数据结构:用实例分析ArrayList与LinkedList的读写性能
背景
ArrayList与LinkedList是Java编程中经常会用到的两种基本数据结构,在书本上一般会说明以下两个特点:
- 对于需要快速随机访问元素,应该使用ArrayList。
- 对于需要快速插入,删除元素,应该使用LinkedList。
该文通过实际的例子分析这两种数据的读写性能。
ArrayList
ArrayList是实现了基于动态数组的数据结构:
private static final int DEFAULT_CAPACITY = 10;
...
transient Object[] elementData;
...
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
LinkedList
LinkedList是基于链表的数据结构。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
...
transient Node<E> first;
transient Node<E> last;
...
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
实例分析
- 通过对两个数据结构分别增加、插入、遍历进行读写性能分析
1、增加数据
public class ArrayListAndLinkList {
public final static int COUNT=100000;
public static void main(String[] args) {
// ArrayList插入
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
Long start = System.currentTimeMillis();
System.out.println("ArrayList插入开始时间:" + sdf.format(start));
ArrayList<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < COUNT; i++) {
arrayList.add(i);
}
Long end = System.currentTimeMillis();
System.out.println("ArrayList插入结束时间:" + sdf.format(end));
System.out.println("ArrayList插入" + (end - start) + "毫秒");
// LinkedList插入
start = System.currentTimeMillis();
System.out.println("LinkedList插入开始时间:" + sdf.format(start));
LinkedList<Integer> linkedList = new LinkedList<>();
for (int i = 0; i < COUNT; i++) {
linkedList.add(i);
}
end = System.currentTimeMillis();
System.out.println("LinkedList插入结束时间:" + sdf.format(end));
System.out.println("LinkedList插入结束时间" + (end - start) + "毫秒");
}
}
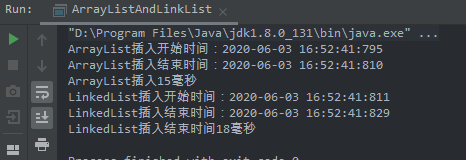
输出如下:
两者写入的性能相差不大!
2、插入数据
在原有增加的数据上,在index:100的位置上再插入10万条数据。
public class ArrayListAndLinkList {
public final static int COUNT=100000;
public static void main(String[] args) {
// ArrayList插入
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
Long start = System.currentTimeMillis();
System.out.println("ArrayList插入开始时间:" + sdf.format(start));
ArrayList<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < COUNT; i++) {
arrayList.add(i);
}
for (int i = 0; i < COUNT; i++) {
arrayList.add(100,i);
}
Long end = System.currentTimeMillis();
System.out.println("ArrayList插入结束时间:" + sdf.format(end));
System.out.println("ArrayList插入" + (end - start) + "毫秒");
// LinkedList插入
start = System.currentTimeMillis();
System.out.println("LinkedList插入开始时间:" + sdf.format(start));
LinkedList<Integer> linkedList = new LinkedList<>();
for (int i = 0; i < COUNT; i++) {
linkedList.add(i);
}
for (int i = 0; i < COUNT; i++) {
linkedList.add(100,i);
}
end = System.currentTimeMillis();
System.out.println("LinkedList插入结束时间:" + sdf.format(end));
System.out.println("LinkedList插入结束时间" + (end - start) + "毫秒");
}
}
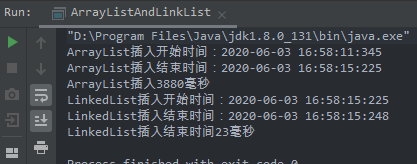
输出如下:
ArrayList的性能明显比LinkedList的性能差了很多。
看下原因:
ArrayList的插入源码:
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
ArrayList的插入原理:在index位置上插入后,在index后续的数据上需要做逐一复制。

LinkedList的插入源码:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
...
