数据结构:用实例分析ArrayList与LinkedList的读写性能
背景
ArrayList与LinkedList是Java编程中经常会用到的两种基本数据结构,在书本上一般会说明以下两个特点:
- 对于需要快速随机访问元素,应该使用ArrayList。
- 对于需要快速插入,删除元素,应该使用LinkedList。
该文通过实际的例子分析这两种数据的读写性能。
ArrayList
ArrayList是实现了基于动态数组的数据结构:
private static final int DEFAULT_CAPACITY = 10;
...
transient Object[] elementData;
...
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
LinkedList
LinkedList是基于链表的数据结构。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
...
transient Node<E> first;
transient Node<E> last;
...
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
实例分析
- 通过对两个数据结构分别增加、插入、遍历进行读写性能分析
1、增加数据
public class ArrayListAndLinkList {
public final static int COUNT=100000;
public static void main(String[] args) {
// ArrayList插入
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
Long start = System.currentTimeMillis();
System.out.println("ArrayList插入开始时间:" + sdf.format(start));
ArrayList<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < COUNT; i++) {
arrayList.add(i);
}
Long end = System.currentTimeMillis();
System.out.println("ArrayList插入结束时间:" + sdf.format(end));
System.out.println("ArrayList插入" + (end - start) + "毫秒");
// LinkedList插入
start = System.currentTimeMillis();
System.out.println("LinkedList插入开始时间:" + sdf.format(start));
LinkedList<Integer> linkedList = new LinkedList<>();
for (int i = 0; i < COUNT; i++) {
linkedList.add(i);
}
end = System.currentTimeMillis();
System.out.println("LinkedList插入结束时间:" + sdf.format(end));
System.out.println("LinkedList插入结束时间" + (end - start) + "毫秒");
}
}
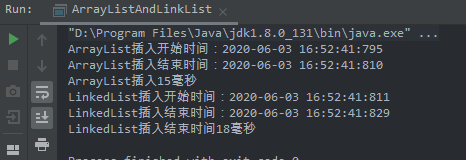
输出如下:
两者写入的性能相差不大!
2、插入数据
在原有增加的数据上,在index:100的位置上再插入10万条数据。
public class ArrayListAndLinkList {
public final static int COUNT=100000;
public static void main(String[] args) {
// ArrayList插入
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
Long start = System.currentTimeMillis();
System.out.println("ArrayList插入开始时间:" + sdf.format(start));
ArrayList<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < COUNT; i++) {
arrayList.add(i);
}
for (int i = 0; i < COUNT; i++) {
arrayList.add(100,i);
}
Long end = System.currentTimeMillis();
System.out.println("ArrayList插入结束时间:" + sdf.format(end));
System.out.println("ArrayList插入" + (end - start) + "毫秒");
// LinkedList插入
start = System.currentTimeMillis();
System.out.println("LinkedList插入开始时间:" + sdf.format(start));
LinkedList<Integer> linkedList = new LinkedList<>();
for (int i = 0; i < COUNT; i++) {
linkedList.add(i);
}
for (int i = 0; i < COUNT; i++) {
linkedList.add(100,i);
}
end = System.currentTimeMillis();
System.out.println("LinkedList插入结束时间:" + sdf.format(end));
System.out.println("LinkedList插入结束时间" + (end - start) + "毫秒");
}
}
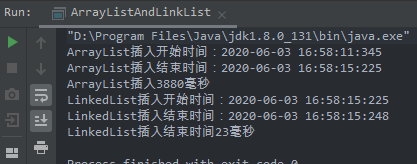
输出如下:
ArrayList的性能明显比LinkedList的性能差了很多。
看下原因:
ArrayList的插入源码:
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
ArrayList的插入原理:在index位置上插入后,在index后续的数据上需要做逐一复制。

LinkedList的插入源码:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
...
