Kubernetes之服务发现及负载Services
Service 概述
kubernetes 中的pod是有生生灭灭的,时刻都有可能被新的pod所代替,而不可复活(pod的生命周期)。一旦一个pod生命终止,通过ReplicaSets动态创建和销毁pod(Pod的动态扩缩容,滚动升级 等)。 每个pod都有自己的IP,这IP随着pod的生生灭灭而变化,不能被依赖。这样导致一个问题,如果这个POD作为后端(backend)提供一些功能供给一些前端POD(frontend),在kubernete集群中是如何实现让这些前台能够持续的追踪到这些后台的?所以之间需要一个服务作为后端的服务负载------service
Kubernetes Service 是一个定义了一组Pod的策略的抽象,这些被服务标记的Pod都是(一般)通过label Selector实现的
举个例子,考虑一个图片处理 backend,它运行了3个副本。这些副本是可互换的 —— frontend 不需要关心它们调用了哪个 backend 副本。 然而组成这一组 backend 程序的 Pod 实际上可能会发生变化,frontend 客户端不应该也没必要知道,而且也不需要跟踪这一组 backend 的状态。 Service 定义的抽象能够解耦这种关联。
Service 实现的三种方式
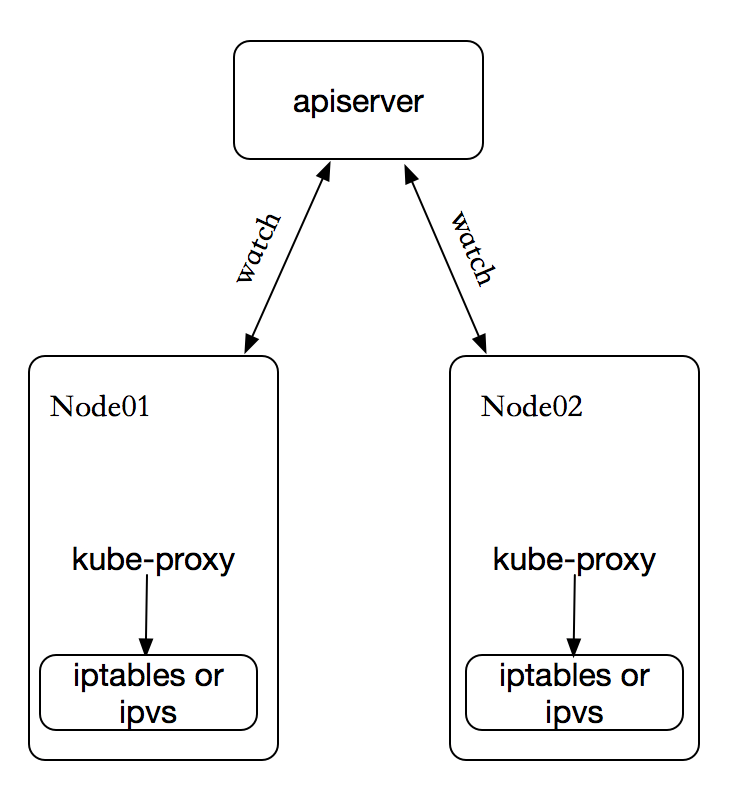
在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。kube-proxy 负责为 Service 实现了一种 VIP(虚拟 IP)的形式,而不是 ExternalName 的形式,在 Kubernetes v1.0 版本,代理完全在 userspace。在 Kubernetes v1.1 版本,新增了 iptables 代理,但并不是默认的运行模式。 从 Kubernetes v1.2 起,默认就是 iptables 代理。在Kubernetes v1.8.0-beta.0中,添加了ipvs代理。在 Kubernetes v1.0 版本,Service 是 “4层”(TCP/UDP over IP)概念。 在 Kubernetes v1.1 版本,新增了 Ingress API(beta 版),用来表示 “7层”(HTTP)服务。
kube-proxy 这个组件始终监视着apiserver中有关service的变动信息,获取任何一个与service资源相关的变动状态,通过watch监视,一旦有service资源相关的变动和创建,kube-proxy都要转换为当前节点上的能够实现资源调度规则(例如:iptables、ipvs)