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
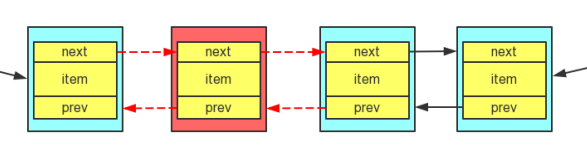
LinkedList的插入原理:在原来相互链接的两个节点(Node)断开,把新的结点插入到这两个节点中间,根本不存在复制这个过程。
3、遍历数据
在增加和插入的基础上,利用get方法进行遍历。
public class ArrayListAndLinkList {
public final static int COUNT=100000;
public static void main(String[] args) {
// ArrayList插入
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
Long start = System.currentTimeMillis();
System.out.println("ArrayList插入开始时间:" + sdf.format(start));
ArrayList<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < COUNT; i++) {
arrayList.add(i);
}
for (int i = 0; i < COUNT; i++) {
arrayList.add(100,i);
}
Long end = System.currentTimeMillis();
System.out.println("ArrayList插入结束时间:" + sdf.format(end));
System.out.println("ArrayList插入" + (end - start) + "毫秒");
// LinkedList插入
start = System.currentTimeMillis();
System.out.println("LinkedList插入开始时间:" + sdf.format(start));
LinkedList<Integer> linkedList = new LinkedList<>();
for (int i = 0; i < COUNT; i++) {
linkedList.add(i);
}
for (int i = 0; i < COUNT; i++) {
linkedList.add(100,i);
}
end = System.currentTimeMillis();
System.out.println("LinkedList插入结束时间:" + sdf.format(end));
System.out.println("LinkedList插入结束时间" + (end - start) + "毫秒");
// ArrayList遍历
start = System.currentTimeMillis();
System.out.println("ArrayList遍历开始时间:" + sdf.format(start));
for (int i = 0; i < 2*COUNT; i++) {
arrayList.get(i);
}
end = System.currentTimeMillis();
System.out.println("ArrayList遍历开始时间:" + sdf.format(end));
System.out.println("ArrayList遍历开始时间" + (end - start) + "毫秒");
// LinkedList遍历
start = System.currentTimeMillis();
System.out.println("LinkedList遍历开始时间:" + sdf.format(start));
for (int i = 0; i < 2*COUNT; i++) {
linkedList.get(i);
}
end = System.currentTimeMillis();
System.out.println("LinkedList遍历开始时间:" + sdf.format(end));
System.out.println("LinkedList遍历开始时间" + (end - start) + "毫秒");
}
}
输出如下:
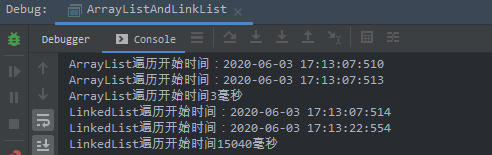
两者的差异巨大:
我们看一下LInkedList的get方法:从头遍历或从尾部遍历结点
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
...
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
3.1、LinkedList遍历改进
我们采用迭代器对LinkedList的遍历进行改进:
...
// LinkedList遍历
start = System.currentTimeMillis();
System.out.println("LinkedList遍历开始时间:" + sdf.format(start));
Iterator<Integer> iterator = linkedList.iterator();
while(iterator.hasNext()){
iterator.next();
}
end = System.currentTimeMillis();
System.out.println("LinkedList遍历开始时间:" + sdf.format(end));
System.out.println("LinkedList遍历开始时间" + (end - start) + "毫秒");
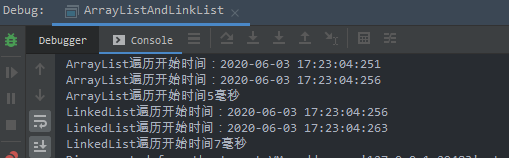
再看下结果:
两者的遍历性能接近。
总结
- List使用首选ArrayList。对于个别插入删除非常多的可以使用LinkedList。
- LinkedList,遍历建议使用Iterator迭代器,尤其是数据量较大时LinkedList避免使用get遍历。
数据结构:用实例分析ArrayList与LinkedList的读写性能的更多相关文章
- 请说出ArrayList,Vector, LinkedList的存储性能和特性
请说出ArrayList,Vector, LinkedList的存储性能和特性 解答:ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都 ...
