单机安装EFK(一)
环境信息

前话
去年下半年邻居介绍了一当兵的对象,当时是用生命拒绝的,然后过年回去居然鬼使神差的在一起了?过完年来,已经莫名失联十多天了,毕竟刚开始传说中的热恋就分开,心里难受!!!每天猜测这人是干嘛去了,患得患失,对于我这种一分钟不回复我消息我都觉得对方在出轨(这是被劈腿后遗症,越来越严重)。。。 这跟这篇博文有什么关系呢,没关系!
一、安装Elasticsearch
1、关闭防火墙
yum -y install firewalld
yum -y install iptables-services systemctl stop firewalld
systemctl stop iptables systemctl disable firewalld.service
systemctl disable iptables.service sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz
tar -zxvf jdk-8u131-linux-x64.tar.gz -C /usr/local
mv /usr/local/jdk1..0_131 /usr/local/java
2)vim /etc/profile
export JAVA_HOME=/usr/local/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:{JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source /etc/profile
[root@rilo ~]# echo $PATH
/usr/local/java/bin:/usr/local/java/jre/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@ip---- ~]# java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) -Bit Server VM (build 25.131-b11, mixed mode)
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.0.tar.gz tar -xvf elasticsearch-6.6..tar.gz cd elasticsearch-6.6./bin ./elasticsearch
useradd ela
chown -R ela.ela elasticsearch-6.6.
nohup ./elasticsearch &
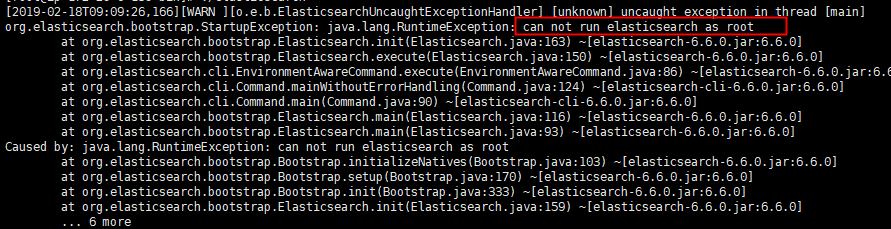

vm.max_map_count =
sysctl -p
network.host: 0.0.0.0
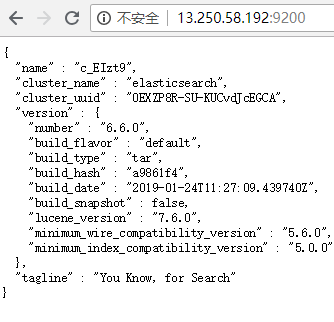
重启服务后,访问:http://13.250.58.192:9200/
二、安装Kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.6.0-linux-x86_64.tar.gz
tar -zxvf kibana-6.6.-linux-x86_64.tar.gz
cd kibana-6.6.-linux-x86_64
nohup ./bin/kibana &
3、查看Kibana进程
[root@ip---- ~]# ps -ef |grep node
root : pts/ :: ./../node/bin/node --no-warnings ./../src/cli
root : pts/ :: grep --color=auto node
[root@ip---- ~]# netstat -anltp |grep
tcp 127.0.0.1: 0.0.0.0:* LISTEN /./../node/bin
server.host: "0.0.0.0"
三、安装FileBeats
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.6.0-linux-x86_64.tar.gz
tar xzvf filebeat-6.6.-linux-x86_64.tar.gz
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
setup.kibana:
host: "localhost:5601"
output.elasticsearch:
hosts: ["localhost:9200"]
nohup ./filebeat &
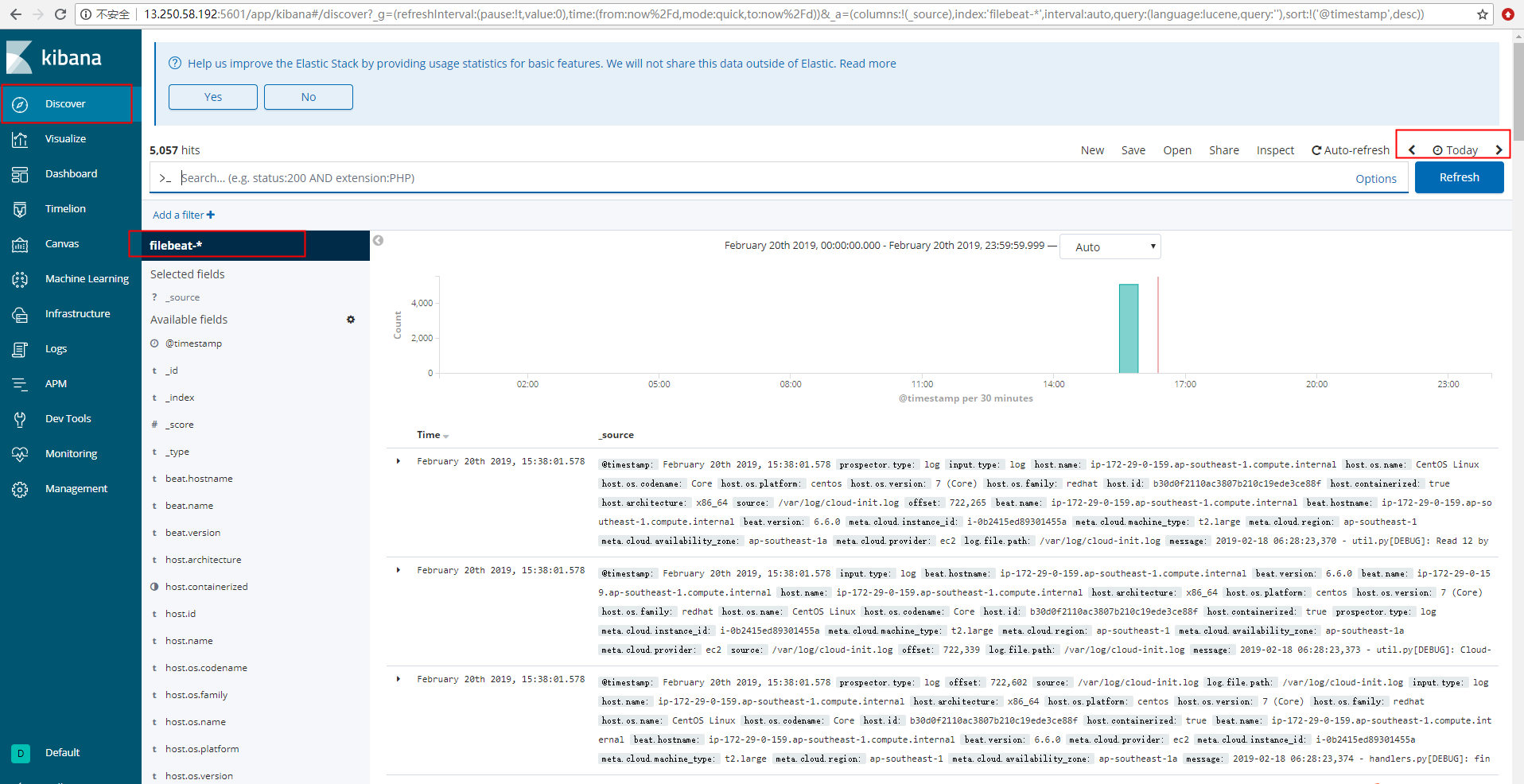
四、查看
单机安装EFK(一)的更多相关文章
- (原) 1.1 Zookeeper单机安装
本文为原创文章,转载请注明出处,谢谢 zookeeper 单机安装配置 1.安装前准备 linux系统(此文环境为Centos6.5) Zookeeper安装包,官网https://zookeeper ...