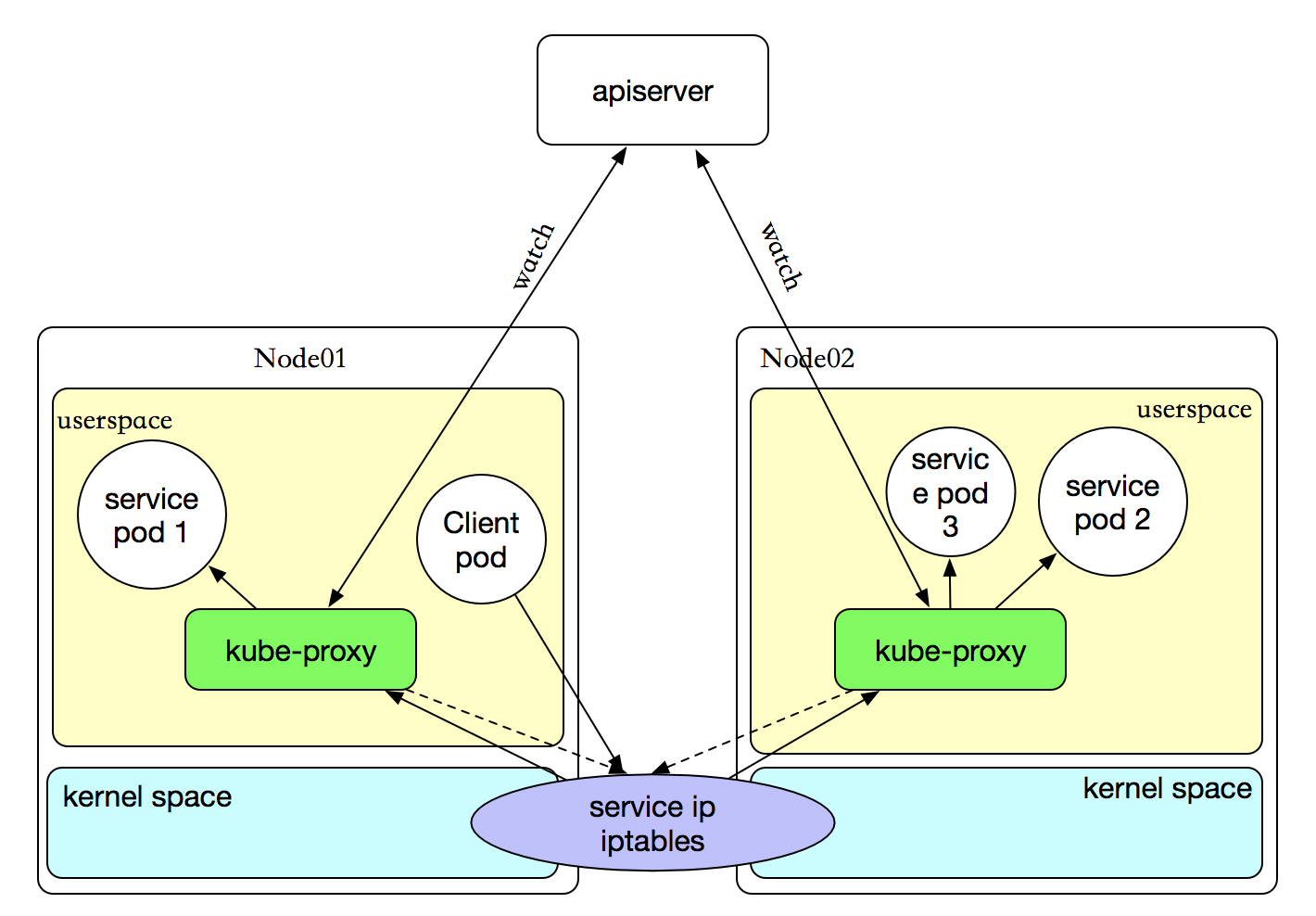
userspace 代理模式
这种模式,当客户端Pod请求内核空间的service iptables后,把请求转到给用户空间监听的kube-proxy 的端口,由kube-proxy来处理后,再由kube-proxy打请求转给内核空间的 service iptalbes,再由service iptalbes根据请求转给各节点中的的service pod。由此可见这个模式有很大的问题,由客户端请求先进入内核空间的,又进去用户空间访问kube-proxy,由kube-proxy封装完成后再进去内核空间的iptables,再根据iptables的规则分发给各节点的用户空间的pod。这样流量从用户空间进出内核带来的性能损耗是不可接受的
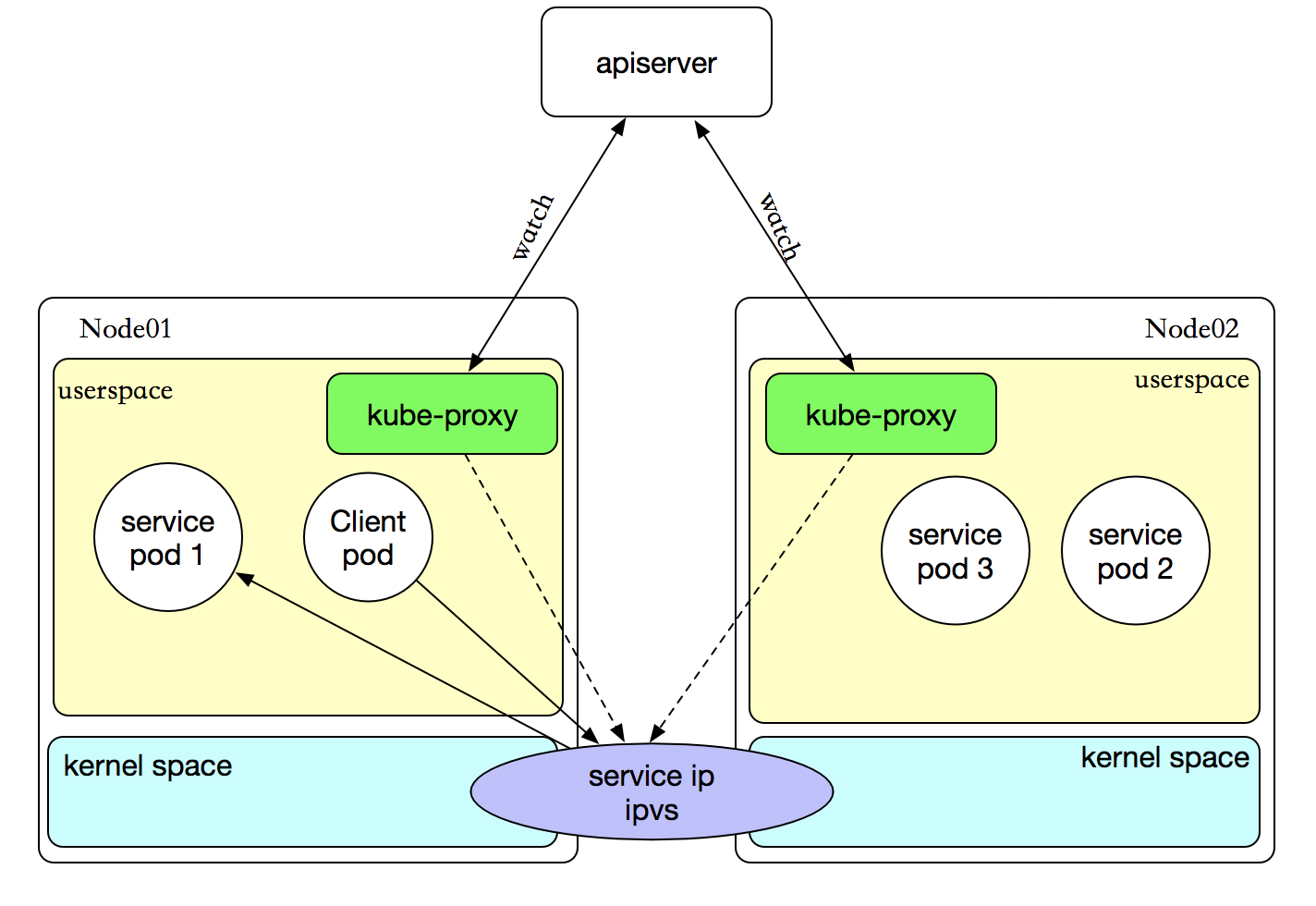
iptables 代理模式
客户端IP请求时,直接求情本地内核service ip,根据iptables的规则求情到各pod上,因为使用iptable NAT来完成转发,也存在不可忽视的性能损耗。另外,如果集群中存在上万的Service/Endpoint,那么Node上的iptables rules将会非常庞大,性能还会再打折扣。

ipvs 代理模式
客户端IP请求时,直接求情本地内核service ipvs,根据ipvs的规则求情到各pod上。kube-proxy会监视Kubernetes Service对象和Endpoints,调用netlink接口以相应地创建ipvs规则并定期与Kubernetes Service对象和Endpoints对象同步ipvs规则,以确保ipvs状态与期望一致。访问服务时,流量将被重定向到其中一个后端Pod。
与iptables类似,ipvs基于netfilter 的 hook 功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着ipvs可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs为负载均衡算法提供了更多选项,例如:
- rr:
轮询调度 - lc:最小连接数
dh:目标哈希sh:源哈希sed:最短期望延迟nq:不排队调度
注意: ipvs模式假定在运行kube-proxy之前在节点上都已经安装了IPVS内核模块。当kube-proxy以ipvs代理模式启动时,kube-proxy将验证节点上是否安装了IPVS模块,如果未安装,则kube-proxy将回退到iptables代理模式。
