目标检测(二) SPPNet
引言
先简单回顾一下R-CNN的问题,每张图片,通过 Selective Search 选择2000个建议框,通过变形,利用CNN提取特征,这是非常耗时的,而且,形变必然导致信息失真,最终影响模型的性能。
由此引出了一系列问题
问题1:形变耗时又损失信息,为什么要形变
很简单,因为CNN的输入必须是固定尺寸。
问题2:为什么CNN的输入必须固定尺寸
CNN主要由两部分组成,卷积层和全连接层,卷积层可以接受任意尺寸的图像,只是不同的输入卷积后的特征图尺寸不同,而全连接必须是固定的输入,所以任意尺寸生成了不同的特征图,不符合全连接的输入,由此我们发现,CNN固定输入的需求完全来自于全连接层。
SPPNet 诞生
何凯明,中国人,有兴趣可以搜一下,曾发明ResNet,SPPNet也出自他手。
既然只有全连接需要固定输入,那么能否在全连接前面加上一个网络层,使得卷积的不同输出被转化成固定尺寸呢?
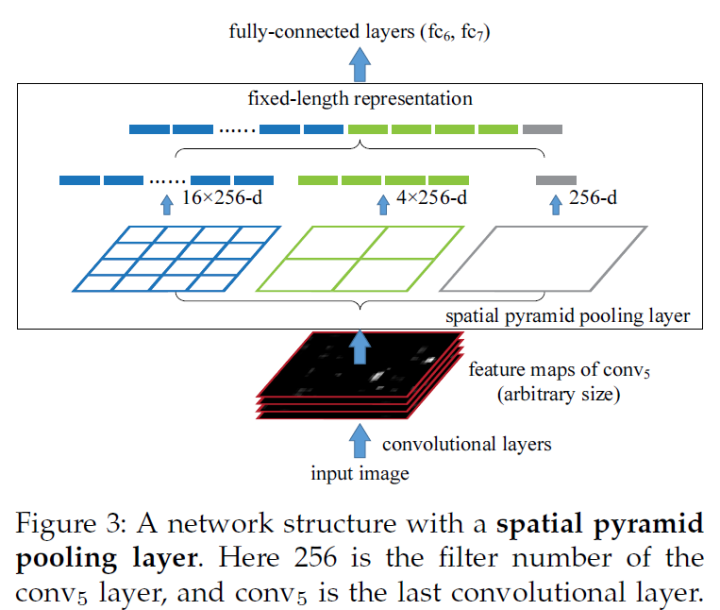
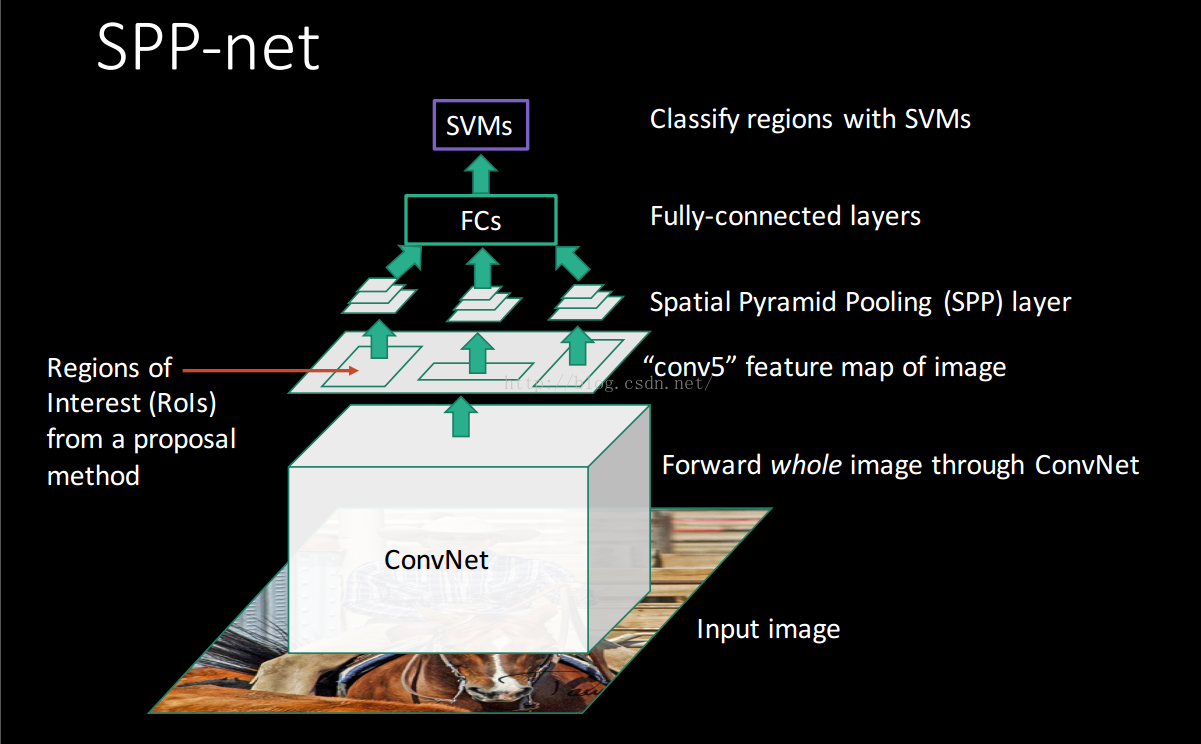
何凯明团队发明了空间金字塔池化(spatial pyramid pooling,SPP)层来解决这个问题。
SPP层放在最后一个卷积层后面,对特征图进行池化操作,并产生固定长度的输出,喂给全连接层。
网络结构如下

这个网络就叫做SPPNet。
这种方法不仅解决了形变的问题,还有一个有意思的说法,就是通过裁剪或者缩放的形变使得信息在一开始就被暴力的删减,可能损失有用信息,而SPP是在卷积之后,对信息的一种汇总,放弃无效信息,这有助于提高模型的精度,作者也通过实验证明了这个观点。
空间金字塔池化
SPP其实借鉴了传统图像处理的方法SPM,SPM主要思路是把图像分成不同尺度的一些块,比如一幅图像分成1份、4份、8份等,然后对每块提取特征后融合在一起,得到多个尺度的特征。
