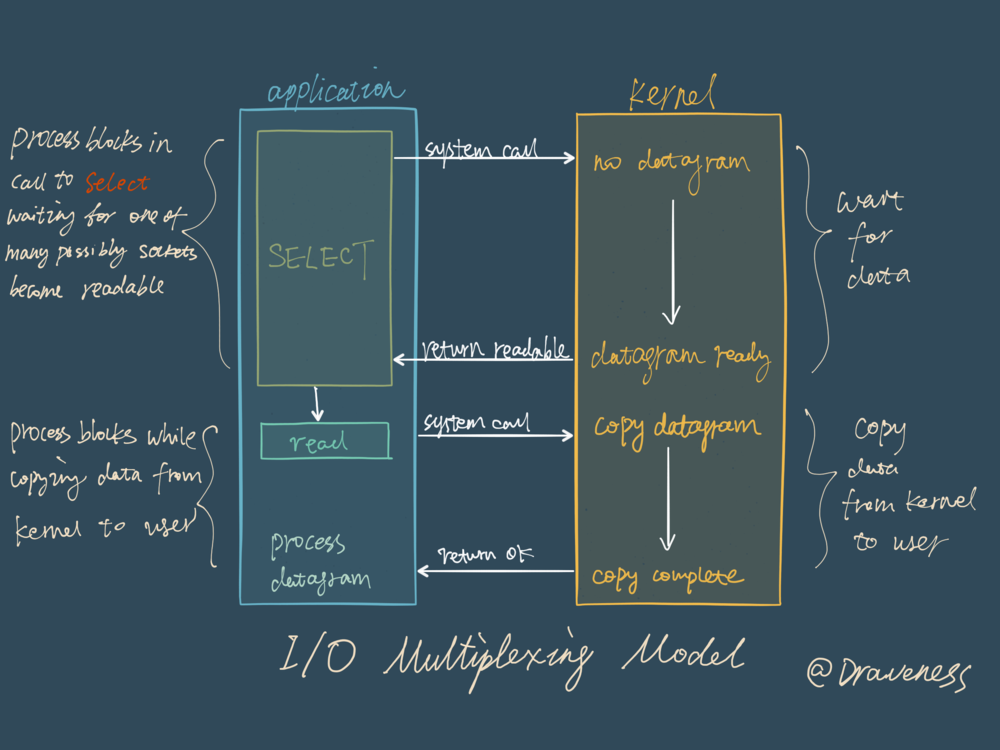
在 I/O 多路复用模型中,最重要的函数调用就是 select,该方法的能够同时监控多个文件描述符的可读可写情况,当其中的某些文件描述符可读或者可写时,select 方法就会返回可读以及可写的文件描述符个数。
关于
select的具体使用方法,在网络上资料很多,这里就不过多展开介绍了;与此同时也有其它的 I/O 多路复用函数
epoll/kqueue/evport,它们相比select性能更优秀,同时也能支撑更多的服务。
Reactor 设计模式
Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符)
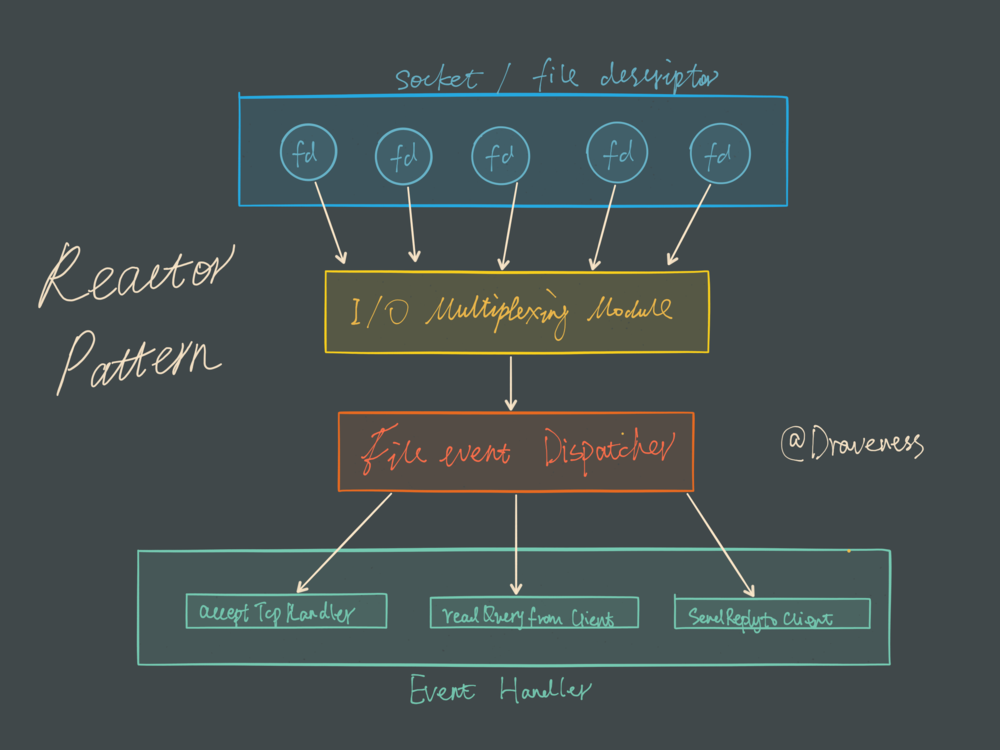
文件事件处理器使用 I/O 多路复用模块同时监听多个 FD,当 accept、read、write 和 close 文件事件产生时,文件事件处理器就会回调 FD 绑定的事件处理器。
虽然整个文件事件处理器是在单线程上运行的,但是通过 I/O 多路复用模块的引入,实现了同时对多个 FD 读写的监控,提高了网络通信模型的性能,同时也可以保证整个 Redis 服务实现的简单。
I/O 多路复用模块
I/O 多路复用模块封装了底层的 select、epoll、avport 以及 kqueue 这些 I/O 多路复用函数,为上层提供了相同的接口。
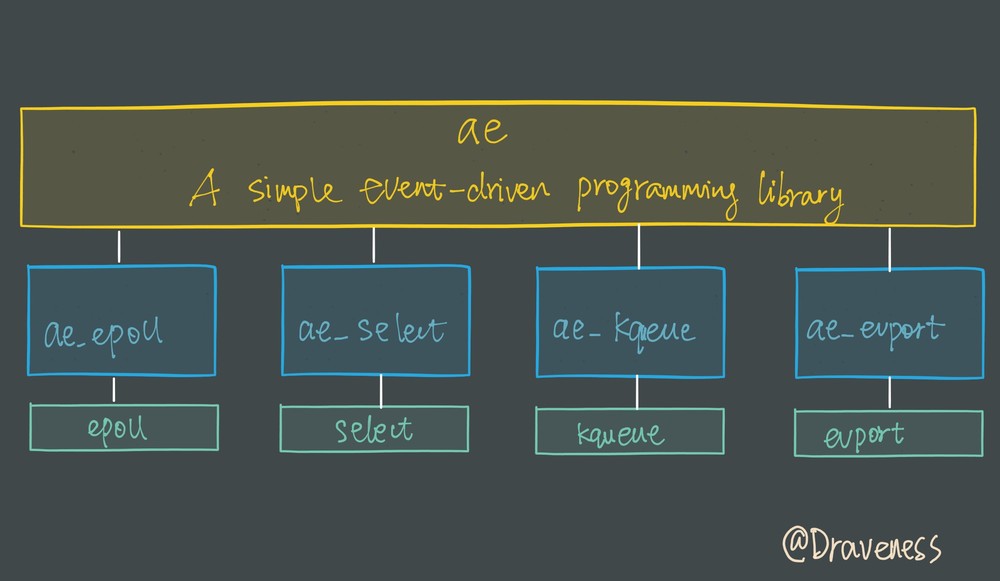
在这里我们简单介绍 Redis 是如何包装 select 和 epoll 的,简要了解该模块的功能,整个 I/O 多路复用模块抹平了不同平台上 I/O 多路复用函数的差异性,提供了相同的接口:
static int aeApiCreate(aeEventLoop *eventLoop)static int aeApiResize(aeEventLoop *eventLoop, int setsize)static void aeApiFree(aeEventLoop *eventLoop)static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask)static void aeApiDelEvent(aeEventLoop *eventLoop, int fd, int mask)static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp)
同时,因为各个函数所需要的参数不同,我们在每一个子模块内部通过一个 aeApiState 来存储需要的上下文信息:
// select
typedef struct aeApiState {
fd_set rfds, wfds;
fd_set _rfds, _wfds;
} aeApiState;
// epoll
typedef struct aeApiState {
int epfd;
struct epoll_event *events;
