HBase轻松入门之HBase架构图解析
2018-12-13
2018-12-20
本篇文章旨在针对初学者以我本人现阶段所掌握的知识就HBase的架构图中各模块作一个概念科普。不对文章内容的“绝对、完全正确性”负责。
1、开胃小菜
关于HBase的架构图,直接抓取网络上图片来分析就好了。它大概长成下面的样子:

图1 HBase架构图
从上图中可以很直观地看到整个HBase都是基于HDFS之上的。这个HDFS呢,它的全称是Hadoop distributed file system,Hadoop分布式文件系统。关于在《HBase入门指南》中提到的HBase的概念:HBase是一个用于处理大数据的分布式数据库软件。它的分布式特性在这张架构图中已经很直观地体现出来了,并且它的分布式能力是由Hadoop来提供并保证的。(其实哦,HBase的分布式能力并不一定非得基于HDFS的,理论上你任意一个分布式软件都能用来给HBase“基于”用,只不过由于HDFS太流行了,加上大多数的人其实都挺忙的,不喜欢瞎折腾,就拿HDFS来凑合过呗还能换咋的。。。)
上面图1其实挺零乱挺复杂的,对于这么复杂的一张图,小白同学表示他刚一进来,什么都不知道,就看到常威在打来福。。。哦哦,不是,小白同学说本来我学HBase的干劲挺足的,但刚开始就看到这张图,着实很打击小白同学的自信心啊。既然如此,那我们就来稍微给它简化一下。图1中的各种元素其实都是有它们各自的派系的,稍微划分一下派系后后它大概长成下图2的样子:

图2 HBase架构派系划分
上图2给这个架构图加了几个框框,把它们分成了四个派系A, B, C, D。这个框框虽然很不明显,但是眼睛睁大点还是能看清的,就当锻炼锻炼视力了。
A派系呢就像是王自如的Zealer手机测评团队一样,是独立客观以及第三方的。它就是上帝,A呢就是B, C, D存在的意义。
B派系是Zookeeper,它是用来保证HBase集群的一致性的。
C派系就是HBase集群了。有些同学可能发现了,C派系HBase中好像霸占了架构图中Zookeeper的一部分啊,这是画错了吗?非也,其实之所以这样划分,是因为现在的HBase软件体系中已经集成了有Zookeeper模块了,在默认的情况下,你不需要下载一个额外的Zookeeper软件,也能够正常运行HBase系统,并且拥有一个Zookeeper相关的进程。因此C派系中也占有了一丢丢Zookeeper的内容。但是其实是生产环境中,很少会用HBase自带的Zookeeper的。
D派系呢,就是任劳任怨的HDFS了。
上面简单的了解了一下HBase架构图中的各大派系,相信到这里,各位小白同学能够稍微对这张HBase的架构图不那么陌生了。什么?上面的图还是太恶心?好吧,那我们再进一步的处理一下这张图片,这次我直接放大招,把HBase架构图抽象一下,排除一切外在干扰,就不信你还看不懂它们之间的关系。看下图:

图3 HBase架构图抽象版
2、架构图详解
继续继续,下面要详细讲讲图1 HBase架构中各模块的含义了,这部分的内容就相当让人脑阔疼咯。我们以上帝视角,从客户端Client自上往下讲起。
2.1、Client
首先还是要来了解一下概念。Client到底是什么东东?
