利用python实现两个文件夹的同步
其实无论windows还是Linux,简单地去实现两个两个文件夹的同步只需系统自带的复制命令加参数就可以了。
- WINDOWS :
xcopy 源文件夹\* 目标文件夹 /s /e /y
- Linux :
cp -r 源文件夹/* 目标文件夹
这里使用python来实现这些基本功能,并增加一些去重之类的增强功能。
1、复制源文件夹中文件至目标文件夹
要想同步两个文件夹中的数据,基本思路首先需要遍历源文件夹中的信息,将源文件夹中的文件复制到目标文件夹。
遍历文件夹采用os中的listdir函数就可以了。
import os path_s = 'F:\\test\\s'
path_t = 'F:\\test\\t' for filename in os.listdir(path_s):
filename_s = path_s+os.sep+filename
print '[*] Source :',filename_s
filename_t = path_t+os.sep+filename
print '[*] Target :',filename_t
with open(filename_s,'rb') as f_s:
with open(filename_t,'wb') as f_t:
f_t.write(f_s.read())
但是很明显这里没有考虑源文件夹中还会存在文件夹甚至多重文件夹的情况。
2、源文件夹中存在多重文件夹
一个简单的思路就是:在遍历源文件夹内的文件时,先判定当前文件这是文件还是文件夹。如果当前文件是文件夹的话,开始遍历此文件夹内的文件,如果里面还有文件夹,遍历这个文件夹,依次类推。利用递归的方法,代码如下:
import os path_s = 'F:\\test\\s'
path_t = 'F:\\test\\t' def copy_file(paths,patht):
for filename in os.listdir(paths):
filename_s = paths+os.sep+filename
filename_t = patht+os.sep+filename
if os.path.isdir(filename_s):
if not os.path.exists(filename_t):
os.mkdir(filename_t) #在目标文件夹中创建对应的文件夹
copy_file(filename_s,filename_t) # 递归
else:
print '[*] Source :',filename_s print '[*] Target :',filename_t
with open(filename_s,'rb') as f_s:
with open(filename_t,'wb') as f_t:
f_t.write(f_s.read()) copy_file(path_s,path_t)
目前,简单的文件夹复制功能已经实现了。
3、目标文件夹中已有文件不再复制
一个简单的方法就是在目标文件夹中复制文件之前先利用函数“os.path.exists”判定这个文件是否存在。
import os path_s = 'F:\\test\\s'
path_t = 'F:\\test\\t' def copy_file(paths,patht):
for filename in os.listdir(paths):
filename_s = paths+os.sep+filename
filename_t = patht+os.sep+filename
if os.path.isdir(filename_s):
if not os.path.exists(filename_t):
os.mkdir(filename_t)
copy_file(filename_s,filename_t)
else:
if os.path.exists(filename_t):
print '[*] "%s" already exists! ' % filename_t
else:
print '[*] Source :',filename_s print '[*] Target :',filename_t
with open(filename_s,'rb') as f_s:
with open(filename_t,'wb') as f_t:
f_t.write(f_s.read()) copy_file(path_s,path_t)
这个办法避免了一部分已有文件的重复复制操作,减少了部分不必要的读写操作,但是却无法消除内容相同但名称、路径不同的重复文件。
4、利用MD5判定重复文件
目前判定两个文件是否相同,除了按字节逐个对比这个笨方法外,简单常用的办法就是利用MD5和CRC校验,或是按一定规律挑取文件的指定位置的数据块就行对比。
这次利用文件的MD5值,将目标文件夹中已有文件的MD5值保存到列表或字典中,每在源文件夹中读取一个文件就判定该文件的MD5值是否已经存在于MD5列表,没有的话再进行复制操作,并将该文件的MD5值写入列表。
import os
import hashlib path_s = 'F:\\test\\s'
path_t = 'F:\\test\\t'
list_file = {} def create_file_list(path):
for name in os.listdir(path):
filename = path+os.sep+name
if os.path.isdir(filename):
create_file_list(filename)
else:
with open(filename,'rb') as f:
md5 = hashlib.md5(f.read()).hexdigest()
if md5 not in list_file:
list_file[md5] = 1 def copy_file(paths,patht):
for filename in os.listdir(paths):
filename_s = paths+os.sep+filename
filename_t = patht+os.sep+filename
if os.path.isdir(filename_s):
if not os.path.exists(filename_t):
os.mkdir(filename_t)
copy_file(filename_s,filename_t)
else:
if os.path.exists(filename_t):
