python3下scrapy爬虫(第七卷:编辑器内执行scrapy)
之前我们都是在终端切入到scrapy的路境内执行爬虫的,你要多敲多少行的字节,所以这次我们谈谈如何在编辑器里执行,这个你可以用在爬虫中,当你使用PYTHONWEB开发时尽量不要在编辑器内启动端口服务那样不容易关闭服务
先来看下我编写的爬虫文件
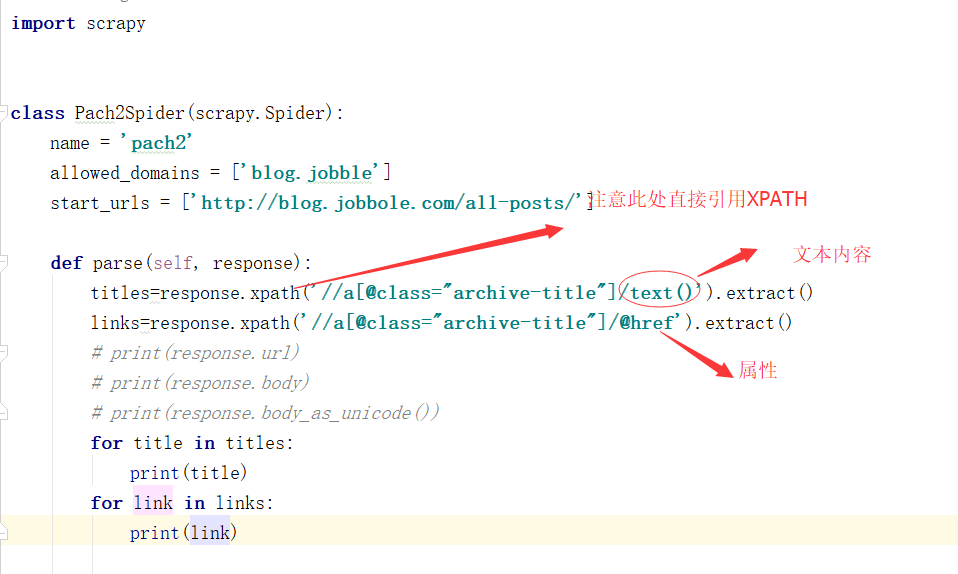
先来看下结果:
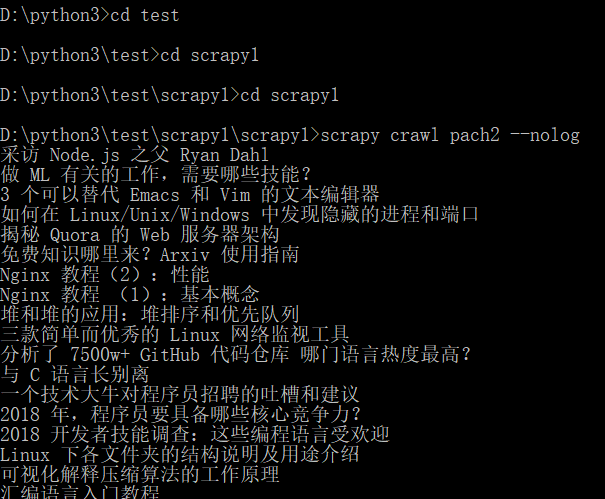
看到了吧不停的切换路径,也同时感到了xpath的强大了吧
总是切换到终端很麻烦,很多人为了炫耀自己的技术的强大都喜欢在终端各种操作,我个人觉得没有意义,明明走直线到家非得拐个弯
现在我们在文件中创建main.py文件 看一下路径 这个文件执行时是调动整个scrapy文件,那么文件创建的路径应该在外,看一下我编辑的位置
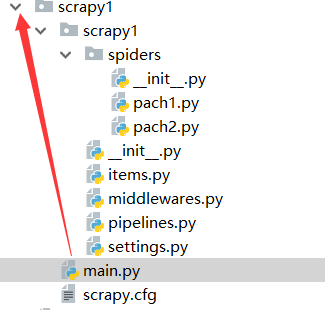
清晰明了 之前我写过pyMySQL的一篇随笔里面函数的用法和这里很相似

现在看下结果 看看哪个方便

python3下scrapy爬虫(第七卷:编辑器内执行scrapy)的更多相关文章
- python3下scrapy爬虫(第五卷:初步抓取网页内容之scrapy全面应用)
现在爬取http://category.dangdang.com/pg1-cid4008149.html网址上的商品价格,名称,评价数量 先准备下下数据:商品名,商品链接,评价数量 第一步:在item ...