- [源码分析]ArrayList和LinkedList如何实现的?我看你还有机会!
文章已经收录在 Github.com/niumoo/JavaNotes ,更有 Java 程序员所需要掌握的核心知识,欢迎Star和指教. 欢迎关注我的公众号,文章每周更新. 前言 说真的,在 Jav ...
- Arraylist、Linkedlist遍历方式性能分析
本文主要介绍ArrayList和LinkedList这两种list的常用循环遍历方式,各种方式的性能分析.熟悉java的知道,常用的list的遍历方式有以下几种: 1.for-each List< ...
- 说出ArrayList,Vector, LinkedList的存储性能和特性
ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插 ...
- 【Java面试题】37 说出ArrayList,Vector, LinkedList的存储性能和特性
ArrayList和Vector都是使用数组方式存储数据,此 数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插 ...
- ArrayList,Vector, LinkedList的存储性能和特性
ArrayList和Vector都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入 ...
- ArrayList,Vector, LinkedList 的存储性能和特性
ArrayList 和Vector他们底层的实现都是一样的,都是使用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内 ...
- Java中arraylist和linkedlist源代码分析与性能比較
Java中arraylist和linkedlist源代码分析与性能比較 1,简单介绍 在java开发中比較经常使用的数据结构是arraylist和linkedlist,本文主要从源代码角度分析arra ...
- 【Java】 ArrayList和LinkedList实现(简单手写)以及分析它们的区别
一.手写ArrayList public class ArrayList { private Object[] elementData; //底层数组 private int size; //数组大小 ...
随机推荐
- easytornado
0x01 进入网站,发现3个文件 逐一查看 flag.txt url:?filename=/flag.txt&filehash=d3f3ff3f92c98f5f0ff4b8c423e1c588 ...
- Rabbitmq 整合Spring,SpringBoot与Docker
SpringBootLearning是对Springboot与其他框架学习与研究项目,是根据实际项目的形式对进行配置与处理,欢迎star与fork. [oschina 地址] http://git.o ...
- spark机器学习从0到1介绍入门之(一)
一.什么是机器学习 机器学习(Machine Learning, ML)是一门多领域交叉学科,涉及概率论.统计学.逼近论.凸分析.算法复杂度理论等多门学科.专门研究计算机怎样模拟或实现人类的学习行 ...
- Spring + Struts + Hibernate 简单封装通用接口
1.BaseDao public interface BaseDao<T> { /** * 获取符合条件的记录数 * @param filter * @param sortName * @ ...
- hdu2138 How many prime numbers 米勒测试
hdu2138 How many prime numbers #include <bits/stdc++.h> using namespace std; typedef long long ...
- python操作MySQL之pymysql模块
import pymysql#pip install pymysql db=pymysql.connect(','day040') cursor=db.cursor() #创建游标 book_list ...
- 02.drf不使用serializers返回数据
drf 可以使用不经过model和serialzier的数据返回,也可以配置权限 class DashboardStatusViewset(viewsets.ViewSet): "" ...
- Spring 基于注解的配置 简介
基于注解的配置 从 Spring 2.5 开始就可以使用注解来配置依赖注入.而不是采用 XML 来描述一个 bean 连线,你可以使用相关类,方法或字段声明的注解,将 bean 配置移动到组件类本身. ...
- JavaScript的流程控制语句以及函数
一.流程控制 1. 作用:控制代码的执行顺序 2. 分类 2.1顺序结构:从上到下依次执行代码语句 2.2选择结构: 1. if语句 简单if结构 if(条件表达式){ 表达式成立时执行的代码段 } ...
- [wordpress使用]003_添加新文章
当WordPress前面的工作准备的差不多,没什么大问题时,就可以开始为你的博客添加文章,让博客的内容变得更加丰富.既然你已经开始了这个博客,那么就说明你已经有一个明确的方向,知道自己到底要写那些内容 ...