从广义的角度来说, Client其实就是你自己,Client是人!上面我们才刚刚讲过,B, C, D,也就是Hadoop, HBase以及Zookeeper存在的意义就是要服务于A,也就是Client,也就是人。假如都没有人去操作这个HBase系统了,那你HBase系统的功能再强大又有什么意义呢?有的同学可能要抬杠了,说人家企业里的HBase系统,都是无人植守,按照程序自动去运行,一样跑的很嗨啊,哪像你说的那样,没有人去操作HBase系统就没有意义了。好的,这位同学请坐下。这些跑的很嗨的程序还不是由人去写的。。程序其实就是人类的意志的产物而已,程序怎么跑还不是由人说了算。所以,归根结底。无论是你坐在电脑前对着hbase shell敲命令行,还是自己写代码去操纵HBase,亦或是在地球的另一端通过各种软件来向HBase下达指令,你就是Client。
那从狭义的角度来说,我们下到代码层面来说,Client是HBase开放出来给程序员们使用的各种API接口。Client也像是一个承上启下的角色,对上要接收来自人的意志,对下要将人的意志转化成一条条HBase程序并逐一执行。
那说了这么多,Client在HBase系统中有什么用呢?其实它只有一个作用。
- 它是整个HBase系统的入口。
在代码层面来讲,它就是各种API接口。有了这些接口,我们就可以实现对数据的CURD,甚至是发送一些管理级的命令。
2.2、Zookeeper
Zookeeper也是Apache软件基金会中的一个顶级项目。它是给分布式系统提供协同服务的软件。协同服务是什么鬼?也许会有不少人对这个词很陌生。下面我们就来解释一下什么是协同服务。
Zookeeper从字面上翻译过来就是:动物园管理员。那为什么会起这么个名字呢?原来啊Apache软件基金会下面关于分布式的软件有很多,它们基本都会联系上一种动物,或名字或LOGO。如Hadoop(小象象),Pig(油腻猪),Hive(怪蜜蜂),HBase(酷海豚)等等等等。那么,在分布式应用当中,同步无疑是其最重要的特性,常有的同步包括:
1、配置同步;
2、时间同步;
3、相互感知(集群中各主机的上线下线消息及各种状态)。
上面提到的这几个“同步”就是“协同”的白话语言。
而为了 blah,blah,blah... 就需要一个Zookeeper来专门负责这种“同步服务”。
除了“同步服务”以外,Zookeeper还保存着HBase系统中的配置信息。什么配置信息呢?
1、master与slaver机器的信息
地址啊端口啊这些。
HMaster可以通过查询Zookeeper来了解当前哪些slaver还在正常工作当中。
假如当前master宕机了,Zookeeper还可以通过保存着的backup master的信息来重新推选出一个新的master,起到保证HBase系统高可用性的作用。
2、保存 hbase:meta 表所在的位置
hbase:meta 表在HBase中是非常重要的一张表,它是由HBase系统创建并维护的。这里暂且记住它非常重要就好了。
3、保存HBase系统中所有的表信息
假如客户端发起一个CRUD请求,首先要知道这张表存不存在吧,又保存在哪吧。通过Zookeeper就可以实现非常快速的响应,因为整个Zookeeper都是驻留在内存中的。
4、其它信息
还有各种杂七杂八但很重要的信息,都由Zookeeper来保存。
因此,Zookeeper在HBase系统中就是用于给运行在不同机器上的HBase程序提供协同服务的。
2.3、HBase
HBase模块个人理解它就像是一个装饰器。把原本HDFS(Hadoop distributed file system)的功能用“数据库的语言”来复述一遍。它在集群中共有两个进程:1. HMaster; 2. HRegionServer。整个架构图中HBase部分这么繁杂,概括出来其实也就两个东东而已。。。
2.3.1、HMaster
首先在这里先简单了解一下“HBase集群”的概念。HBase集群中有若干台计算机,其中有一台是“主机(Master)”,其余的都是“从机(Slaver)”。一般在生产系统中,还会有一台“备用主机(backup master)”。
这个HMaster进程,就是运行在“主机”上的。准确的说,应该是HMaster在哪一台计算机上运行,哪一台计算机就是“主机”。
HMaster既然作为一个“上位者”,那它肯定是轻易不会去干活的,不然领导的尊严何在?类比一下企业当中的master,他们的日常工作就对外搞搞外交,对内签签名,再视察一下各部门的工作情况,还会根据企业现阶段的发展状况作一下资源调度等等。那我们的HBase当中也基本一样,唯一的不同就是HMaster不用去外面搞外交,它只处理自己HBase系统内部的事务。