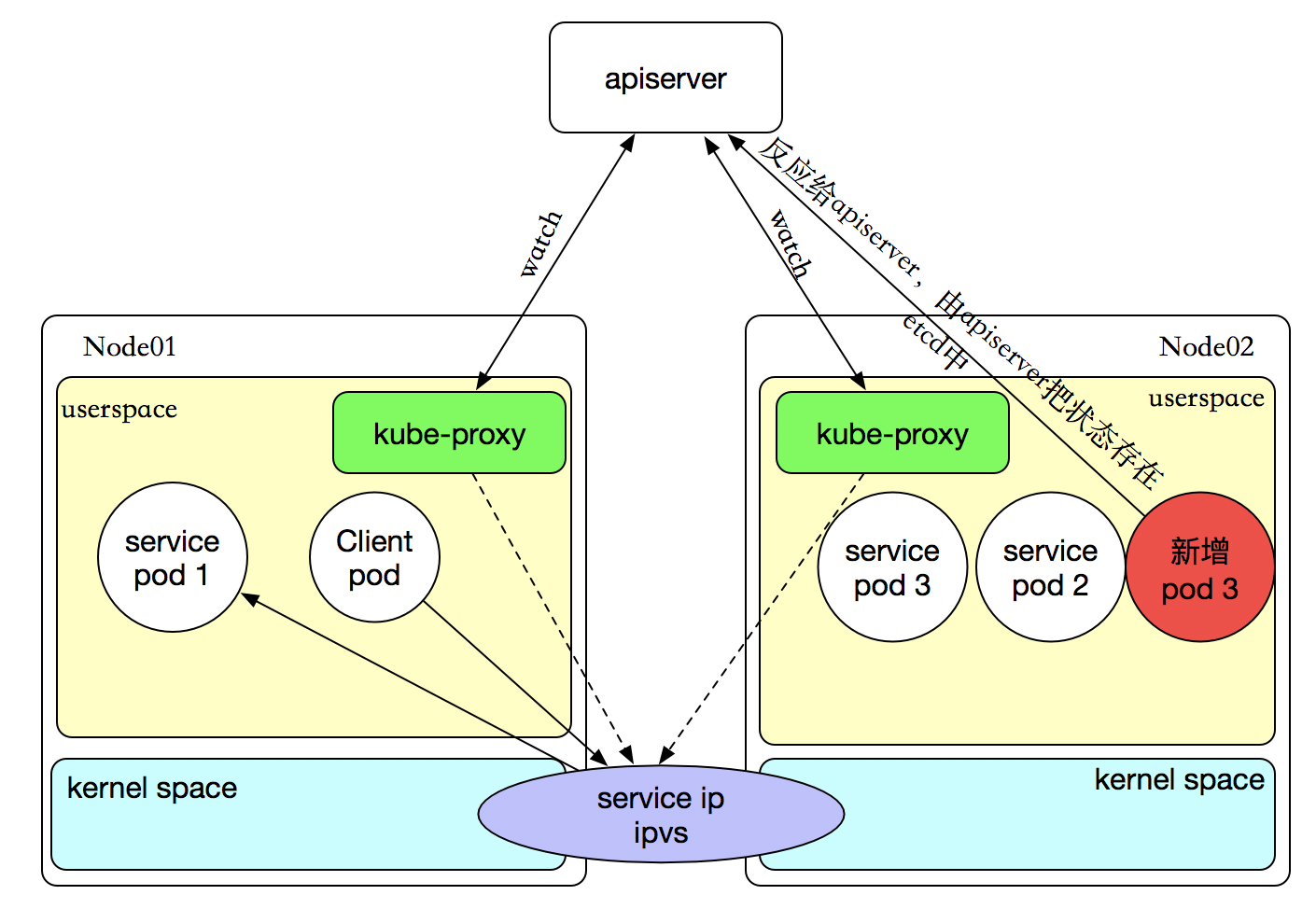
如果某个服务后端pod发生变化,标签选择器适应的pod有多一个,适应的信息会立即放映到apiserver上,而kube-proxy一定可以watch到etc中的信息变化,而将他立即转为ipvs或者iptables中的规则,这一切都是动态和实时的,删除一个pod也是同样的原理。
service 定义
kubectl explain svc.spec
- ports 建立哪些端口,暴露的端口是哪些
- selector 把哪些容器通过这个service暴露出去
- type 有四种 (ExternalName ClusterIP NodePort LoadBalancer) 默认是ClusterIP
ports 的定义
kubectl explain svc.spec.ports
- name 指定的port的名称
- nodePort 指定节点上的端口
- port 暴露给服务的端口
- targetPort 容器的端口
- protocol 执行协议(TCP or UDP)
ClusterIP方式
apiVersion: v1
kind: Service
metadata:
name: redis
namespace: default
spec:
selector:
app: redis
role: log-store
type: ClusterIP
ports:
- port:
targetPort:
查看一下详细
$ kubectl describe svc redis
Name: redis
Namespace: default
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"name":"redis","namespace":"default"},"spec":{"ports":[{"port":,"targetPort":}...
Selector: app=redis,role=log-store
Type: ClusterIP
IP: 10.43.164.114
Port: <unset> /TCP
Endpoints: 10.42.0.219:
Session Affinity: None
Events: <none>
资源记录格式:
SVC_NAME.NS_NAME.DOMAIN.LTD.
默认的service的a记录 svc.cluster.local.