SPPNet首次将这种思想应用到CNN中,思路如出一辙
黑色代表特征映射图
把不同尺寸的特征映射图分为1份、4份、16份,然后在每个块上进行最大池化,池化后的特征拼接到一起,形成固定输出
最终生成1+4+16=21个特征
这里我们用符号表示,输出特征数为MK,M=#bins,总块数,K=#filters,卷积核个数,
上例中MK=21x256,注意这里只是举例,实际中M、K根据实际情况确定。
卷积层特征图
为了便于理解空间金字塔池化在做什么,作者可视化了卷积后的特征图
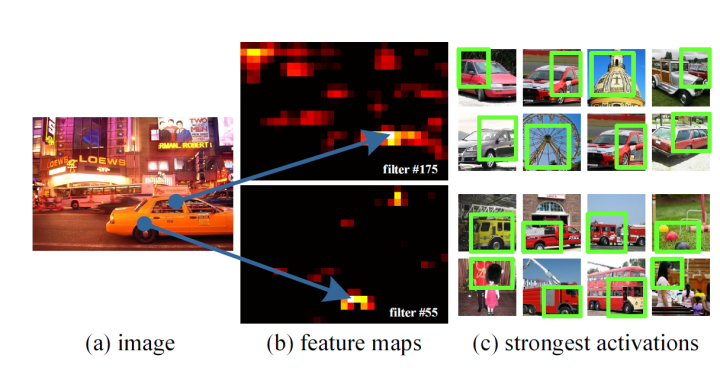
SPPNet通过可视化conv5层特征,发现卷积其实保留了空间位置信息,如车窗和车轮卷积后还在对应位置,而且每一个卷积核负责提取不同的特征,如filter#175负责提取车窗特征,(长得像车窗,并不一定是车窗)
filter#55负责提取车轮的特征,(长得像车轮,并不一定是车轮),最终融合的就是这些特征。
SPP误区
这里记录一下我在学习SPPNet时犯的一个错误。
根据上面讲的SPP方法,我们可能认为是这样做的

假如分成4块,pool2x2,那么是对每个小方块池化
其实不然
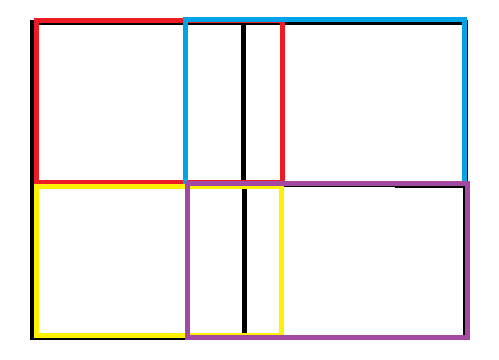
也可以是这样池化,每种颜色为一次池化,最终也是4块,pool2x2
由此我们发现分成几块 pool n*n,跟我们的池化野没有关系,池化野可以是任意的合理尺寸,只要最终能生成 n*n 块就行了。
SPPNet 的训练
好了,现在我们可以输入任意尺寸图片,然后卷积,空间金字塔池化,固定输出,全连接,貌似整个网络没问题了,但事与愿违。
什么问题呢?
因为深度学习框架是需要固定输入的:我的理解,每次喂给网络batch个样本,如果样本尺寸不一样,那怎么卷积呢?ok,如果你说一张一张卷积,也可以,但是这样卷积后的尺寸不同,要分开存储,而且,GPU是并行计算的,属于矩阵间的计算,尺寸不同,根本无法存储在一个矩阵里,何谈并行,所以肯定要固定输入。