print '[*] "%s" already exists! ' % filename_t
else:
with open(filename_s,'rb') as f_s:
data = f_s.read()
file_md5 = hashlib.md5(data).hexdigest()
if file_md5 not in list_file:
list_file[file_md5] = 1
print '[*] Source :',filename_s
print '[*] Target :',filename_t
with open(filename_t,'wb') as f_t:
f_t.write(data)
else:
print '[*] "%s"\'s MD5 already exists! ' % filename_t create_file_list(path_t)
copy_file(path_s,path_t)
如下图,运行后内容相同的几个文件,只有第一次读取到的时候才写入目标文件夹,其他路径下的文件并没有复制到目标文件夹。
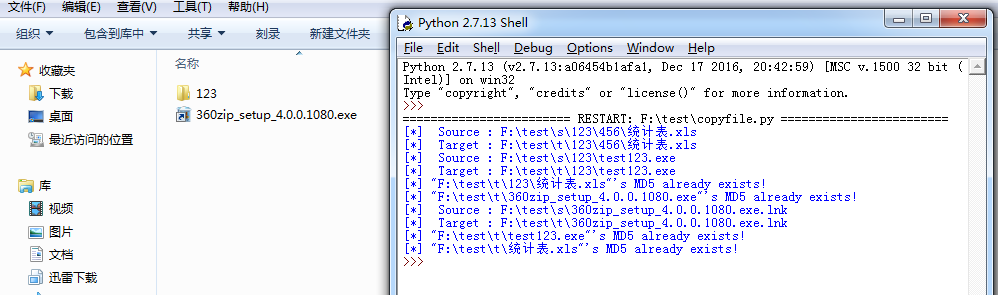
利用python实现两个文件夹的同步的更多相关文章
- 基于Python——实现两个文件夹中的文件拷贝
[背景]当复制一个文件夹中的某文件到另一个文件夹中时是一件很容易的事情,可是如果存在很多文件夹中的文件需要一一拷贝,就会变的很繁琐,稍有不慎就会遗漏,今天就用Python来解决这个问题—— [代码实现 ...
- 利用python合并两个文件
1格式如下 在做利用zabbix的api来批量添加主机的时候,需要处理ip和hostname,在借用别人写的py程序的基础上,自己有改装了以下脚本,为自己使用.需要时ip和hostname为一个统一格 ...
- 利用Python批量重命名文件夹下文件
#!/usr/bin/python # -*- coding: UTF-8 -*- # -*- coding:utf8 -*- import os from string import digits ...
- 使用python实现两个文件夹里文件的对比(包含内容的对比)
#-*-coding:utf-8-*- #=============================================================================== ...
- Python批量复制迁移文件夹
前言 Python可以利用shutil库进行对文件夹,文件的迁移.而在本次的实践当中,难点在于目标文件夹的名称和数据源文件夹的名称,需要利用 工作单位提供的中间数据去进行对比连接起来. 例如:目标源的 ...
- Path,Files巩固,题目:从键盘接收两个文件夹路径,把其中一个文件夹中(包含内容)拷贝到另一个文件夹中
这个题目用传统的File,InputStream可以做,但是如果用Files,Path类做,虽然思路上会困难一些,但是代码简洁了很多,以下是代码: import java.io.IOException ...
- 利用 Python 进行批量更改文件后缀
利用 Python 进行批量更改文件后缀 代码 import os files = os.listdir('.') for file_name in files: portion = os.path. ...
- Linux下对比两个文件夹的方法
最近拿到一份源代码,要命的是这份源代码是浅克隆模式的git包,所以无法完整显示里面的修改的内容. 今天花了一点点时间,找了一个在Linux对比两个文件夹的方法. 其实方法很简单,用meld 去对比两个 ...
- Python模糊查询本地文件夹去除文件后缀(7行代码)
Python模糊查询本地文件夹去除文件后缀 import os,re def fuzzy_search(path): word= input('请输入要查询的内容:') for filename in ...
随机推荐
- js jquery 正则去空字符
1.正则去空字符串: var str1=" a b c "; var strtrim=str1.replace(/\s/g,""); 2.js去前后空字符串: ...
- Centos7搭建docker仓库
一:安装启动registry 1.1:环境准备 yum install -y python-devel libevent-devel python-pip gcc xz-devel pip insta ...
- js 发送http请求
// 1.创建 XHR对象(IE6- 为ActiveX对象) // 2.连接及发送请求 // 3.回调处理 function createXMLHttpRequest() { var xhr; ...
- 【转】git - 简易指南
原文链接:http://www.bootcss.com/p/git-guide/ 作者:罗杰·杜德勒 感谢:@tfnico, @fhd and Namics 其他语言 english, deutsch ...
- H5手指滑动切换卡片效果
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- Annotation(注解)介绍
Annotation(注解)是什么: Annotation(注解) 官方的定义: An annotation is a form of metadata, that can be added t ...
- ionic3 对android包进行签名
在已经生成签名文件的前提下 对android包进行签名 如果还未生成签名文件 请参考链接 https://jingyan.baidu.com/article/642c9d34eaeeda644a46f ...
- Docker多主机互联最佳实践
在公司使用docker多主机互联时碰到了各种坑.搞清楚后才发现如此简单,以下是根据实际经验的总结. 版本信息 Client: Version: 18.09.0 API version: 1.39 Go ...
- html之跳转锚
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- nw 引用 sqlite
0.好吧,这对于我这个c 小白来说,真的有点难度. 1.安装Python 2.7.14 https://www.python.org/downloads/ 2.安装最新的nodejs+npm http ...