} aeApiState;
这些上下文信息会存储在 eventLoop 的 void *state 中,不会暴露到上层,只在当前子模块中使用。
封装 select 函数
select可以监控 FD 的可读、可写以及出现错误的情况。
在介绍 I/O 多路复用模块如何对 select 函数封装之前,先来看一下 select 函数使用的大致流程:
int fd = /* file descriptor */
fd_set rfds;
FD_ZERO(&rfds);
FD_SET(fd, &rfds)
for ( ; ; ) {
select(fd+1, &rfds, NULL, NULL, NULL);
if (FD_ISSET(fd, &rfds)) {
/* file descriptor `fd` becomes readable */
}
}
- 初始化一个可读的
fd_set集合,保存需要监控可读性的 FD; - 使用
FD_SET将fd加入rfds; - 调用
select方法监控rfds中的 FD 是否可读; - 当
select返回时,检查 FD 的状态并完成对应的操作。
而在 Redis 的 ae_select 文件中代码的组织顺序也是差不多的,首先在 aeApiCreate 函数中初始化 rfds 和 wfds:
static int aeApiCreate(aeEventLoop *eventLoop) {
aeApiState *state = zmalloc(sizeof(aeApiState));
if (!state) return -1;
FD_ZERO(&state->rfds);
FD_ZERO(&state->wfds);
eventLoop->apidata = state;
return 0;
}
而 aeApiAddEvent 和 aeApiDelEvent 会通过 FD_SET 和 FD_CLR 修改 fd_set 中对应 FD 的标志位:
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
if (mask & AE_READABLE) FD_SET(fd,&state->rfds);
if (mask & AE_WRITABLE) FD_SET(fd,&state->wfds);
return 0;
}
整个 ae_select 子模块中最重要的函数就是 aeApiPoll,它是实际调用 select 函数的部分,其作用就是在 I/O 多路复用函数返回时,将对应的 FD 加入 aeEventLoop 的 fired 数组中,并返回事件的个数:
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
aeApiState *state = eventLoop->apidata;
int retval, j, numevents = 0;
memcpy(&state->_rfds,&state->rfds,sizeof(fd_set));
memcpy(&state->_wfds,&state->wfds,sizeof(fd_set));
