Hadoop入门之hdfs
大数据技术开篇之Hadoop入门【hdfs】
学习都是从了解到熟悉的过程,而学习一项新的技术的时候都是从这个技术是什么?可以干什么?怎么用?如何优化?这几点开始。今天这篇文章分为两个部分。一、hadoop概述 二、hadoop核心技术之一的hdfs的讲解。
【hadoop概述】
一、hadoop是什么?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
简单概况就是hadoop是一个分布式系统的基础架构,通过分布式来进行高速运算和存储。
二、用来干什么?
主要用来解决海量数据存储和海量数据运算的问题
三、当前版本
Apach 版本:主要用于自己学习研究方面,免费开源版本
Cloudera:收费版本,企业版本。目前公司商用化最多的版本。
Hortonworks:商业版本,这个版本的优势在于参考文档相对详尽,学习起来比较方便
四、hadoop组成
commons:辅助工具
hdfs:一个分布式高吞吐量,高可靠的分布式文件系统
mapreduce 一个分布式离线计算框架
yarn:作业调度和资源管理的框架。
五、集群模式
单节点模式,伪集群,完整集群。三个模式
HDFS 学习
一、hdfs是什么?
hdfs一个分布式高吞吐量,高可靠的分布式文件系统。
二、hdfs优缺点:
优点:
【1】高容错性,数据自动保存多个副本,一个副本丢失后可以自动恢复
【2】适合大数据的处理
数据可以达到gb,Tb,pb级别,文件处理可以达到百万以上的规模
【3】可以构建在廉价的机器上面,通过多副本来实现可靠性
缺点:
【1】不适合低延时数据访问,比如毫秒级别做不到
【2】无法高效对大量小文件进行存储
【3】不支持文件的随机修改,仅支持文件的追加
三、hdfs的组成:
Client:客户端
【1】文件切分。文件上传时将文件切成一个个block块
【2】与NameNode交互,获取文件的位置信息
【3】与DataNode交互,读取或写入数据
【4】client提供一些命令来管理Hdfs,比如启动或者关闭
【5】client可以通过命令来访问Hdfs
NameNode就是Master,它是一个主管、管理者
【1】管理数据块的原信息
【2】配置副本策略
【3】处理客户端请求
DateNode
【1】存储实际的数据块
【2】执行数据块的读写操作
econdaryNameNode:并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务
【1】辅助NameNode,分担其工作量
【2】定期合并Fsimage和Edits,并推送给NameNode;
【3】在紧急情况下,可辅助恢复NameNode。
四、hdfs文件写入流程
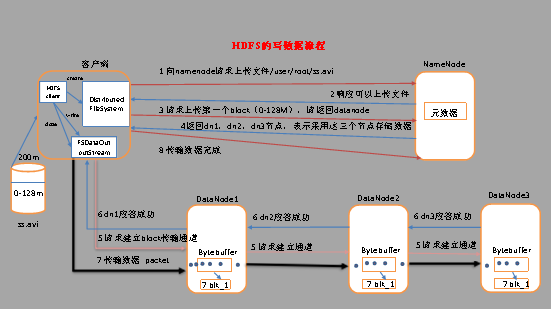
(1) 客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(2) NameNode返回是否可以上传。
(3) 客户端请求第一个 block上传到哪几个datanode服务器上。
(4) NameNode返回3个datanode节点,分别为dn1、dn2、dn3。
(5) 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6) dn1、dn2、dn3逐级应答客户端。
(7) 客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;
(8) 当一个block传输完成之后,客户端再次请求NameNode上传第二个block的服务器。(重复执行3-7步)。
五、hdfs 读文件流程
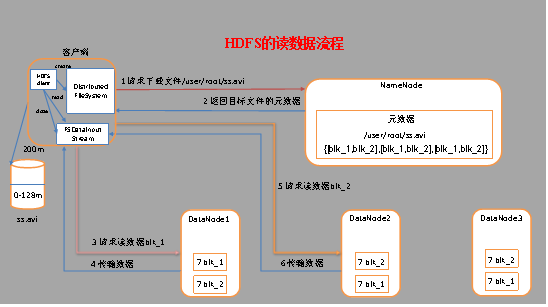
(1) 客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
(2) 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
(3) DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验)。
(4) 客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
六、NN与2NN的工作机制
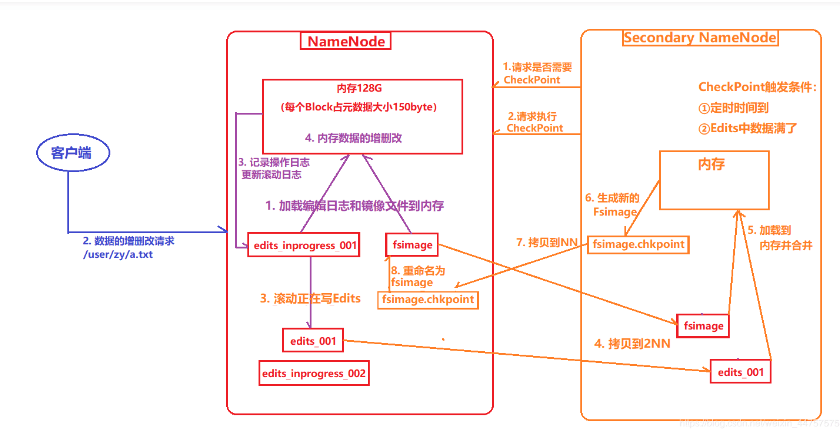
(1) 第一阶段:NameNode启动
