AI-2.梯度下降算法
上节定义了神经网络中几个重要的常见的函数,最后提到的损失函数的目的就是求得一组合适的w、b
先看下损失函数的曲线图,如下
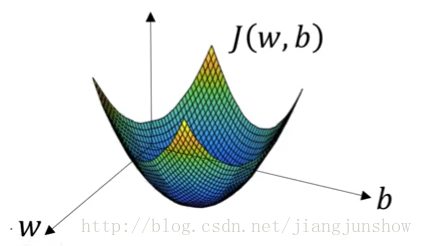

即目的就是求得最低点对应的一组w、b,而本节要讲的梯度下降算法就是会一步一步地更新w和b
通过公式w’ = w – r * dw 改变w的值
梯度下降算法就是重复的执行上面的公式来不停的更新w的值,新的w的值(w’)等于旧的w减去学习率r与偏导数dw的乘积。r表示学习步进/学习率(learning rate),假设w是10,又假设dw为1,r为4时,那么在第一次梯度下降后,w’的值将变成6,而当r为2时,那么第一次下降后,w’将是8,从10变成了8比起从10变成6,变化得没有那么大,因为变化率r比较小。r是我们用来控制w的变化步进的参数。dw是参数w关于损失函数J的偏导数,偏导数说白了就是斜率。斜率就是变化比例,即当w改变一点点后J会相应的改变多少。看上图中的黄色的小三角,在w的初始值(假设为6)的位置的偏导数/斜率/变化比例就是小三角的高除以低边(J的变化除以w的变化),也就是在当w为6时J函数的变化与w的变化之比,曲线越陡,那么三角形越陡,那么斜率越大,那么当w的值改变一丁点后(例如减1)那么J相应的改变就会越大(假设会减小3),在下面那个小三角的位置(假设那里的w是4),这个位置的曲线不是那么的陡,即斜率比较小,那么在那里w的值改变一点后(例如也减小1)但J相应的改变却没有那么大了(可能只减小1.5)。这个斜率dw就是J的变化与w的变化的比例,就是说,我们按照这个比例去使w越来越小那么它相应的J也会越来越小,最终达到我们的目的,找到J最小值时w的值是多少。损失函数J的值越小,表示预测越精准。神经网络就是通过这种方法来进行学习的,通过梯度下降算法来一步一步改变w和b的值,使损失函数越来越小,使预测越来越精准。
要解释下这里的r,用它来控制w改变的步进,避免错过w的最佳值,所以选对一个r很重要,至于如何选择,后续介绍啦~
部分转载:http://blog.csdn.net/jiangjunshow
AI-2.梯度下降算法的更多相关文章
- 梯度下降算法实现原理(Gradient Descent)
概述 梯度下降法(Gradient Descent)是一个算法,但不是像多元线性回归那样是一个具体做回归任务的算法,而是一个非常通用的优化算法来帮助一些机器学习算法求解出最优解的,所谓的通用就是很 ...
- 梯度下降算法的一点认识(Ng第一课)
昨天开始看Ng教授的机器学习课,发现果然是不错的课程,一口气看到第二课. 第一课 没有什么新知识,就是机器学习的概况吧. 第二课 出现了一些听不太懂的概念.其实这堂课主要就讲了一个算法,梯度下降算法. ...
- ng机器学习视频笔记(二) ——梯度下降算法解释以及求解θ
ng机器学习视频笔记(二) --梯度下降算法解释以及求解θ (转载请附上本文链接--linhxx) 一.解释梯度算法 梯度算法公式以及简化的代价函数图,如上图所示. 1)偏导数 由上图可知,在a点 ...
- 监督学习:随机梯度下降算法(sgd)和批梯度下降算法(bgd)
线性回归 首先要明白什么是回归.回归的目的是通过几个已知数据来预测另一个数值型数据的目标值. 假设特征和结果满足线性关系,即满足一个计算公式h(x),这个公式的自变量就是已知的数据x,函数值h(x)就 ...
- [机器学习Lesson3] 梯度下降算法
1. Gradient Descent(梯度下降) 梯度下降算法是很常用的算法,可以将代价函数J最小化.它不仅被用在线性回归上,也被广泛应用于机器学习领域中的众多领域. 1.1 线性回归问题应用 我们 ...
- Spark MLib:梯度下降算法实现
声明:本文参考< 大数据:Spark mlib(三) GradientDescent梯度下降算法之Spark实现> 1. 什么是梯度下降? 梯度下降法(英语:Gradient descen ...
- Logistic回归Cost函数和J(θ)的推导(二)----梯度下降算法求解最小值
前言 在上一篇随笔里,我们讲了Logistic回归cost函数的推导过程.接下来的算法求解使用如下的cost函数形式: 简单回顾一下几个变量的含义: 表1 cost函数解释 x(i) 每个样本数据点在 ...
- 梯度下降算法对比(批量下降/随机下降/mini-batch)
大规模机器学习: 线性回归的梯度下降算法:Batch gradient descent(每次更新使用全部的训练样本) 批量梯度下降算法(Batch gradient descent): 每计算一次梯度 ...
- tensorflow随机梯度下降算法使用滑动平均模型
在采用随机梯度下降算法训练神经网络时,使用滑动平均模型可以提高最终模型在测试集数据上的表现.在Tensflow中提供了tf.train.ExponentialMovingAverage来实现滑动平均模 ...
随机推荐
- LeetCode.接雨水
题外话:LeetCode上一个测试用例总是通不过(我在文章末贴出通不过的测试用例),给的原因是超出运行时间,我拿那个测试用例试了下2.037ms运行完.我自己强行给加了这句: && m ...
- [Linux]返回被阻塞的信号集
一.概述 在另一篇实例说到,进程可以屏蔽它不想接收的信号集. 事实上这些被屏蔽的信号只是阻塞在内核的进程表中,因为他们不能递送给进程,所以状态是未决的(pending). 利用sigpending函数 ...
- phpredis扩展实现LBS距离计算和范围筛选
来源 public function geo(){ $redis = new \redis(); $redis -> connect('127.0.0.1',6379); //位置增加 $res ...
- echarts-饼状图默认选中高亮
1.首页需要设置legend legend: { data: ["积极", "负面"], selectedMode: false, show: false } ...
- python中单例模式的四种实现方式
配置文件settings.py IP='100.0.0.2' PORT=3302 方式一:绑定给类的方法 class Mysql: __instance = None def __init__(sel ...
- poj 1741
点分治入门题 首先发现是树上点对的问题,那么首先想到上点分治 然后发现题目要求是求出树上点对之间距离小于等于k的对数,那么我们很自然地进行分类: 对于一棵有根树,树上的路径只有两种:一种经过根节点,另 ...
- django实现SSO
前言 公司的各种运维平台越来越多,用户再每个平台都注册账号,密码,密码太多记不住不说,然后有的平台过一段时间还得修改密码,烦!还不如弄个统一登录平台!! 需求分析 造这辆大车,首先就得造两个轮子 首先 ...
- C++—模板(2)类模板与其特化
我们以顺序表为例来说明,普通顺序表的定义如下: typedef int DataType; //typedef char DataType; class SeqList { private : Dat ...
- react安装 项目构建
1.nodejs安装 下载安装包,解压.如果是已编译文件,在/etc/profile中设置PATH(/etc/profile文件中的变量设置,所有用户可用,但需求重启服务器),并source /etc ...
- html_jQuery_ajax
ajax核心对象: XMLHttpRequest 那年创建的XMLHttpRequest对象 创建的.. ajax 几种常用方法: load(); $.get(); $.post(); $.getS ...