HMaster的作用主要有以下几个:
1、分发Region
首先,Region是什么?在HBase中,如果一张表所包含的内容超过设定的上限,即一张表很大的话,会将这张表水平地分成两半。比如,某张表共有1000行20列数据,HBase嫌这张表太大了,影响我检索效率。将它分成两部分,第一部分内容为第1 ~ 499行。第二部分内容为第500 ~ 1000行。那这切分出来的部分,就被称为Region。在这里,就是有两个Region。
其次,HBase系统会将这些Region尽量均衡地分发给这些“从机(Slaver)”。让集群中每台从机都干同样多同样重的活。这可以说是HMaster的首要任务。
2、监控HRegionServer
* 负责HRegionServer的故障转移
HRegionServer会定期地向HMaster发送心跳报告。当HMaster收不到HRegionServer的消息时,就认为该HRegionServer已经失去作用了。这个时候HMaster就得下达指令,将原本在HRegionServer上的数据迁移到其它正常工作的机器上去。到这里你肯定会有个疑问:根据前面讲到的判断HRegionServer故障的方式来看,这个时候HMaster已经不能够和该HRegionServer通信了,那你是怎么下达指令,让原本在这台HRegionServer上的数据进行迁移的呢?这个问题,这里暂且不讲,我们只要知道,它能够做到就是了。刚开始接触,不要一下子灌输太多概念,很容易乱的。HDFS的好处在这就体现出来了。
* 负责HRegionServer的负载均衡
当HBase系统中某台机器上的某个Region的大小超过上限时,它会被RegionServer切割成两半,切割后多出来的一个Region又会由HMaster根据集群的情况来做负载均衡,其目的就是尽可能地让每台从机干同样多同样重的活。这里还有一个:RegionServer中由“小合并”“大合并”生成的Region也会需要HMaster来做负载均衡。
那这里又有一个新的疑问:HMaster是如何得知HRegionServer是忙还是闲的呢? HRegionServer会定期向HMaster发送一份自己的运行报告,类似于企业当中各部门领导定期向老板递交工作报告一样。然后HMaster就汇总这些运行报告并分析从而作出决策并最终下达指令。
3、管理元数据
在HBase中有一个由系统创建的表: hbase:meta 。这里我们姑且称它为“元数据表”。那这个“元数据表”是干什么用的呢?
原来啊,在HBase中,所有的数据都是以“表”的形式来管理的。而当你的表增长到一定程度的时候,它会影响到你CRUD的效率。举个粟子,假设你的某张表A里有1亿条数据,现在你要查询其中一条数据。又假设你又有一张表B里面有1000条数据,同样你要查询其中一条数据,你说A和B哪个检索速度快?因此,当你的表增长到一定程度时,HMaster就会把这个表切割成几块,假设有一张表共有1000行,HMaster把它分割成两块T1和T2,T1的数据范围从第0行到第499行。T2的数据范围从第500行到第999行。不同的块根据负载均衡存储在不同的HRegionServer中。然后你要查询某一条数据的话,就首先确定你这条数据是坐落在哪一个“块”当中的,确定好后直接去这个“块”当中查询,这样检索速度就快很多了。那么,这些不同的“块”被分别存储到哪个HRegionServer中呢?这些不同的“块”又是包含了哪些范围的数据呢?这些信息就是记载在这个 hbase:meta 也就是“元数据”表中的了。一句大白话总结:元数据表是负责记载你想要查询的数据是在哪台HRegionServer上保存着的信息的。
那话说回来,HMaster对于“元数据表”的管理方式,就是负责更新这个表中的数据内容的咯,换句话说就是如果HMaster挂掉了,那这个hbase:meta的数据就停止更新了。
2.3.2、HRegionServer
HRegionServer就复杂咯。。。
我们还是再来看看HRegionServer的架构图吧。
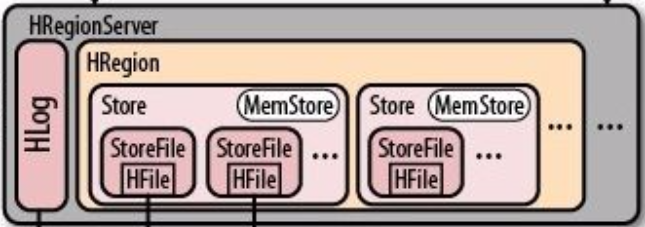
图4 HRegionServer架构图
首先呢要明确一个概念:一个HRegionServer就代表着一台计算机。我们这里所讲的一切都是基于这个大前提来讲的。事实上确实也是,一台计算机上就运行一个HRegionServer进程,我不确定会不会有运行两个HRegionServer进程的计算机,但是我觉得既然你要玩分布式,一台机器上跑两个HRegionServer就没有分布式的意义了。
接着我们来看一下HRegionServer中都有哪些东西。A picture is worth than a thousand words.
