MySQL 树形索引结构 B树 B+树
MySQL 树形索引结构 B树 B+树
如何评估适合索引的数据结构
- 索引的本质是一种数据结构
- 内存只是临时存储,容量有限且容易丢失数据。因此我们需要将数据放在硬盘上。
- 在硬盘上进行查询时也就产生了硬盘的I/O操作,而硬盘的I/O存取消耗的时间要比读取内存大很多。因此数据查询的时间主要决定于I/O操作的次数。
- 每访问一次节点就需要对磁盘进行一次I/O操作。
树模型
二分查找的时间复杂度是O(log2n),是一种很高效的查询方式。在一系类树种使用二分查找的树有很多,但并不是所有树都适合作为索引的结构。
Binary Search Tree 二叉搜索树(BST)
性质:
- 对任意节点,左子树不为空则左子树所有节点小于或等于该节点的值
- 对任意节点,右子树不为空则右子树所有节点大于或等于该节点的值
但二叉搜索树不一定是"平衡的",它有可能退化成一条链表,那么他的搜索时间就变成了O(n)。
平衡二叉搜索树(AVL)
为了避免退化成一条链表,人们提出了二叉搜索树,AVL在二叉搜索树的基础上增加了约束:
每个节点的左子树和右子树的高度差不能超过1
也就是说要求节点的左右子树仍然为平衡二叉树。
常见的平衡二叉树有很多种,包括了AVL树、红黑树、数堆、伸展树。AVL树是最早提出来的自AVL树,当我们提到平衡二叉树时一般指的就是AVL树
左右平衡后就使得搜索时间复杂度能稳定在O(log2n)。
但是即便在理论上它的搜索效率高且比较稳定,但是由于“每访问一次节点就需要进行一次磁盘I/O操作”,在实际情况中只有两个子节点的情况下,树的高度依然有可能会很高,比如说现有一个五层共31个节点的树,那么我们需要进行5次I/O操作。
B Tree
既然"二叉"结构可能让树变得很高,那么我们自然而然地就明白可以让子节点数变得更多来减少I/O次数。在文件系统和部分数据库系统中,B树就已经得到了实际的应用。
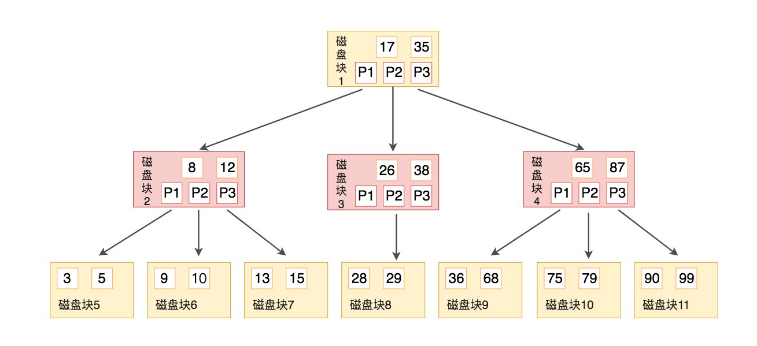
如图所示,B树有如下性质
B树也是平衡的,每个节点可以有M个子节点,M也称为B树的阶
每个磁盘块都包含着关键字和指针,有k-1个关键字,那么就有k个指针,也就是k个子节点。也就等同于
子节点的数量=关键字数量+1所有子节点都在同一层,且每个叶子节点没有子节点,只包含k-1个关键字
子节点和非子节点都即保存数据记录又保存索引。
k-1个关键字相当于划分出了k个范围,每个范围对应一个指针。
例如,有关键字Key[1], Key[2], …, Key[k-1],且关键字按照升序排序
它们划分出k个范围对应k个指针,P[1], P[2], …, P[k]
对应关系就是:P[1]指向关键字小于 Key[1]的子树,P[i]指向关键字属于 (Key[i-1], Key[i]) 的子树,P[k]指向关键字大于 Key[k-1]的子树
在B树上的搜索过程就是:
- 要找目标关键字n,那么就从根节点开始,不断在树的每一层的每两个相邻关键字划定的范围中寻找包含目标关键字的节点,顺着索引一直寻找,直到某节点中关键字与目标关键字相同。
这里说的关键字在实际的数据库中,其实就是一条实际的数据或者主键值,详细可见此处
MongoDB内部使用的就是B树
B+ Tree
主流的RDMS大多采用B+树作为索引结构,包括MySQL的InnoDB引擎(不同存储引擎的索引的工作方式并不一样。而即使多个存储引擎支持同一种类型的索引,其底层的实现也可能不同)
在数据结构性质上与B树不同的是:
- 有K个孩子就有k个关键字。通俗来讲,B树是给每一个范围一个指针,而B+树是给每个子节点直接给一个指针。
- 只有叶子节点保存数据记录,非叶子节点仅用于索引
- 所有关键字都在叶子节点中。每层子节点的关键字也会保存在下一层子节点中且是子节点关键字中最大或最小的那一个,这样到最后,所有关键字都集合在叶子节点中。
- 叶子节点之间会按照关键字的大小从小到大,使用双向链表进行串联。支持了区间查询。
B+树 vs B树
上面说了两种数据结构性质上的不同,下面里对比下实际生产中两种索引结构的区别。
B+树查询效率更稳定。
B+树所有的数据记录都在叶子节点,而B树的数据记录可能在叶子节点也可能在非叶子节点,这样就会导致查询效率的不稳定。
B+树查询效率更高。
B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小。那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
B+树的范围查询效率更高。
B+树所有叶子节点都通过双向链表进行查询,方便范围查询。
而B树因为在非叶子节点中也存有数据记录,因此范围查询时需要通过对树的中序遍历才能完成
MySQL 树形索引结构 B树 B+树的更多相关文章
- mysql系列十、mysql索引结构的实现B+树/B-树原理
一.MySQL索引原理 1.索引背景 生活中随处可见索引的例子,如火车站的车次表.图书的目录等.它们的原理都是一样的,通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的 ...