retval = select(eventLoop->maxfd+1,
&state->_rfds,&state->_wfds,NULL,tvp);
if (retval > 0) {
for (j = 0; j <= eventLoop->maxfd; j++) {
int mask = 0;
aeFileEvent *fe = &eventLoop->events[j];
if (fe->mask == AE_NONE) continue;
if (fe->mask & AE_READABLE && FD_ISSET(j,&state->_rfds))
mask |= AE_READABLE;
if (fe->mask & AE_WRITABLE && FD_ISSET(j,&state->_wfds))
mask |= AE_WRITABLE;
eventLoop->fired[numevents].fd = j;
eventLoop->fired[numevents].mask = mask;
numevents++;
}
}
return numevents;
}
封装 epoll 函数
Redis 对 epoll 的封装其实也是类似的,使用 epoll_create 创建 epoll 中使用的 epfd:
static int aeApiCreate(aeEventLoop *eventLoop) {
aeApiState *state = zmalloc(sizeof(aeApiState));
if (!state) return -1;
state->events = zmalloc(sizeof(struct epoll_event)*eventLoop->setsize);
if (!state->events) {
zfree(state);
return -1;
}
state->epfd = epoll_create(1024); /* 1024 is just a hint for the kernel */
if (state->epfd == -1) {
zfree(state->events);
zfree(state);
return -1;
}
eventLoop->apidata = state;
return 0;
}
在 aeApiAddEvent 中使用 epoll_ctl 向 epfd 中添加需要监控的 FD 以及监听的事件:
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
struct epoll_event ee = {0}; /* avoid valgrind warning */
/* If the fd was already monitored for some event, we need a MOD
* operation. Otherwise we need an ADD operation. */
int op = eventLoop->events[fd].mask == AE_NONE ?