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
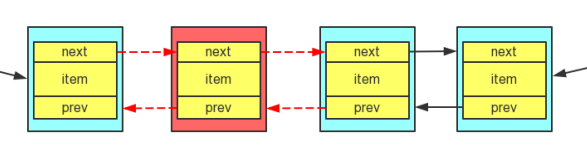
LinkedList的插入原理:在原来相互链接的两个节点(Node)断开,把新的结点插入到这两个节点中间,根本不存在复制这个过程。
3、遍历数据
在增加和插入的基础上,利用get方法进行遍历。
public class ArrayListAndLinkList {
public final static int COUNT=100000;
public static void main(String[] args) {
// ArrayList插入
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
Long start = System.currentTimeMillis();
System.out.println("ArrayList插入开始时间:" + sdf.format(start));
ArrayList<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < COUNT; i++) {
arrayList.add(i);
}
for (int i = 0; i < COUNT; i++) {
arrayList.add(100,i);
}
Long end = System.currentTimeMillis();
System.out.println("ArrayList插入结束时间:" + sdf.format(end));
System.out.println("ArrayList插入" + (end - start) + "毫秒");
// LinkedList插入
start = System.currentTimeMillis();
System.out.println("LinkedList插入开始时间:" + sdf.format(start));
LinkedList<Integer> linkedList = new LinkedList<>();
for (int i = 0; i < COUNT; i++) {
linkedList.add(i);
}
for (int i = 0; i < COUNT; i++) {
linkedList.add(100,i);
}
end = System.currentTimeMillis();
System.out.println("LinkedList插入结束时间:" + sdf.format(end));
System.out.println("LinkedList插入结束时间" + (end - start) + "毫秒");
// ArrayList遍历
start = System.currentTimeMillis();
System.out.println("ArrayList遍历开始时间:" + sdf.format(start));
for (int i = 0; i < 2*COUNT; i++) {
arrayList.get(i);
}
end = System.currentTimeMillis();
System.out.println("ArrayList遍历开始时间:" + sdf.format(end));
System.out.println("ArrayList遍历开始时间" + (end - start) + "毫秒");
// LinkedList遍历
start = System.currentTimeMillis();
System.out.println("LinkedList遍历开始时间:" + sdf.format(start));
for (int i = 0; i < 2*COUNT; i++) {
linkedList.get(i);
}
end = System.currentTimeMillis();
System.out.println("LinkedList遍历开始时间:" + sdf.format(end));
System.out.println("LinkedList遍历开始时间" + (end - start) + "毫秒");
}
}
输出如下:
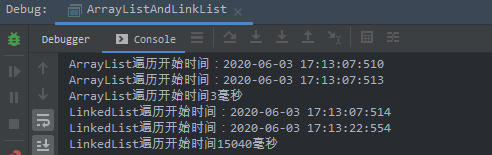
两者的差异巨大:
我们看一下LInkedList的get方法:从头遍历或从尾部遍历结点
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
...
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
3.1、LinkedList遍历改进
我们采用迭代器对LinkedList的遍历进行改进:
...
// LinkedList遍历
start = System.currentTimeMillis();
System.out.println("LinkedList遍历开始时间:" + sdf.format(start));
Iterator<Integer> iterator = linkedList.iterator();
while(iterator.hasNext()){
iterator.next();
}
end = System.currentTimeMillis();
System.out.println("LinkedList遍历开始时间:" + sdf.format(end));
System.out.println("LinkedList遍历开始时间" + (end - start) + "毫秒");
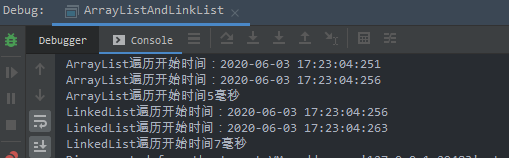
再看下结果:
两者的遍历性能接近。
总结
- List使用首选ArrayList。对于个别插入删除非常多的可以使用LinkedList。
- LinkedList,遍历建议使用Iterator迭代器,尤其是数据量较大时LinkedList避免使用get遍历。
数据结构:用实例分析ArrayList与LinkedList的读写性能的更多相关文章
- 请说出ArrayList,Vector, LinkedList的存储性能和特性
请说出ArrayList,Vector, LinkedList的存储性能和特性 解答:ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都 ...