刚创建的service的a记录 redis.default.cluster.local.
NodePort方式
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
selector:
app: myapp
release: dev
type: NodePort
ports:
- port:
targetPort:
nodePort:
$ kubectl describe svc myapp
Name: myapp
Namespace: default
Labels: <none>
Annotations: field.cattle.io/publicEndpoints=[{"addresses":["172.16.138.170"],"port":,"protocol":"TCP","serviceName":"default:myapp","allNodes":true}]
kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"name":"myapp","namespace":"default"},"spec":{"ports":[{"nodePort":,"port":,"ta...
Selector: app=myapp,release=dev
Type: NodePort
IP: 10.43.162.175
Port: <unset> /TCP
NodePort: <unset> /TCP
Endpoints: 10.42.0.218:,10.42.1.107:,10.42.3.210:
Session Affinity: None
Events: <none> #可以看到他负责均衡的效果
$ for a in {1..10}; do curl http://172.16.138.170:30080/hostname.html && sleep 1s; done
myapp-deploy-869b888f66-4l4cv
myapp-deploy-869b888f66-7shh9
myapp-deploy-869b888f66-4l4cv
myapp-deploy-869b888f66-7shh9
myapp-deploy-869b888f66-4l4cv
myapp-deploy-869b888f66-7shh9
myapp-deploy-869b888f66-vwgj2
myapp-deploy-869b888f66-7shh9
myapp-deploy-869b888f66-4l4cv
LoadBalancer类型
