外部 Storage Provider【转】
如果 Kubernetes 部署在诸如 AWS、GCE、Azure 等公有云上,可以直接使用云硬盘作为 Volume,下面是 AWS Elastic Block Store 的例子:
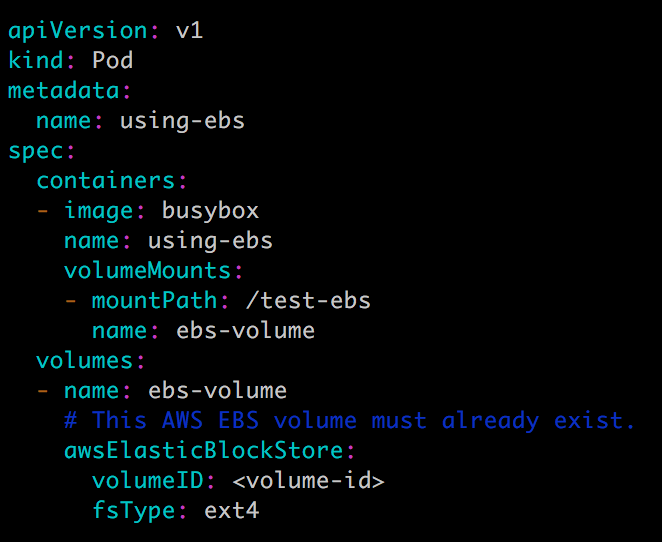
要在 Pod 中使用 ESB volume,必须先在 AWS 中创建,然后通过 volume-id 引用。其他云硬盘的使用方法可参考各公有云厂商的官方文档。
Kubernetes Volume 也可以使用主流的分布式存,比如 Ceph、GlusterFS 等,下面是 Ceph 的例子:
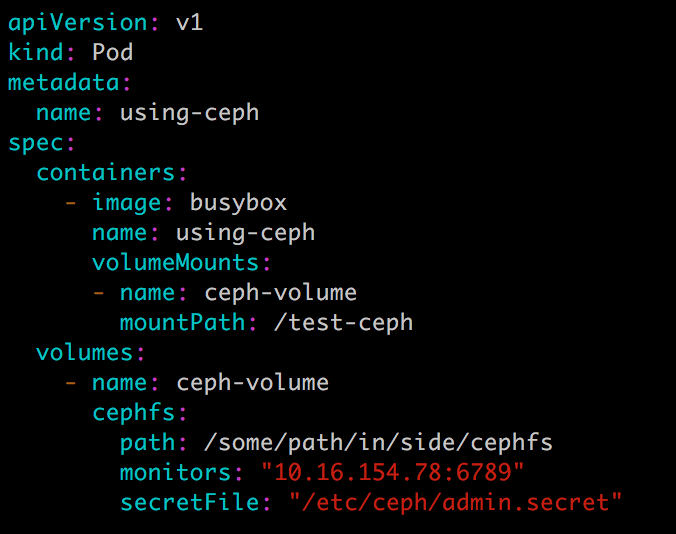
Ceph 文件系统的 /some/path/in/side/cephfs 目录被 mount 到容器路径 /test-ceph。
相对于 emptyDir 和 hostPath,这些 Volume 类型的最大特点就是不依赖 Kubernetes。Volume 的底层基础设施由独立的存储系统管理,与 Kubernetes 集群是分离的。数据被持久化后,即使整个 Kubernetes 崩溃也不会受损。
当然,运维这样的存储系统通常不是项简单的工作,特别是对可靠性、高可用和扩展性有较高要求时。
Volume 提供了非常好的数据持久化方案,不过在可管理性上还有不足。下一节我们将学习具有更高管理性的存储方案:PersistentVolume & PersistentVolumeClaim。
外部 Storage Provider【转】的更多相关文章
- 外部 Storage Provider - 每天5分钟玩转 Docker 容器技术(149)
如果 Kubernetes 部署在诸如 AWS.GCE.Azure 等公有云上,可以直接使用云硬盘作为 Volume,下面是 AWS Elastic Block Store 的例子: 要在 Pod 中 ...
- Swarm 如何存储数据?- 每天5分钟玩转 Docker 容器技术(103)
service 的容器副本会 scale up/down,会 failover,会在不同的主机上创建和销毁,这就引出一个问题,如果 service 有要管理的数据,那么这些数据应该如何存放呢? 选项一 ...