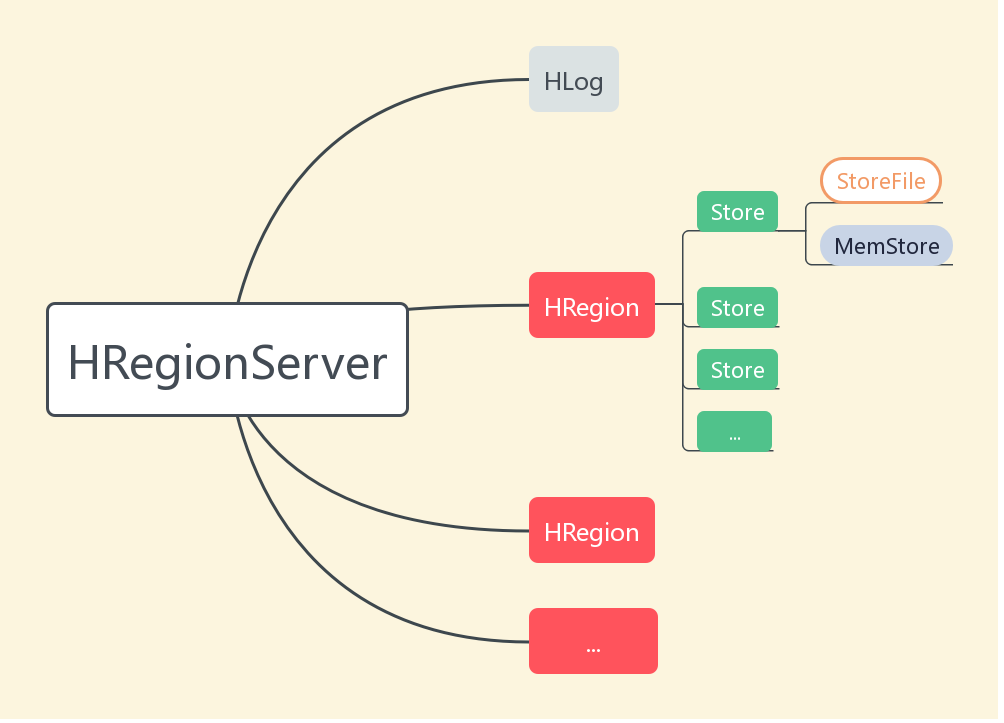
图5 HRegionServer组成
下面来了解了解HRegionServer的各个组成部分的基本概念。。。
1、 HLog
首先,一个HRegionServer中就只有一个HLog。
HLog它是采用一种叫做预写日志(write-ahead logging,简称WAL)的方式来记录数据的日志文件。数据在这个日志文件里起到一个备份的作用,它是用来作容灾的。HLog也是存储在HDFS上的。
当Client想要写数据到HBase数据库中时,数据首先会写到这个HLog中。当数据在HLog中成功保存以后就会告诉客户端:我已经成功保存好你要我保存的数据了。随后进行下一步的保存操作。需要注意的是,数据成功保存进HLog中以后,仅仅完成了HBase数据存储的三分之一而已。但在这里,不讲这么多。
2、HRegion
一个HRegionServer中有0 ~ n个HRegion。HRegion同HRegionServer一样,在计算机中都只是一段程序而已。一个HRegion代表着一个从“表”中分割出来的“块”,即HRegion代表着Region。很费解吧!HRegion是一段程序,Region是一小段逻辑表数据。每一个HRegion内部又维护着0 ~ n个Store,结合上图5来看,这部分非常的绕。一个Store呢就代表着一个列族。什么是列族?在这里先简单地把它理解成是“好几个列的集合”。同时,每一个Store内部又维护着一个MemStore和0 ~ n个StoreFile。这个MemStore是一段内存空间。而这个StoreFile就是HFile,是最终存储数据用的在HDFS之上的真实文件。就是说,假如你往HBase中保存了你心仪小姐姐的照片,那么这个照片最终会被存储到某一个HFile文件中。
这里我们再来淡淡HRegionServer是如何存储数据的。前面在HLog部分只讲了HBase数据存储的三分之一。HRegionServer在收到数据存储的请求以后,首先会将这些要被存储的数据写到HLog中。当HLog中写成功以后,再将这些数据写到MemStore中。而MemStore由于是内存,你往内存中写数据那速度就快了,在往内存中也写成功以后呢,HRegionServer就要向Client返回一个“我已经把你要我保存的数据保存起来了”的信号了。但是实际上HRegionServer在“骗”你。这个时候你如果到HDFS的后台上去看,你根本找不到你要保存的那段数据的文件。换句话说,HBase之所以要管理起大数据来速度这么快,很大一部分功劳在于它是一个很“狡猾的骗子”。HRegionServer啊,只有在MemStore中存储的数据达到一定的量以后,才会一次性的将这些数据输出到HFile中。其实这种方式优点还是很明显的,既以提升“Client的响应”速度,又能减少IO操作,在数据存储中,减少IO就意味着延长存储介质的寿命,存储介质寿命延长了更意味着企业能降低运维成本。厉害了。。。
好了关于HBase的存储流程,当然没有这么简单,但是在这里仅需要简单地了解这些就够了,慢慢来嘛,整个HBase系统可是比女人心还要复杂的,一下子让你接受太多,恐怕你要受不住啊。。。
在知道了HRegionServer的组成以后,就可以了解了解HRegionServer的职责了。