- [源码分析]ArrayList和LinkedList如何实现的?我看你还有机会!
文章已经收录在 Github.com/niumoo/JavaNotes ,更有 Java 程序员所需要掌握的核心知识,欢迎Star和指教. 欢迎关注我的公众号,文章每周更新. 前言 说真的,在 Jav ...
- Arraylist、Linkedlist遍历方式性能分析
本文主要介绍ArrayList和LinkedList这两种list的常用循环遍历方式,各种方式的性能分析.熟悉java的知道,常用的list的遍历方式有以下几种: 1.for-each List< ...
- 说出ArrayList,Vector, LinkedList的存储性能和特性
ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插 ...
- 【Java面试题】37 说出ArrayList,Vector, LinkedList的存储性能和特性
ArrayList和Vector都是使用数组方式存储数据,此 数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插 ...
- ArrayList,Vector, LinkedList的存储性能和特性
ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入 ...
- ArrayList,Vector, LinkedList 的存储性能和特性
ArrayList 和Vector他们底层的实现都是一样的,都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内 ...
- Java中arraylist和linkedlist源代码分析与性能比較
Java中arraylist和linkedlist源代码分析与性能比較 1,简单介绍 在java开发中比較经常使用的数据结构是arraylist和linkedlist,本文主要从源代码角度分析arra ...
- 【Java】 ArrayList和LinkedList实现(简单手写)以及分析它们的区别
一.手写ArrayList public class ArrayList { private Object[] elementData; //底层数组 private int size; //数组大小 ...
随机推荐
- UEFI Shell --常用命令解释
UEFI Shell解释 UEFI Shell 是一个提供用户和UEFI系统之间的接口,进入UEFI Shell可以对计算机系统进行配置 命令解释: 单独的help就可以输出所有指令,不做特殊说明,内 ...
- 黑马程序员_毕向东_Java基础视频教程——if 语句(单条语句)(随笔)
if 语句(单条语句) 格式(三种) [注意]:如果 if 控制的语句只有一条,则 这个 { } 括号可以不写 if (条件表达式) { 执行语句; } class Test{ public stat ...
- Docker 镜像制作教程:针对不同语言的精简策略
本系列文章将分为三个部分: 第一部分着重介绍多阶段构建(multi-stage builds),因为这是镜像精简之路至关重要的一环.在这部分内容中,我会解释静态链接和动态链接的区别,它们对镜像带来的影 ...
- Docker之docker log详解
1.显示所有log docker logs [OPTIONS] <CONTAINER> #显示某个容器的所有log docker-compose logs #显示启动的所有容器的lo ...
- chrome "items hidden by filters"
今天更新chrome 后遇到console不能显示errors的问题,折腾一番后发现在console的Default levels中选择Default即可.
- Java Mail 发送带有附件的邮件
1.小编用的是163邮箱发送邮件,所以要先登录163邮箱开启POP3/SMTP/IMAP服务方法: 2.下载所需的java-mail 包 https://maven.java.net/content/ ...
- 5.6 Go 常用函数
5.6 Go 常用函数 最正确的学习模块姿势: https://golang.org/pkg/ //golang官网 程序开发常用函数 strings处理字符串相关 统计字符串长度,按字节 len(s ...
- 5.4 Go 闭包
5.4 Go 闭包 闭包(closure):是由一个函数和其相关的引用环境组合的一个整体.(闭包=函数+引用环境) package main import ( "fmt" ) // ...
- Hyperledger Fabric——balance transfer(二)注册用户
详细分析blance transfer示例的用户注册(register)与登录(enroll)功能. 源码分析 1.首先分析项目根目录的app.js文件中关于用户注册和登录的路由函数.注意这里的tok ...
- dede列表页限制标题长度
{dede:list pagesize ='10' titlelen="45"} <li><a href="[field:arcurl/]"& ...