- 一文读懂MySQL的索引结构及查询优化
回顾前文: 一文学会MySQL的explain工具 (同时再次强调,这几篇关于MySQL的探究都是基于5.7版本,相关总结与结论不一定适用于其他版本) MySQL官方文档中(https://dev.m ...
- mysql的索引为什么要使用B+树而不是其他树?
总结 1.InnoDB存储引擎的最小存储单元是页,页可以用于存放数据也可以用于存放键值+指针,在B+树中叶子节点存放数据,非叶子节点存放键值+指针. 2.索引组织表通过非叶子节点的二分查找法以及指针确 ...
- MySQL索引结构之B+树索引(面)
首先要明白索引(index)是在存储引擎(storage engine)层面实现的,而不是server层面.不是所有的存储引擎都支持所有的索引类型.即使多个存储引擎支持某一索引类型,它们的实现和行为也 ...
- Mysql索引数据结构为什么是B+树?
目录 Mysql索引数据结构 二叉树 红黑树 B-Tree B+Tree Mysql索引数据结构 下面列举了常见的数据结构 二叉树 红黑树 Hash表 B-Tree(B树) Select * from ...
- MySQL 索引结构 hash 有序数组
MySQL 索引结构 hash 有序数组 除了最常见的树形索引结构,Hash索引也有它的独到之处. Hash算法 Hash本身是一种函数,又被称为散列函数. 它的思路很简单:将key放在数组里,用 ...
- 数据库为什么要用B+树结构--MySQL索引结构的实现(转)
B+树在数据库中的应用 { 为什么使用B+树?言简意赅,就是因为: 1.文件很大,不可能全部存储在内存中,故要存储到磁盘上 2.索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数(为什么使用B-/ ...
- 索引很难么?带你从头到尾捋一遍MySQL索引结构,不信你学不会!
前言 Hello我又来了,快年底了,作为一个有抱负的码农,我想给自己攒一个年终总结.自上上篇写了手动搭建Redis集群和MySQL主从同步(非Docker)和上篇写了动手实现MySQL读写分离and故 ...
- 带你从头到尾捋一遍MySQL索引结构(2)
前言 Hello我又来了,快年底了,作为一个有抱负的码农,我想给自己攒一个年终总结.索性这次把数据库中最核心的也是最难搞懂的内容,也就是索引,分享给大家. 这篇博客我会谈谈对于索引结构我自己的看法,以 ...
随机推荐
- java实现第四届蓝桥杯大臣的旅费
大臣的旅费 题目描述 很久以前,T王国空前繁荣.为了更好地管理国家,王国修建了大量的快速路,用于连接首都和王国内的各大城市. 为节省经费,T国的大臣们经过思考,制定了一套优秀的修建方案,使得任何一个大 ...
- ZSH隐藏命令行前面的用户名和主机名
修改vim ~/.zshrc文件,在文件底部增加 隐藏用户名和主机名 prompt_context() {} 只保留用户名,隐藏主机名 prompt_context() { if [[ "$ ...
- Python--编码转换
# -*- coding:gbk -*- # 即使设置文件编码为gbk,下方定义的字符串s1依旧为unicode # 获取默认编码格式 import sys print(sys.getdefaulte ...
- vsftpd服务器配置与使用
1.ftp简介 网络文件的共享主流的主要有三种,分别为ftp.nfs.samba ftp用于internet上的控制文件的双向传输 上传和下载的操作 下载 上传 将主机中的内容拷贝到计算机上 将文件从 ...
- MyISAM 和 InnoDB 索引结构及其实现原理
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询.更新数据库表中数据. 索引的实现通常使用B_TREE. B_TREE索引加速了数据访问,因为存储引擎不会再去扫描整张表得到需要的数据; ...
- Codeforces Round #648 (Div. 2)
链接 : https://codeforces.com/contest/1365/problems problem A 统计可用的行和列的最小值, 模2输出即可 /* * Author: RoccoS ...
- 从零开始的Spring Boot(2、在Spring Boot中整合Servlet、Filter、Listener的方式)
在Spring Boot中整合Servlet.Filter.Listener的方式 写在前面 从零开始的Spring Boot(1.搭建一个Spring Boot项目Hello World):http ...
- LR字符串处理函数-lr_save_int
int lr_save_int(int value,const char * param_name); value:要分配给参数的整数值. param_name:参数的名称. lr_save_in ...
- TCP和UDP的Socket编程实验
Linux Socket 函数库是从 Berkeley 大学开发的 BSD UNIX 系统中移植过来的.BSD Socket 接口是在众多 Unix 系统中被广泛支持的 TCP/IP 通信接口,Lin ...
- 兄弟打印机MFC代码示范
m_strModel.LoadString(IDS_MODEL_STRING); //IDS_MODEL_STRING,字符串控件的ID,资源视图-String Table里面设置 m_strSour ...