a) 第一次启动NameNode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
b) 客户端对元数据进行增删改的请求。
c) NameNode记录操作日志,更新滚动日志。
d) NameNode在内存中对数据进行增删改查。
(2) 第二阶段:Secondary NameNode工作
a) Secondary NameNode询问NameNode是否需要checkpoint。直接带回NameNode是否检查结果。
b) Secondary NameNode请求执行checkpoint。
c) NameNode滚动正在写的edits日志。
d) 将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
e) Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
f) 生成新的镜像文件fsimage.chkpoint。
g) 拷贝fsimage.chkpoint到NameNode。
h) NameNode将fsimage.chkpoint重新命名成fsimage。
NN和2NN工作机制详解:
fsimage:namenode内存中元数据序列化后形成的文件。
edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
namenode启动时,先滚动edits并生成一个空的edits.inprogress,然后加载edits(归档后的)和fsimage(最新的)到内存中,此时namenode内存就持有最新的元数据信息。client开始对namenode发送元数据的增删改查的请求,这些请求的操作首先会被记录在edits.inprogress中(查询元数据的操作不会被记录在edits中,因为查询操作不会更改元数据信息),如果此时namenode挂掉,重启后会从edits中读取元数据的信息。然后,namenode会在内存中执行元数据的增删改查的操作。
由于edits中记录的操作会越来越多,edits文件会越来越大,导致namenode在启动加载edits时会很慢,所以需要对edits和fsimage进行合并(所谓合并,就是将edits和fsimage加载到内存中,照着edits中的操作一步步执行,最终形成新的fsimage)。Secondarynamenode:帮助namenode进行edits和fsimage的合并工作。
secondarynamenode首先会询问namenode是否需要checkpoint(触发checkpoint需要满足两个条件中的任意一个,定时时间到和edits中数据写满了)。直接带回namenode是否检查结果。secondarynamenode执行checkpoint操作,首先会让namenode滚动edits并生成一个空的edits.inprogress,滚动edits的目的是给edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的edits和fsimage会拷贝到secondarynamenode的本地,然后将拷贝的edits和fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给namenode,重命名为fsimage后替换掉原来的fsimage。namenode在启动时就只需要加载之前未合并的edits和fsimage即可,因为合并过的edits中的元数据信息已经被记录在fsimage中。
六、DataName工作机制
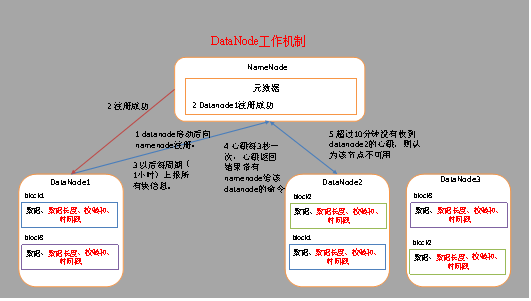
(1) 一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
(2) DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
(3) 心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
今天的hdfs的分享就到这里了,下次会分享MapReduce和Yarn的知识。每天进步一点点,大家一起加油。
Hadoop入门之hdfs的更多相关文章
- Hadoop入门学习笔记-第二天 (HDFS:NodeName高可用集群配置)
说明:hdfs:nn单点故障,压力过大,内存受限,扩展受阻.hdfs ha :主备切换方式解决单点故障hdfs Federation联邦:解决鸭梨过大.支持水平扩展,每个nn分管一部分目录,所有nn共 ...