1、托管数据
前面我们已经知道了HMaster它只负责作决策。实际的数据存储的工作则全部交由HRegionServer来做。即HRegionServer就是用来存储实际数据的。
2、维护HLog
负责更新或删除HLog中的内容。HLog是直接按行存储的,即只要你客户端发送一次存储请求过来,我都直接在HLog的末尾按一定格式添加进去,不给你分类。并且在这些数据内容被持久化到HDFS中以后,会删除掉HLog中对应的信息。
3、大、小合并。
就是minor compaction与major compaction。简言之,如果HBase系统中小文件太多了,将它合并成一个大一点的文件。
4、监控Region
HRegionServer监控Region的什么东西呢? 当然是监控它的尺寸了。你想想嘛,HBase就是号称针对大数据高速检索的数据库,你一个Region要是过于庞大那就是一个文件过于庞大,那它还怎么来保证大数据的高速检索。HRegionServer会定期将自己管辖的Region的尺寸数据生成一个报告发给HMaster。如果HMaster发现某个Region过大了,就要下达指令,让HRegionServer将这个Region分割成2块。下达分割指令的是HMaster,指令的执行者是RegionServer。
2.4、Hadoop
Hadoop也是Apache软件基金会的顶级项目。它是一个分布式系统架构。
它在HBase系统中就负责帮RegionServer以分布式的方式管理各个HFile文件。
再说的通俗一点吧。把整个HBase系统比喻成一家企业。Master是这家企业的老板,Slaver可以比喻成是公司财务。数据比喻成是资金。由老板下达决策,将所有资金划拨到不同用途。财务负责帮老板管钱。那这么多的钱,财务精力有限能力有限,不可能自己管的过来啊。那怎么办?只能交给银行来管了。Hadoop,也就是HDFS就起到类似于银行的角色。
这篇文章已经够长了,就只聊这么多了。个人认为,如果你是一个初学者的话,就不要一下子灌输太多的概念,一来很难消化的了这么多内容,二来容易打击自己的积极性。只了解一个基本的概念,详细的知识可以在后面的使用过程中慢慢学习。这里尤其千万要告诫你们的一点就是:初学者不要接触HBase源代码。不解释,信我,没错的。
- The end -
HBase轻松入门之HBase架构图解析的更多相关文章
- HBase架构深度解析
原文出处: DLevin(@雪地脚印_) 前记 公司内部使用的是MapR版本的Hadoop生态系统,因而从MapR的官网看到了这篇文文章:An In-Depth Look at the HBase A ...
- HBase系统入门--整体介绍
转自:http://www.aboutyun.com/thread-8957-1-2.html 问题导读:1.HBase查询与写入哪个更好一些?2.HBase面对复杂操作能否实现?3.Region服务 ...
- HBase(一)HBase入门简介
一 HBase 的起源 HBase 的原型是 Google 的 BigTable 论文,受到了该论文思想的启发,目前作为 Hadoop 的子项目来开发维护,用于支持结构化的数据存储. Apache H ...