EPOLL_CTL_ADD : EPOLL_CTL_MOD;
ee.events = 0;
mask |= eventLoop->events[fd].mask; /* Merge old events */
if (mask & AE_READABLE) ee.events |= EPOLLIN;
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;
ee.data.fd = fd;
if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return -1;
return 0;
}
由于 epoll 相比 select 机制略有不同,在 epoll_wait 函数返回时并不需要遍历所有的 FD 查看读写情况;在 epoll_wait 函数返回时会提供一个 epoll_event 数组:
typedef union epoll_data {
void *ptr;
int fd; /* 文件描述符 */
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll 事件 */
epoll_data_t data;
};
其中保存了发生的
epoll事件(EPOLLIN、EPOLLOUT、EPOLLERR和EPOLLHUP)以及发生该事件的 FD。
aeApiPoll 函数只需要将 epoll_event 数组中存储的信息加入 eventLoop 的 fired 数组中,将信息传递给上层模块:
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
aeApiState *state = eventLoop->apidata;
int retval, numevents = 0;
retval = epoll_wait(state->epfd,state->events,eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1);
if (retval > 0) {
int j;
numevents = retval;
for (j = 0; j < numevents; j++) {
int mask = 0;
struct epoll_event *e = state->events+j;
if (e->events & EPOLLIN) mask |= AE_READABLE;
if (e->events & EPOLLOUT) mask |= AE_WRITABLE;
if (e->events & EPOLLERR) mask |= AE_WRITABLE;
if (e->events & EPOLLHUP) mask |= AE_WRITABLE;
eventLoop->fired[j].fd = e->data.fd;
