python3下scrapy爬虫(第七卷:编辑器内执行scrapy)
之前我们都是在终端切入到scrapy的路境内执行爬虫的,你要多敲多少行的字节,所以这次我们谈谈如何在编辑器里执行,这个你可以用在爬虫中,当你使用PYTHONWEB开发时尽量不要在编辑器内启动端口服务那样不容易关闭服务
先来看下我编写的爬虫文件
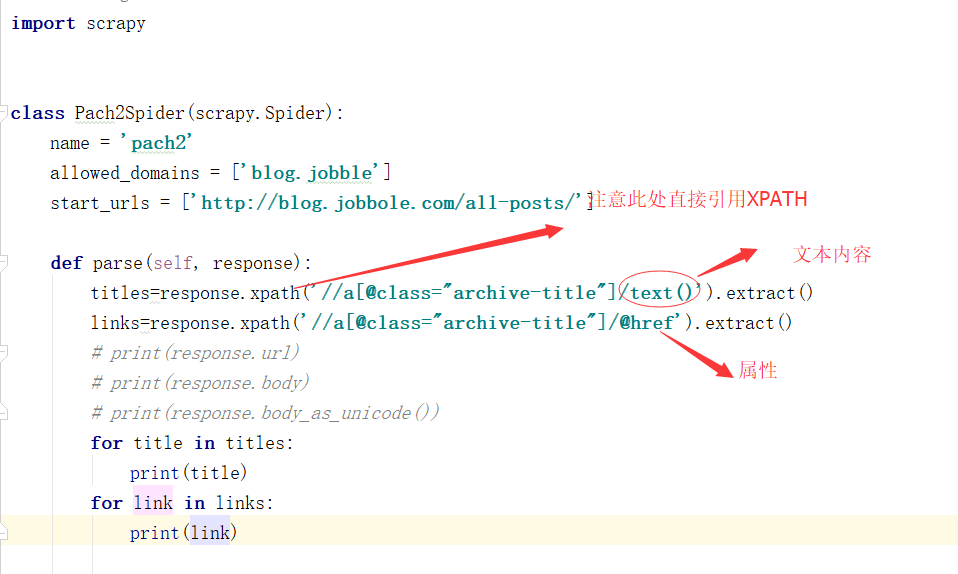
先来看下结果:
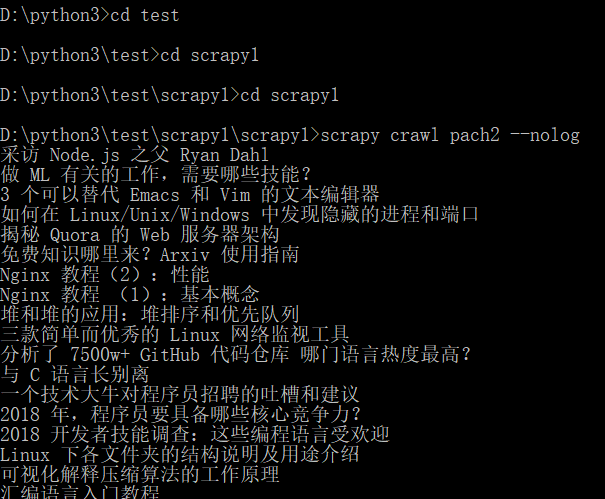
看到了吧不停的切换路径,也同时感到了xpath的强大了吧
总是切换到终端很麻烦,很多人为了炫耀自己的技术的强大都喜欢在终端各种操作,我个人觉得没有意义,明明走直线到家非得拐个弯
现在我们在文件中创建main.py文件 看一下路径 这个文件执行时是调动整个scrapy文件,那么文件创建的路径应该在外,看一下我编辑的位置
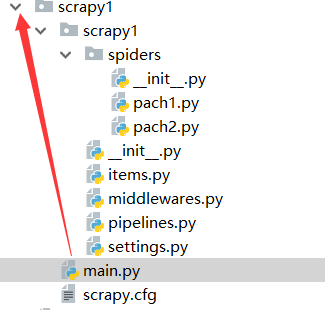
清晰明了 之前我写过pyMySQL的一篇随笔里面函数的用法和这里很相似

现在看下结果 看看哪个方便

python3下scrapy爬虫(第七卷:编辑器内执行scrapy)的更多相关文章
- python3下scrapy爬虫(第五卷:初步抓取网页内容之scrapy全面应用)
现在爬取http://category.dangdang.com/pg1-cid4008149.html网址上的商品价格,名称,评价数量 先准备下下数据:商品名,商品链接,评价数量 第一步:在item ...