- 【HBase】HBase Getting Started(HBase 入门指南)
入门指南 1. 简介 Quickstart 会让你启动和运行一个单节点单机HBase. 2. 快速启动 – 单点HBase 这部分描述单节点单机HBase的配置.一个单例拥有所有的HBase守护线程- ...
- HBase、HDFS和MapReduce架构异同简解
HBase.HDFS和MapReduce架构异同 .. HBase(公司架构模型) HDFS2.0(公司架构模型) MR2.0(公司架构模型) MR1.0(公司架构模型) 中央 HMaster Nam ...
- 【CDN+】 Hbase入门 以及Hbase shell基础命令
前言 大数据的基础离不开Hbase, 本文就hbase的基础概念,特点,以及框架进行简介, 实际操作种需要注意hbase shell的使用. Hbase 基础 官网:https://hbase.ap ...
- 【HBase】HBase基本介绍和基础架构
目录 基本介绍 概述 特点 HBase和Hadoop的关系 RDBMS与HBase的对比 特征 基础架构 基本介绍 概述 HBase是bigtable的开源java版本,是建立在HDFS之上,提供高可 ...
- MySql轻松入门系列————第一站 从源码角度轻松认识mysql整体框架图
一:背景 1. 讲故事 最近看各大技术社区,不管是知乎,掘金,博客园,csdn基本上看不到有小伙伴分享sqlserver类的文章,看样子这些年sqlserver没落了,已经后继无人了,再写sqlser ...
- HBase概念入门
HBase简介 HBase基于Google的BigTable论文而来,是一个分布式海量列式非关系型数据库系统,可以提供大规模数据集的实时随机读写. 下面通过一个小场景认识HBase存储.同样的一个数据 ...
随机推荐
- CentOS7 分布式安装 Hadoop 2.8
1. 基本环境 1.1 操作系统 操作系统:CentOS7.3 1.2 三台虚拟机 172.20.20.100 master 172.20.20.101 slave1 172.20.20.102 sl ...
- 日志管理工具之logrotate
Logrotate配置和测试 logrotate软件是一个日志管理工具,用于非分隔日志,删除旧的日志文件,并创建新的日志文件,起到“转储作用”,可以为系统节省磁盘空间.logrotate是基于cron ...
- 让自定义view宽高成比例显示
有时候我们自定义一个View,比如ImageView,我们需要让它宽高按照一定的比例显示,例如在ImageView在GridView中显示,GridView设置了3列,由于ImageVIew的宽度会根 ...
- JSONObject.parseObject
{ "data":{ "shop_uid":"123"; “id”:"123" } } 将上面的json字符串转换为JS ...
- Android 解析标准的点击第三方文件管理器中的视频的intent
解析标准的第三方视频intent private List<String> mCurPlayList = new ArrayList<String>(); private in ...
- Elasticsearch 安装操作手册
第一部分 ES安装环境的准备和初始化 现在交心的版本Elasticsearch 5.6.3 官方建议安装Oracle的JDK8,安装前先检查机器是否已安装JDK. Step 1 检查环境机器是否已安装 ...
- SQL Server Mirror 断开后,删除副本上镜像数据库
一般而言,SQL Server 在数据库级别进行数据同步的方式主要有三种 1.日志传送:2.Mirror(镜像):3. AlwaysOn.复制订阅技术理解为表级别的同步,不归结为数据库级别的同步. 在 ...
- C#中的?和??,null和Nullable
from : https://www.cnblogs.com/appleyrx520/p/7018610.html C#单问号(?)与双问号(??) 1.单问号(?) 1.1 单问号运算符可以表示 ...
- (转)聊聊Greenplum的那些事
开卷有益——作者的话 有时候真的感叹人生岁月匆匆,特别是当一个IT人沉浸于某个技术领域十来年后,蓦然回首,总有说不出的万千感慨. 笔者有幸从04年就开始从事大规模数据计算的相关工作,08年作为Gree ...
- VSCode的Python扩展下程序运行的几种方式与环境变量管理
在VSCode中编写Python程序时,由于有些地方要使用环境变量,但是发现设置的环境变量有时不起作用,花了点时间研究了一下,过程不表,直接说结论. 首先,环境变量的设置,Python扩展中有三种方式 ...