- Hadoop入门学习笔记---part4
紧接着<Hadoop入门学习笔记---part3>中的继续了解如何用java在程序中操作HDFS. 众所周知,对文件的操作无非是创建,查看,下载,删除.下面我们就开始应用java程序进行操 ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- Hadoop入门学习笔记---part2
在<Hadoop入门学习笔记---part1>中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱.不够系统化,不够简洁.经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建ha ...
- Hadoop入门学习笔记---part1
随着毕业设计的进行,大学四年正式进入尾声.任你玩四年的大学的最后一次作业最后在激烈的选题中尘埃落定.无论选择了怎样的选题,无论最后的结果是怎样的,对于大学里面的这最后一份作业,也希望自己能够尽心尽力, ...
- 初识Hadoop入门介绍
初识hadoop入门介绍 Hadoop一直是我想学习的技术,正巧最近项目组要做电子商城,我就开始研究Hadoop,虽然最后鉴定Hadoop不适用我们的项目,但是我会继续研究下去,技多不压身. < ...
- 大数据:Hadoop入门
大数据:Hadoop入门 一:什么是大数据 什么是大数据: (1.)大数据是指在一定时间内无法用常规软件对其内容进行抓取,管理和处理的数据集合,简而言之就是数据量非常大,大到无法用常规工具进行处理,如 ...
- Python系列之入门篇——HDFS
Python系列之入门篇--HDFS 简介 HDFS (Hadoop Distributed File System) Hadoop分布式文件系统,具有高容错性,适合部署在廉价的机器上.Python ...
- 一.hadoop入门须知
目录: 1.hadoop入门须知 2.hadoop环境搭建 3.hadoop mapreduce之WordCount例子 4.idea本地调试hadoop程序 5.hadoop 从mysql中读取数据 ...
随机推荐
- 原生js实现replace方法
今天看到有人提问js的replace方法怎么实现的,自己就试了试js手册里的String对象的介绍replace大概是这样: string.replace(regexp, replacement) 第 ...
- SpringBoot1.5.10.RELEASE整合druid时,在druid monitor界面出现(*) property for user to setup
接上篇随笔,配置druid之后出现的错误,解决方法如下: @Bean(destroyMethod = "close",initMethod = "init") ...
- TP5使用Redis处理电商秒杀
本篇文章介绍了ThinkPHP使用Redis实现电商秒杀的处理方法,具有一定的参考价值,希望对学习ThinkPHP的朋友有帮助! TP5使用Redis处理电商秒杀 1.首先在TP5中创建抢购活动所需要 ...
- swoole模块的编译安装:php编译安装swoole模块的代码
本篇文章给大家带来的内容是关于swoole模块的编译安装:php编译安装swoole模块的代码,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助. 1.下载swoole 1 wget ht ...
- 03-influxdb原理
influxdb基本操作 1. influxdb与传统数据库区别 influxdb 传统数据库 database 数据库 measurement 表 points 表里的一行数据 2. 基本原理 2. ...
- yarn安装Electron提示安装正常却实际没有安装的解决
起因 使用Quasar框架开发Electron软件,配置好后发现electron没有正常安装,但是yarn却一本正经的胡说八道:不不不,electron已经在那里了.打开模块安装目录一看还真有elec ...
- libfastcommon总结(二)从文件中加载配置信息
头文件为ini_file_reader.h 主要接口 IniContext iniContext;//定义配置文件信息 iniLoadFromFile();//加载文件为结构化配置信息 iniG ...
- .NET Core学习笔记(5)——WebAPI从Server端push消息到Client
标题起得有点厉害,汉字夹杂着E文,不符合教育部公布的“向社会推荐使用的外语词中文译名”规范.不过他管不着我.写本篇的起因,是重构一个现有的WinForms程序,将Server端的部分逻辑从raw so ...
- 使用 Pandas 的 to_excel() 方法来将多个 csv 文件合并到一个 xlsx 的不同 sheets 内
这几天在用 Python3 研究一个爬虫,最后一个需求是把爬下来的20+个csv文件整合到一个excel表里的不同sheets. 初版的核心代码如下: while year <= 2018: c ...
- python获取群成员信息
#coding: utf-8 import itchat,datetime from itchat.content import TEXT itchat.auto_login(hotReload=Tr ...