使用支持外部负载均衡器的云提供商的服务,设置 type 的值为 "LoadBalancer",将为 Service 提供负载均衡器。 负载均衡器是异步创建的,关于被提供的负载均衡器的信息将会通过 Service 的 status.loadBalancer 字段被发布出去。
来自外部负载均衡器的流量将直接打到 backend Pod 上,不过实际它们是如何工作的,这要依赖于云提供商。 在这些情况下,将根据用户设置的 loadBalancerIP 来创建负载均衡器。 某些云提供商允许设置 loadBalancerIP。如果没有设置 loadBalancerIP,将会给负载均衡器指派一个临时 IP。 如果设置了 loadBalancerIP,但云提供商并不支持这种特性,那么设置的 loadBalancerIP 值将会被忽略掉。
ExternalName 类型
提供访问发布服务的,像使用集群内部一样使用外部服务。
会话粘性(常说的会话保持)
kubectl explain svc.spec.sessionAffinity
支持ClientIP和None 两种方式,默认是None(随机调度) ClientIP是来自于同一个客户端的请求调度到同一个pod中
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
selector:
app: myapp
release: dev
sessionAffinity: ClientIP
type: NodePort
ports:
- port:
targetPort:
nodePort:
查看来自同一客户端的请求始终访问同一个Pod
$ kubectl describe svc myapp
Name: myapp
Namespace: default
Labels: <none>
Annotations: field.cattle.io/publicEndpoints=[{"addresses":["172.16.138.170"],"port":,"protocol":"TCP","serviceName":"default:myapp","allNodes":true}]
kubectl.kubernetes.io/last-applied-configuration={"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"name":"myapp","namespace":"default"},"spec":{"ports":[{"nodePort":,"port":,"ta...