- 同时运行多个scrapy爬虫的几种方法(自定义scrapy项目命令)
试想一下,前面做的实验和例子都只有一个spider.然而,现实的开发的爬虫肯定不止一个.既然这样,那么就会有如下几个问题:1.在同一个项目中怎么创建多个爬虫的呢?2.多个爬虫的时候是怎么将他们运行起来 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- python3下scrapy爬虫(第三卷:初步抓取网页内容之抓取网页里的指定数据)
上一卷中我们抓取了网页的所有内容,现在我们抓取下网页的图片名称以及连接 现在我再新建个爬虫文件,名称设置为crawler2 做爬虫的朋友应该知道,网页里的数据都是用文本或者块级标签包裹着的,scrap ...
- python3下scrapy爬虫(第十一卷:scrapy数据存储进mongodb)
说起python爬虫数据存储就不得不说到mongodb,现在我们来试一下scrapy操作mongodb 首先开启mongodb mongod --dbpath=D:\mongodb\db 开启服务后就 ...
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- python3下scrapy爬虫(第六卷:利用cookie模拟登陆抓取个人中心页面)
之前我们爬取的都是那些无需登录就要可以使用的网站但是当我们想爬取自己或他人的个人中心时就需要做登录,一般进入登录页面有两种 ,一个是独立页面登陆,另一个是弹窗,我们先不管验证码登陆的问题 ,现在试一下 ...
- python3下scrapy爬虫(第八卷:循环爬取网页多页数据)
之前我们做的数据爬取都是单页的现在我们来讲讲多页的 一般方式有两种目标URL循环抓取 另一种在主页连接上找规律,现在我用的案例网址就是 通过点击下一页的方式获取多页资源 话不多说全在代码里(因为刚才写 ...
随机推荐
- 吴裕雄--天生自然TensorFlow2教程:数学运算
import tensorflow as tf b = tf.fill([2, 2], 2.) a = tf.ones([2, 2]) a+b a-b a*b a/b b // a b % a tf. ...
- 《打造扛得住的MySQL数据库架构》第3章 MySQL基准测试
3-1 什么是基准测试 测量系统性能,优化是否有效?MySQL基准测试. 定义:基准测试是一种测量和评估软件性能指标的活动,用于建立某个时刻的性能基准,以便当系统发生软硬件 变化时重新进行基准测试以评 ...
- Res-net 标准版本源码差异-官方源码示例
# resnet https://github.com/tensorflow/models/blob/master/research/slim/nets/resnet_v1.py https://gi ...
- MySQL--主备相关命令
创建用户账号 GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO repl@'10.70.8.%' IDENTIFIED BY 'mysql'; ...
- 永久使用mybase
(1)关闭程序 (2)找到程序的安装路径:D:\mybase\mybase\nyfedit7pro (3)打开mybase.ini 文件,7以下版本文件名称为nyfedit.ini
- Kafka学习(学习过程记录)
Apache kafka 这,仅是我学习过程中记录的笔记.确定了一个待研究的主题,对这个主题进行全方面的剖析.笔记是用来方便我回顾与学习的,欢迎大家与我进行交流沟通,共同成长.不止是技术. Kafka ...
- 第一行代码新闻例子报错 Unable to start activity ComponentInfo 原因
E/AndroidRuntime: FATAL EXCEPTION: main Process: com.timemanager.jason.fragmentbestpractice, PID: 56 ...
- Python map filter reduce enumerate zip 的用法
map map(func, list) 把list中的数字,一个一个运用到func中,常和lambda一起用. nums = [1, 2, 3, 4, 5] [*map(lambda x: x**2, ...
- Django专题-Cookie
Cookie Cookie的由来 大家都知道HTTP协议是无状态的. 无状态的意思是每次请求都是独立的,它的执行情况和结果与前面的请求和之后的请求都无直接关系,它不会受前面的请求响应情况直接影响, ...
- Linux bootloader
1.bootloader:初始化相关的硬件 loader:将操作系统从硬盘当中拷贝到内存当中去,,然后让CPU跳转到内存中执行操作系统. 2.boot阶段:(1)关闭影响cpu正常执行的外设 比 ...