eventLoop->fired[j].mask = mask;
}
}
return numevents;
}
子模块的选择
因为 Redis 需要在多个平台上运行,同时为了最大化执行的效率与性能,所以会根据编译平台的不同选择不同的 I/O 多路复用函数作为子模块,提供给上层统一的接口;在 Redis 中,我们通过宏定义的使用,合理的选择不同的子模块:
#ifdef HAVE_EVPORT
#include "ae_evport.c"
#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c"
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c"
#else
#include "ae_select.c"
#endif
#endif
#endif
因为 select 函数是作为 POSIX 标准中的系统调用,在不同版本的操作系统上都会实现,所以将其作为保底方案:
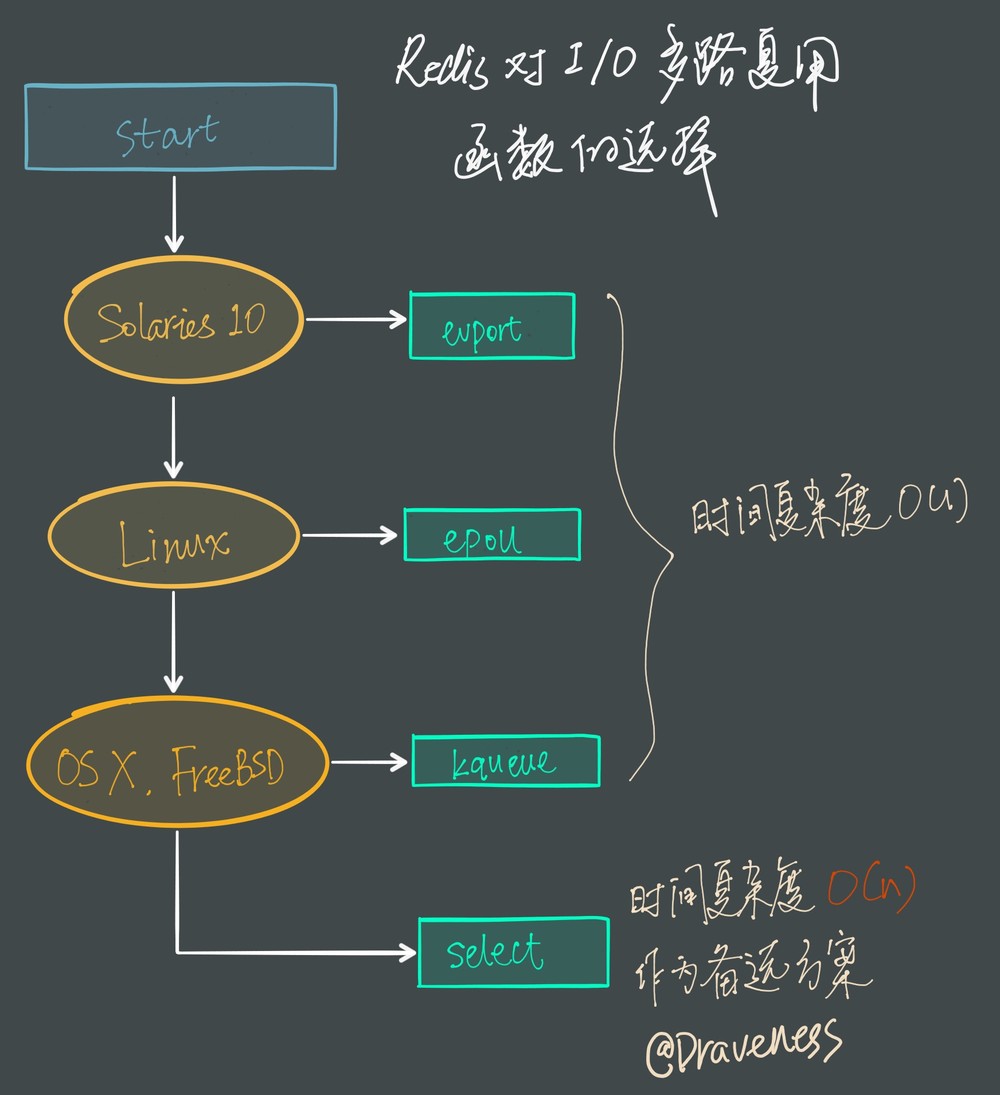
Redis 会优先选择时间复杂度为 $O(1)$ 的 I/O 多路复用函数作为底层实现,包括 Solaries 10 中的 evport、Linux 中的 epoll 和 macOS/FreeBSD 中的 kqueue,上述的这些函数都使用了内核内部的结构,并且能够服务几十万的文件描述符。
但是如果当前编译环境没有上述函数,就会选择 select 作为备选方案,由于其在使用时会扫描全部监听的描述符,所以其时间复杂度较差 $O(n)$,并且只能同时服务 1024 个文件描述符,所以一般并不会以 select 作为第一方案使用。
总结
Redis 对于 I/O 多路复用模块的设计非常简洁,通过宏保证了 I/O 多路复用模块在不同平台上都有着优异的性能,将不同的 I/O 多路复用函数封装成相同的 API 提供给上层使用。
整个模块使 Redis 能以单进程运行的同时服务成千上万个文件描述符,避免了由于多进程应用的引入导致代码实现复杂度的提升,减少了出错的可能性。
转自:https://draveness.me/redis-io-multiplexing
Redis 和 I/O 多路复用的更多相关文章
- redis的多路复用是什么鬼
有没有人和我一样, 自打知道了redis, 就一直听说什么redis单线程, 使用了多路复用等等. 天真的我以为多路复用是redis实现的技术. 今天才发现, 我被自己骗了, 多路复用是系统来实现的. ...
- Redis I/O 多路复用技术原理
引言 Redis 是一个单线程却性能非常好的内存数据库, 主要用来作为缓存系统. Redis 采用网络 I/O 多路复用技术来保证在多个连接时,系统的高吞吐量(TPS). 系统吞吐量(TPS)指的是系 ...