Selector: app=myapp,release=dev
Type: NodePort
IP: 10.43.162.175
Port: <unset> /TCP
NodePort: <unset> /TCP
Endpoints: 10.42.0.218:,10.42.1.107:,10.42.3.210:
Session Affinity: ClientIP
Events: <none> $ for a in {..}; do curl http://172.16.138.170:30080/hostname.html && sleep 1s; done
myapp-deploy-869b888f66-4l4cv
myapp-deploy-869b888f66-4l4cv
myapp-deploy-869b888f66-4l4cv
myapp-deploy-869b888f66-4l4cv
myapp-deploy-869b888f66-4l4cv
myapp-deploy-869b888f66-4l4cv
myapp-deploy-869b888f66-4l4cv
myapp-deploy-869b888f66-4l4cv
myapp-deploy-869b888f66-4l4cv
myapp-deploy-869b888f66-4l4cv
Headless service(就是没有Cluster IP 的Service )
有时不需要或不想要负载均衡,以及单独的 Service IP。 遇到这种情况,可以通过指定 Cluster IP(spec.clusterIP)的值为 "None" 来创建 Headless Service。它会给一个集群内部的每个成员提供一个唯一的DNS域名来作为每个成员的网络标识,集群内部成员之间使用域名通信
这个选项允许开发人员自由寻找他们自己的方式,从而降低与 Kubernetes 系统的耦合性。 应用仍然可以使用一种自注册的模式和适配器,对其它需要发现机制的系统能够很容易地基于这个 API 来构建。
对这类 Service 并不会分配 Cluster IP,kube-proxy 不会处理它们,而且平台也不会为它们进行负载均衡和路由。 DNS 如何实现自动配置,依赖于 Service 是否定义了 selector。
apiVersion: v1
kind: Service
metadata:
name: myapp-headless
namespace: default
spec:
selector:
app: myapp
release: dev
clusterIP: "None"
ports:
- port:
targetPort:
验证
$ dig -t A myapp-headless.default.svc.cluster.local. @10.42.0.5 ; <<>> DiG 9.9.-RedHat-9.9.-.el7 <<>> -t A myapp-headless.default.svc.cluster.local. @10.42.0.5
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id:
;; flags: qr aa rd ra; QUERY: , ANSWER: , AUTHORITY: , ADDITIONAL: ;; QUESTION SECTION:
;myapp-headless.default.svc.cluster.local. IN A ;; ANSWER SECTION:
myapp-headless.default.svc.cluster.local. IN A 10.42.0.218
myapp-headless.default.svc.cluster.local. IN A 10.42.1.107
myapp-headless.default.svc.cluster.local. IN A 10.42.3.210 ;; Query time: msec
;; SERVER: 10.42.0.5#(10.42.0.5)
;; WHEN: Fri Aug :: EDT
;; MSG SIZE rcvd:
Kubernetes之服务发现及负载Services的更多相关文章
- 从零开始入门 | Kubernetes 中的服务发现与负载均衡
作者 | 阿里巴巴技术专家 溪恒 一.需求来源 为什么需要服务发现 在 K8s 集群里面会通过 pod 去部署应用,与传统的应用部署不同,传统应用部署在给定的机器上面去部署,我们知道怎么去调用别的机 ...
