MapReduce编程:数字排序
问题描述
将乱序数字按照升序排序。

思路描述
按照mapreduce的默认排序,依次输出key值。
代码
package org.apache.hadoop.examples; import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class sort {
public sort() {
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); String fileAddress = "hdfs://localhost:9000/user/hadoop/"; //String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
String[] otherArgs = new String[]{fileAddress+"number.txt", fileAddress+"output"};
if(otherArgs.length < 2) {
System.err.println("Usage: sort <in> [<in>...] <out>");
System.exit(2);
} Job job = Job.getInstance(conf, "sort");
job.setJarByClass(sort.class);
job.setMapperClass(sort.TokenizerMapper.class);
//job.setCombinerClass(sort.SortReducer.class);
job.setReducerClass(sort.SortReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class); for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
} FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
} public static class TokenizerMapper extends Mapper<Object, Text, IntWritable, IntWritable> { public TokenizerMapper() {
} public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString()); while(itr.hasMoreTokens()) {
context.write(new IntWritable(Integer.parseInt(itr.nextToken())), new IntWritable(1));
} }
} public static class SortReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> { private static IntWritable num = new IntWritable(1); public SortReducer() {
} public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { for(Iterator<IntWritable> i$ = values.iterator(); i$.hasNext();i$.next()) {
context.write(num, key);
}
num = new IntWritable(num.get()+1);
}
} }

注:不能有combiner操作。
不然就会变成
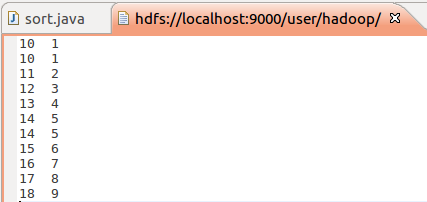
MapReduce编程:数字排序的更多相关文章
- 【原创】MapReduce编程系列之二元排序
普通排序实现 普通排序的实现利用了按姓名的排序,调用了默认的对key的HashPartition函数来实现数据的分组.partition操作之后写入磁盘时会对数据进行排序操作(对一个分区内的数据作排序 ...
- Hadoop MapReduce编程学习
一直在搞spark,也没时间弄hadoop,不过Hadoop基本的编程我觉得我还是要会吧,看到一篇不错的文章,不过应该应用于hadoop2.0以前,因为代码中有 conf.set("map ...
- hadoop2.2编程:使用MapReduce编程实例(转)
原文链接:http://www.cnblogs.com/xia520pi/archive/2012/06/04/2534533.html 从网上搜到的一篇hadoop的编程实例,对于初学者真是帮助太大 ...
- MapReduce编程基础
MapReduce编程基础 1. WordCount示例及MapReduce程序框架 2. MapReduce程序执行流程 3. 深入学习MapReduce编程(1) 4. 参考资料及代码下载 & ...
- MapReduce编程模型及其在Hadoop上的实现
转自:https://www.zybuluo.com/frank-shaw/note/206604 MapReduce基本过程 关于MapReduce中数据流的传输过程,下图是一个经典演示: 关于上 ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- 基于Hadoop 2.6.0运行数字排序的计算
上个博客写了Hadoop2.6.0的环境部署,下面写一个简单的基于数字排序的小程序,真正实现分布式的计算,原理就是对多个文件中的数字进行排序,每个文件中每个数字占一行,排序原理是按行读取后分块进行排序 ...
- [Hadoop入门] - 1 Ubuntu系统 Hadoop介绍 MapReduce编程思想
Ubuntu系统 (我用到版本号是140.4) ubuntu系统是一个以桌面应用为主的Linux操作系统,Ubuntu基于Debian发行版和GNOME桌面环境.Ubuntu的目标在于为一般用户提供一 ...
- mapreduce编程模型你知道多少?
上次新霸哥给大家介绍了一些hadoop的相关知识,发现大家对hadoop有了一定的了解,但是还有很多的朋友对mapreduce很模糊,下面新霸哥将带你共同学习mapreduce编程模型. mapred ...
随机推荐
- 使用java操作elasticsearch(1)
1.安装elasticsearch 这儿用的是5.6.9的版本,下载安装过程较为简单,在官网上下载好后解压到文件夹.需要注意的是在elasticsearch-5.6.9\config下的elastic ...
- 2016(5)系统设计,web应用
试题五(共25分) 阅读以下关于Web应用的叙述,在答题纸上回答问题1至问题3. 某软件企业拟开发一套基于Web的云平台配置管理与监控系统,该系统按租户视图.系统管理视图以及业务视图划分为多个相应的W ...
- linux touch命令 创建文件
touch 创建文件,用法,touch test.txt,如果文件存在,则表示修改当前文件时间 [root@MongoDB ~]# touch /data/text.txt [root@MongoDB ...
- 玩转PIL >>> 玩转photo
前:1.使用图片放在文件最后,需要的请自行下载 2.运行环境win10家庭版,已经安装好pillow库 一.学习总结 PIL库支持图像的储存,显示和处理,几乎能处理所有的图片格式,可以完成对图像的缩放 ...
- 一个农民工混迹于 IT 行业多年后的泣血总结
一看题目,你心里一定闪出一个想法,这又是一篇软文吧,是不是,不想辩别了,自己判断吧哈哈.这是根据本人真实经历所写的一篇总结.假如你满足你的现状,这就是一篇软文,请立刻关闭此文章,继续你现在的生活. ...
- GBDT总结
一.简介 gbdt全称梯度下降树,在传统机器学习算法里面是对真实分布拟合的最好的几种算法之一,在前几年深度学习还没有大行其道之前,gbdt在各种竞赛是大放异彩.原因大概有几个,一是效果确实挺不错.二是 ...
- Sublime 个人配置
Sublime 个人配置 用的faltland主题,之后还加了一些自己喜欢的东西. 效果图如下: { "always_show_minimap_viewport": true, & ...
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD, R-FCN系列深度学习检测方法梳理
1. R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation 技术路线:selec ...
- 《ASP.NET Core In Action》读书笔记系列,这是一个手把手的从零开始的教学系列目录
最近打算系统学习一下asp.net core ,苦于没有好的中文书藉,只好找来一本英文的 <ASP.NET Core In Action>学习.我和多数人一样,学习英文会明显慢于中文.希 ...
- python学习笔记之线程、进程和协程(第八天)
参考文档: 金角大王博客:http://www.cnblogs.com/alex3714/articles/5230609.html 银角大王博客:http://www.cnblogs.com/wup ...