- Redis构建分布式锁
1.前言 为什么要构建锁呢?因为构建合适的锁可以在高并发下能够保持数据的一致性,即客户端在执行连贯的命令时上锁的数据不会被别的客户端的更改而发生错误.同时还能够保证命令执行的成功率. 看到这里你不禁要 ...
- Redis常见的应用场景解析
Redis是一个key-value存储系统,现在在各种系统中的使用越来越多,大部分情况下是因为其高性能的特性,被当做缓存使用,这里介绍下Redis经常遇到的使用场景. Redis特性 一个产品的使用场 ...
- Redis线程模型
Redis 基于 Reactor 模式开发了自己的网络事件处理器: 这个处理器被称为文件事件处理器(file event handler): 文件事件处理器使用 I/O 多路复用(multiplexi ...
- Redis之基本使用
基本介绍 Redis是一种key-value存储形式的非关系型数据库,也是一个强大的内存型存储系统,但是它比传统的Memcached 更灵活,支持更多的数据类型,同时也可以持久化. 支持的数据类型 先 ...
- redis知识点汇总
1. redis是什么 2. 为什么用redis 3. redis 数据结构 4. redis中的对象类型 5. redis都能做什么?怎么实现的的? 6. redis使用过程中需要注意什么 7. 数 ...
- 关于Redis处理高并发
Redis的高并发和快速原因 1.Redis是基于内存的,内存的读写速度非常快: 2.Redis是单线程的,省去了很多上下文切换线程的时间: 3.Redis使用多路复用技术,可以处理并发的连接.非阻塞 ...
- 分布式之redis核心知识盘点?
考虑到绝大部分写业务的程序员,在实际开发中使用redis的时候,只会setvalue和getvalue两个操作,对redis整体缺乏一个认知.又恰逢博主某个同事下周要去培训redis,所以博主斗胆以r ...
随机推荐
- 解决win环境下访问本机虚拟机中centos7 ftp服务器的问题
inux搭建ftp服务器 1.安装软件: yum install vsftpd 2.修改配置文件vsftpd.conf: vim /etc/vsftpd/vsftpd.conf 把anonymous_ ...
- Swoole入门到实战打造高性能赛事直播平台(完整版)
需要 的联系我,QQ:1844912514
- Vue.js 2.x笔记:路由Vue Router(6)
1. Vue Router简介与安装 1.1 Vue Router简介 Vue Router 是 Vue.js 官方的路由管理器.它和 Vue.js 的核心深度集成,构建单页面应用. Vue Rout ...
- [BZOJ 3227] [SDOI 2008] 红黑树(tree)
Description 红黑树是一类特殊的二叉搜索树,其中每个结点被染成红色或黑色.若将二叉搜索树结点中的空指针看作是指向一个空结点,则称这类空结点为二叉搜索树的前端结点.并规定所有前端结点的高度为- ...
- python多线程中join()方法和setDaemon()方法的区别
""" join()方法:主线程A中,创建了子线程B,并且在主线程中调用了B.join()方法,那么主线程A会在调用的地方等待,直到子线程B完成操作后,才可以接着往下执行 ...
- html-webpack-plugin不输出script标签的方法
那就是修改源码 约550行: if (!this.options.disableScript) { if (this.options.inject === 'head') { head = head. ...
- js获取当前url
1.window.location.href(设置或获取整个 URL 为字符串) 2.window.location.protocol(设置或获取 URL 的协议部分) 3.window.locati ...
- DFA确定有限状态自动机
DFA 在计算理论中,确定有限状态自动机或确定有限自动机(英语:deterministic finite automaton, DFA)是一个能实现状态转移的自动机.对于一个给定的属于该自动机的状态和 ...
- linux device drivers ch03
ch03.字符设备驱动程序 编写驱动程序的第一步就是定义驱动程序为用户程序提供的能力(机制).接下来以scull(“Simple Character Utility for Loading Local ...
- 【莫烦Pytorch】【P1】人工神经网络VS. 生物神经网络
滴:转载引用请注明哦[握爪] https://www.cnblogs.com/zyrb/p/9700343.html 莫烦教程是一个免费的机器学习(不限于)的学习教程,幽默风俗的语言让我们这些刚刚起步 ...