- centos7下安装docker(24docker swarm 数据管理)
service的容器副本会scal up/down,会failover,会在不同的主机上创建和销毁,这就引出一个问题,如果service有数据,那么这些数据该如何存放呢? 1.打包在容器中: 显然不行 ...
- k8s管理存储资源
1. Kubernetes 如何管理存储资源 理解volume 首先我们学习 Volume,以及 Kubernetes 如何通过 Volume 为集群中的容器提供存储:然后我们会实践几种常用的 Vol ...
- linux运维、架构之路-K8s数据管理
一.Volume介绍 容器和Pod是短暂的,它们的生命周期可能很短,会被频繁的销毁和创建,存在容器中的数据会被清除,为了持久化保存容器的数据,k8s提供了Volume.Volume的生命周期独立于容器 ...
- kubernetes管理存储
一.Kubernetes 如何管理存储资源: 理解volume 首先我们学习 Volume,以及 Kubernetes 如何通过 Volume 为集群中的容器提供存储:然后我们会实践几种常用的 Vol ...
- k8s总结复习
一.k8s介绍 Kubernetes(k8s)是Google开源的容器集群管理系统.在Docker技术的基础上,为容器化的应用提供部署运行.资源调度.服务发现和动态伸缩等一系列完整功能,提高了大规模 ...
- k8s 管理存储资源(10)
一.Kubernetes 如何管理存储资源 理解Volume 我们经常会说:容器和 Pod 是短暂的. 其含义是它们的生命周期可能很短,会被频繁地销毁和创建.容器销毁时,保存在容器内部文件系统中的数据 ...
- kubernetes之数据管理
volume emptyDir [machangwei@mcwk8s-master ~]$ kubectl apply -f mcwVolume1.yml #部署emptydir pod/produc ...
随机推荐
- 二、点击导出按钮创建excle写入内容后下载功能实现
/*涉及的jar包1)biframework.jar用于实现分页功能2)poi-3.7-20101029.jar:读取.创建.修改excle.word.ppt的Java APIApache POI是创 ...
- R语言 使用rmarkdown写代码
1.如果是第一次新建markdown文件,需要在有网的条件下,因为要下载一个包才能用markdown 2.为什么使用rmarkdown 使用markdown不仅可以边调试边运行,还可以一次性将所调试好 ...
- 大数据萌新的Python学习之路(二)
笔记内容: 一.模块 Python越来越被广大程序员使用,越来越火爆的原因是因为Python有非常丰富和强大标准库和第三方库,几乎可以实现你所想要实现的任何功能,并且都有相应的Python库支持,比如 ...
- 物流跟踪 调用快递鸟API
概要:关于调用快递鸟API,我有几句话想说,有几行代码想写 业务需求:就是做做商城,卖卖东西.然后需要做个物流跟踪的功能 需要获取的信息大概就是这个样子 现在看这个快递怎么这么慢 如何实现? 直接调用 ...
- 五 Hibernate的其他API,Query&Criteria&SQLQuery
Query Criteria SQLQuery Query接口:用于接收HQL,用于查询多个对象 HQL:Hibernate Query Language Query条件查询: Query分页查询: ...
- docker-lnmp 多容器部署 Laravel 方案分享(转)
docker lnmp 多容器部署方案.完全基于 docker 官方镜像,遵循最佳实践,一容器一进程. github 项目地址 https://github.com/March7/docker-lnm ...
- 虚拟机下安装win7
参考博客:https://blog.csdn.net/weixin_43465312/article/details/92662519 下载地址:https://msdn.itellyou.cn/
- HiBench成长笔记——(1) HiBench概述
测试分类 HiBench共计19个测试方向,可大致分为6个测试类别:分别是micro,ml(机器学习),sql,graph,websearch和streaming. 2.1 micro Benchma ...
- 【Winform】ProgressBar
var progressBar1 = new System.Windows.Forms.ProgressBar(); ; progressBar1.Maximum = ; progressBar1.V ...
- es和数据类型
js=es+dom+bom,dom和bom前面已经讲完了 es是js的本体,是指数据类型,和对于数据的操作手段,他的版本更新得很快 这些功能不是html文件提供的,也不是浏览器提供的,即使脱离了dom ...