那SPPNet 怎么训练呢?
作者将网络的训练分为两种:Single-size 和 Multi-size
Single-size
单一尺寸训练,仍然把输入限制在固定尺寸,只是在卷积之后加上空间金字塔池化层,这个尝试的目的是开启多级别池化行为。
难点在于如何根据特征映射图和金字塔层级来确定池化野和步长
假设卷积后的特征映射图尺寸为 axa(如13x13),对于 n*n 的金字塔级,要实现一个滑框池化过程,池化野大小为 win=上取整[a/n],步长为 stride=下取整[a/n]
作者展示了3层金字塔池化的例子

这里可以回看我讲的SPP误区,帮助理解,其实是这样的,以pool3x3为例

可以看到池化完刚好 3x3
不禁有人要问了,feature map 不是正方形怎么办?这里作者没讲到,自由发挥吧,比如拿0填充成正方形,以后我查到这方面的资料,再补充。
Multi-size
多尺寸训练,输入为不同尺寸,并且包含空间金字塔池化,目的是模拟多尺度输入的训练。
作者预先设定了2个尺寸,224*224 和 180*180,224通过裁剪得到,180通过缩放得到,
对于输入为180的网络,卷积层一样,空间金字塔池化层设计池化野和步长,接上全连接,
对于输入为224的网络,卷积层一样,空间金字塔池化层设计池化野和步长,接上全连接,
这样两个网络的参数就一样了,池化不需要参数
在训练时,我们一个epoch输入224(或者180)的图片,训练参数,保存参数
下一个回合先读取参数,再输入180(或者224)的图片,进行训练,保存参数
依次交替进行。
这样的本质是通过共享参数的多个固定输入的网络实现了不同尺寸输入的SPPNet。
到此为止,整个网络可以正常训练了。
SPPNet 用于图像识别
暂时飘过...