- 同时运行多个scrapy爬虫的几种方法(自定义scrapy项目命令)
试想一下,前面做的实验和例子都只有一个spider.然而,现实的开发的爬虫肯定不止一个.既然这样,那么就会有如下几个问题:1.在同一个项目中怎么创建多个爬虫的呢?2.多个爬虫的时候是怎么将他们运行起来 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- python3下scrapy爬虫(第三卷:初步抓取网页内容之抓取网页里的指定数据)
上一卷中我们抓取了网页的所有内容,现在我们抓取下网页的图片名称以及连接 现在我再新建个爬虫文件,名称设置为crawler2 做爬虫的朋友应该知道,网页里的数据都是用文本或者块级标签包裹着的,scrap ...
- python3下scrapy爬虫(第十一卷:scrapy数据存储进mongodb)
说起python爬虫数据存储就不得不说到mongodb,现在我们来试一下scrapy操作mongodb 首先开启mongodb mongod --dbpath=D:\mongodb\db 开启服务后就 ...
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- python3下scrapy爬虫(第六卷:利用cookie模拟登陆抓取个人中心页面)
之前我们爬取的都是那些无需登录就要可以使用的网站但是当我们想爬取自己或他人的个人中心时就需要做登录,一般进入登录页面有两种 ,一个是独立页面登陆,另一个是弹窗,我们先不管验证码登陆的问题 ,现在试一下 ...
- python3下scrapy爬虫(第八卷:循环爬取网页多页数据)
之前我们做的数据爬取都是单页的现在我们来讲讲多页的 一般方式有两种目标URL循环抓取 另一种在主页连接上找规律,现在我用的案例网址就是 通过点击下一页的方式获取多页资源 话不多说全在代码里(因为刚才写 ...
随机推荐
- protobuf 的enum与string转换
c/c++ enum 介绍 说起c/c++ 的enum,比起python 真的是方便简洁 enum type{ type1 = 0, type2 } enum的元素对应的int 默认从0 开始依次增加 ...
- 可塑性|Exosomes
五流解释 肿瘤发源于不同组织如果不从各种组织出发,则不能有正确的解决方法. Hallmarks of cancer LncRNAs操作流 Exosomes ,它的基本故事是平衡流,但是具体内涵是操作流 ...
- [CISCN2019 华北赛区 Day1 Web1]Dropbox-phar文件能够上传到服务器端实现任意文件读取
0x00知识点 phar是什么: 我们先来了解一下流包装 大多数PHP文件操作允许使用各种URL协议去访问文件路径:如data://,zlib://或php://.例如常见的 include('php ...
- tensorflow常用函数库
归一化函数: def norm_boxes(boxes, shape): """Converts boxes from pixel coordinates to norm ...
- Linux下idea由于缺少相关权限导致的tomcat ERROR
昨天一天都在倒腾两个系统,也是醉了. 不过还好,系统修好了,在ubuntu下重新安装idea后,出现了这个错误: Intellij Idea Tmocat Error running Tomcat: ...
- UITableViewCell 的selectedBackgroundView
UITableViewCell中的selectedBackgroundView就是用于当用户点击cell的时候,选择状态的view,你可以对这个view进行颜色或者其他样式等做一些定制,可以达到点击之 ...
- AttributeError: module 'selenium.webdriver.common.service' has no attribute 'Service'
今天爬虫时需要使用到selenium, 使用pip install selenium进行安装. 可是一开始写程序就遇到了AttributeError: module 'selenium.webdriv ...
- Channels(纪念一下卡我心态的一道题)
链接:https://ac.nowcoder.com/acm/contest/3947/C来源:牛客网 题目描述 Nancy喜欢学习,也喜欢看电视. 为了想了解她能看多长时间的节目,不妨假设节目从时刻 ...
- CCPC2019网络赛
2019中国大学生程序设计竞赛(CCPC) - 网络选拔赛 A 题意:找到最小的正整数 C 使得 (A^C)&(B^C) 最小. \(A,B \le 10^9\) 签到题.这个C取 A& ...
- 关于tomcat启动错误:At least one JAR was scanned for TLDs yet contained no TLDs
一.问题原因: 1.出现这个问题的原因就是Tomcat启动时会扫描大量jar包,如果含有不符合TLD规范的就会出现这个问题 2.以后基本上不会使用JSP作为视图层,所以我们可能根本不需要TLD这个东西 ...