- Linux下Kafka单机安装配置方法(图文)
Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了 ...
- Ubuntu 下 Neo4j单机安装和集群环境安装
1. Neo4j简介 Neo4j是一个用Java实现的.高性能的.NoSQL图形数据库.Neo4j 使用图(graph)相关的概念来描述数据模型,通过图中的节点和节点的关系来建模.Neo4j完全兼容A ...
- Hbase单机安装部署
Hbase单机安装部署 http://blogxinxiucan.sh1.newtouch.com/2017/07/27/Hbase单机安装部署/ 下载Hbase Hbase官网下载地址 http:/ ...
- 单机安装Hadoop
单机安装hadoop ------------------------------------------------------------------ 操作系统:centos7 64 位 hado ...
- cenots7单机安装Kubernetes
关于什么是Kubernetes请看另一篇内容:http://www.cnblogs.com/boshen-hzb/p/6482734.html 一.环境搭建 master安装的组件有: docker ...
- Linux下Kafka单机安装配置方法
Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语: •Kafka将消息以topi ...
- ETCD 单机安装
由于测试的需要,有时需要搭建一个单机版的etcd 环境,为了方便以后搭建查看,现在对单机部署进行记录. 一.部署单机etcd 下载 指定版本的etcd下载地址 ftp://ftp.pbone.net/ ...
- ArcGIS 10.1 for Server安装教程系列—— Linux下的单机安装
http://www.oschina.net/question/565065_81231 因为Linux具有稳定,功能强大等特性,因此常常被用来做为企业内部的服务器,我们的很多用户也是将Ar ...
随机推荐
- moment.js
javascript日期处理类库,还有一个moment-timezone.js JavaScript时区处理类库 moment可以在browser和Node.js中使用. 安装: npm instal ...
- 如何在linux环境安装数据库
1.1 获取oracle 数据库安装包: 注意:获取的是database的安装包,不是客户端的安装包 1.2 以root用户登陆云主机,修改主机名 Hostname 1.2.1 ...
- dede织梦系统接入熊掌号推送api,完整详细教程
第一步: 根据熊掌号要求完成校验页面,官方文档很详细,照着弄就行了 第二步: 开始后台改造 1.进入后台文件夹dede(自己实际的文件夹),然后进入templets目录,打开body_inde ...
- mac 内置PHP配置多站点
1.修改/private/etc/hosts 文件,建议用编辑器打开 最后一行加入你的网站名称(自定义),参考如下: 127.0.0.1 www.MyObj.com 2.修改/private/et ...
- Sublime Text 3利用Snippet创建Getter和Setter
1. Tools -> Developer -> New Snippet. 2. 复制以下内容并保存: <snippet> <content><![CDATA ...
- idea 引入web、配制tomcat
引入web包: https://www.cnblogs.com/chenloveslife/p/8973912.html 配置tomcat:https://blog.csdn.net/qq_33257 ...
- Strongly connected components
拓扑排列可以指明除了循环以外的所有指向,当反过来还有路可以走的话,说明有刚刚没算的循环路线,所以反过来能形成的所有树都是循环
- @RequestMapping、@ResponseBody和@RequestBody的使用
使用SSM框架进行Web开发时,经常在Controller中遇到@RequestMapping.@ResponseBody和@RequestMapping注解. 1.@RequsetMapping注解 ...
- Classnotfoundexception 与 noClassDelfaultError的区别
ClassNotFoundException 这个异常特别常见,就是class找不到异常,一般的问题就是: 1 调用class的forName方法时,找不到指定的类 2 ClassLoader 中的 ...
- yamux多路复用的使用例子
yamux yamux 是一个多路复用库.它依赖于底层可靠有序连接.如TCP. 提供基于流的多路利用 例子如下: Server package main // 多路复用 import ( " ...