SPPNet 用于目标检测
之前在R-CNN中讲到,R-CNN对2000个建议框进行特征提取,每次是个卷积过程,非常耗时,而且这2000个建议框很可能存在重复区域,所以存在重复计算,这是R-CNN一个很大的瓶颈。
SPPNet 除了多尺寸输入外,也解决了上个问题。
SPPNet 只需要对整张图做一次卷积,然后直接从特征图中抽取建议框的特征。
只做一次卷积,效果大大提高,所以SPPNet对目标检测是个非常大的突破。
Mapping a Window to Feature Maps
之前在卷积层特征图中讲到,卷积仍然保留了空间位置关系,也就是说原图上的位置与特征映射图的位置是对应的,之间存在了某种关系,所以可以根据原图的位置找到对应的特征映射图的位置,从而得到特征。
具体映射关系是什么呢?这部分要根据实际情况来算,没什么难的,细心就好,大致方法如下
先定义几个参数
| 类型 | 大小 |
|---|---|
| 第 |
|
| 第 |
|
| 第 |
|
| 第 |
|
| 第 |
输入尺寸与输出尺寸的关系
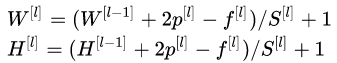
这是整个区域之间的映射。
坐标之间的映射又如何呢?
| 含义 | 符号 |
|---|---|
| 在i层的坐标值 | |
| i层的步长 | |
| i层的卷积核大小 | |
| i层填充的大小 | padding |

SPPNet对上面的映射关系做了一定的简化,过程如下:
令padding=ki/2
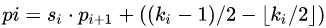
当 k_i 为奇数 所以
当k_i 为偶数所以
而是坐标值,不可能取小数 所以基本上可以认为
。公式得到了化简:感受野中心点的坐标
只跟前一层
有关。
从原图坐标到特征图中坐标
的映射关系为
- 前面每层都填充padding/2 得到的简化公式 :
- 需要把上面公式进行级联得到
其中
- 对于feature map 上的
它在原始图的对应点为
- 论文中的最后做法:把原始图片中的ROI映射为 feature map中的映射区域(上图橙色区域)其中 左上角取:
右下角的点取:界取
的
值:
。

记住做后的结论就好了,过程不重要。
检测算法
对于检测算法,论文中是这样做到:使用ss生成~2k个候选框,缩放图像min(w,h)=s之后提取特征,每个候选框使用一个4层的空间金字塔池化特征,网络使用的是ZF-5的SPPNet形式。之后将12800d的特征输入全连接层,SVM的输入为全连接层的输出。
这个算法可以应用到多尺度的特征提取:先将图片resize到五个尺度:480,576,688,864,1200,加自己6个。然后在map window to feature map一步中,选择ROI框尺度在{6个尺度}中大小最接近224x224的那个尺度下的feature maps中提取对应的roi feature。这样做可以提高系统的准确率。
SPPNet VS R-CN
总结
参考资料:
http://www.dengfanxin.cn/?p=403 SPPNet 论文翻译-空间金字塔池化
https://zhuanlan.zhihu.com/p/27485018
https://blog.csdn.net/v1_vivian/article/details/73275259
https://github.com/peace195/sppnet
目标检测(二) SPPNet的更多相关文章
- 目标检测 <二> TensorFlow安装
一:创建TensorFlow工作环境目录 1. 在anconda安装目录下找到envs目录然后进入 2. 在当前目录下创建一个文件夹改名为tensorflow 二: 创建TensorFlow工作环境 ...
- 第三十节,目标检测算法之Fast R-CNN算法详解
Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2 ...
- 目标检测算法(2)SPP-net
本文是使用深度学习进行目标检测系列的第二篇,主要介绍SPP-net:Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual R ...