- Kubernetes 中的服务发现与负载均衡
原文:https://www.infoq.cn/article/rEzx9X598W60svbli9aK (本文转载自阿里巴巴云原生微信公众号(ID:Alicloudnative)) 一.需求来源 为 ...
- kubernetes云平台管理实战: 服务发现和负载均衡(五)
一.rc控制器常用命令 1.rc控制器信息查看 [root@k8s-master ~]# kubectl get replicationcontroller NAME DESIRED CURRENT ...
- Istio技术与实践02:源码解析之Istio on Kubernetes 统一服务发现
前言 文章Istio技术与实践01: 源码解析之Pilot多云平台服务发现机制结合Pilot的代码实现介绍了Istio的抽象服务模型和基于该模型的数据结构定义,了解到Istio上只是定义的服务发现的接 ...
- (转) Docker - Docker1.12服务发现,负载均衡和Routing Mesh
看到一篇介绍 Docker swarm以及如何编排的好文章,挪放到这里,自己学习的同时也分享出来. 原文链接: http://wwwbuild.net/dockerone/414200.html -- ...
- Consul + fabio 实现自动服务发现、负载均衡 - DockOne.io
Consul + fabio 实现自动服务发现.负载均衡 - DockOne.io http://dockone.io/article/1567
- 服务发现与负载均衡 dubbo zk原理
服务发现与负载均衡 拓展阅读 : dubbo 原理概念图 2016-03-03 杜亦舒 性能与架构 性能与架构 性能与架构 微信号 yogoup 功能介绍 网站性能提升与架构设计 内容整理自文章“实施 ...
- 【云计算】mesos+marathon 服务发现、负载均衡、监控告警方案
Mesos-dns 和 Marathon-lb 是mesosphere 官网提供的两种服务发现和负载均衡工具.官方的文档主要针对DCOS,针对其它系统的相关中文文档不多,下面是我在Centos7上的安 ...
- grpc服务发现与负载均衡
前言 在后台服务开发中,高可用性是构建中核心且重要的一环.服务发现(Service discovery)和负载均衡(Load Balance)一直都是我关注的话题.今天来谈一下我在实际中是如何理解及落 ...
随机推荐
- python3 OrderedDict类(有序字典)
创建有序字典 import collections dic = collections.OrderedDict() dic['k1'] = 'v1' dic['k2'] = 'v2' dic['k3' ...
- 根据List集合中的对象属性排序
首先创建一个Student对象,里面有三个属性,分别是int类型,String类型,Date类型 package com.sinoway.cisp.test; import java.text.Sim ...
- DB2增删改不记录日志
第一步:关闭事务自动提交 C:\DB2>db2set DB2OPTIONS=+c +c永久关闭自动提交,-c永久开启自动提交 第二步:表修改为不记录日志 db2 alter table T1 a ...
- $.extend()浅拷贝深拷贝
参考网址:http://bijian1013.iteye.com/blog/2255037 jQuery.extend() 函数用于将一个或多个对象的内容合并到目标对象. 注意:1. 如果只为$.ex ...
- 记一个bug
就在刚刚,测试叫我去看一个问题,有用户反应,在业务页面,出现了一部分重复的内容,而且点击按钮弹窗里,出现了只有个title,没有body的情况. 事情的现象就是这样.然后我就开始着手找原因了.首先声明 ...
- tmux编译安装
依赖libevent,ncurses libevent 2.x 官网:http://libevent.org 下载:https://github.com/libevent/libevent/relea ...
- 文本分类实战(八)—— Transformer模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 前端学习-基础部分-css(一)
开始今日份整理 1.CSS的导入方式 CSS的导入方式主要是有内联模式,行内模式,外部样式表 1.1 内联模式 内联模式:直接在<head>中直接写css,例如 p{ color:rgb( ...
- docker 常用命令和常用容器启动
docker:systemctl start docker # docker 启动systemctl stop docker # docker 停止systemctl restart docker # ...
- 手把手教你发布一个Python包
本文主题如下: 编写一个包(Python 源代码),但不是本文的重点. 编译包,观察编译后的文件. 发布包,发布的包可以有多种类型. 如何在 Pypi 中查看已发布的包 注意: 本文编写的包在 Pyt ...