- 目标检测(二)SSPnet--Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognotion
作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun 以前的CNNs都要求输入图像尺寸固定,这种硬性要求也许会降低识别任意尺寸图像的准确度. ...
- 目标检测算法之R-CNN和SPPNet原理
一.R-CNN的原理 R-CNN的全称是Region-CNN,它可以说是第一个将深度学习应用到目标检测上的算法.后面将要学习的Fast R-CNN.Faster R-CNN全部都是建立在R-CNN基础 ...
- 论文翻译—SPP-Net(目标检测)
SPPNet论文翻译 <Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition> Kai ...
- 目标检测从入门到精通—SPP-Net详细解析(三)
SPP-Net网络结构分析 Author:Mr. Sun Date:2019.03.18 Loacation: DaLian university of technology 论文名称:<Spa ...
- 【目标检测】:SPP-Net深入理解(从R-CNN到SPP-Net)
一. 导论 SPP-Net是何凯明在基于R-CNN的基础上提出来的目标检测模型,使用SPP-Net可以大幅度提升目标检测的速度,检测同样一张图片当中的所有目标,SPP-Net所花费的时间仅仅是RCNN ...
- (三)目标检测算法之SPPNet
今天准备再更新一篇博客,加油呀~~~ 系列博客链接: (一)目标检测概述 https://www.cnblogs.com/kongweisi/p/10894415.html (二)目标检测算法之R-C ...
随机推荐
- Struts 2 概念介绍
概念引入 Web层通常使用Servlet+jsp,现在使用Struts2来处理访问服务器请求 Service层 目前使用JavaBean Dao层目前使用Hibernate Spring是一个大的管家 ...
- MVC基本登陆与验证码功能实现
一.基本登陆实现与验证码功能实现,该功能是和spring.net功能集合使用的,因为后面要用到验证是否处于登陆状态 1. 先构建一个登陆页面 @{ Layout = null; } <!DOCT ...
- vw、vh、vmin、vmax、em、rem的使用详解
转载自:https://blog.csdn.net/ZNYSYS520/article/details/76053961 1,vw.vh.vmin.vmax 的含义 (1)vw.vh.vmin.vma ...
- 关于spark写入文件至文件系统并制定文件名之自定义outputFormat
引言: spark项目中通常我们需要将我们处理之后数据保存到文件中,比如将处理之后的RDD保存到hdfs上指定的目录中,亦或是保存在本地 spark保存文件: 1.rdd.saveAsTextFile ...
- Java程序设计的第二次作业
本次作业包含两个部分:一是以下4个题目的程序源码和运行结果截图:二是本次作业的小结(谈谈你在做作业的过程中遇到了哪些问题,如何解决,有哪些收获). 1.编写“人”类及其测试类.1.1 “人”类: 类 ...
- 关于CC的完全非线性椭圆方程一书的一些小结
CC的整本书主要是想要研究在粘性解的框架下的一致椭圆方程解的正则性.我们试着一章一章来解析他. 序言部分也是值得每一个字细读的,主要讲述了他们的工作的主要内容,即在粘性解的框架下研究解的正则性,需要特 ...
- 使用cookie保存用户名和密码
效果图如下 从数据库中随意使用一个账号登录 登陆成功来到人中心 返回登录界面 实现代码如下 package com.test.controller; import java.io.IOExceptio ...
- JS数组遍历
1. forEach() 循环数组,不会改变元素,不会返回新数组 arr.foreach((value,index)=>{}) 2. map() 遍历数组,对每个元素进行处理,之后返回元素:会返 ...
- Envoy 源码分析--buffer
目录 Envoy 源码分析--buffer BufferFragment RawSlice Slice OwnedSlice SliceDeque UnownedSlice OwnedImpl Wat ...
- 利用python解析地址经纬度和利用经纬度定位地址
解析地址经纬度 from geopy.geocoders import Nominatim try: geolocator = Nominatim() location = geolocator.ge ...