为什么jdk1.8 HashMap的容量一定要是2的n次幂
|
1
2
3
4
|
/** * The default initial capacity - MUST be a power of two.(默认初始容量——必须是2的n次幂。) */static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16(16 = 2^4) |
|
1
2
3
|
public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } |
|
01
02
03
04
05
06
07
08
09
10
|
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity);//tableSizeFor(initialCapacity)方法是重点!!! } |
|
01
02
03
04
05
06
07
08
09
10
11
12
|
/** * Returns a power of two size for the given target capacity. */ static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; } |
|
1
2
3
4
5
6
7
8
|
public HashMap(int initialCapacity, float loadFactor) { …… int capacity = 1; while (capacity < initialCapacity) { capacity <<= 1; } ……} |
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
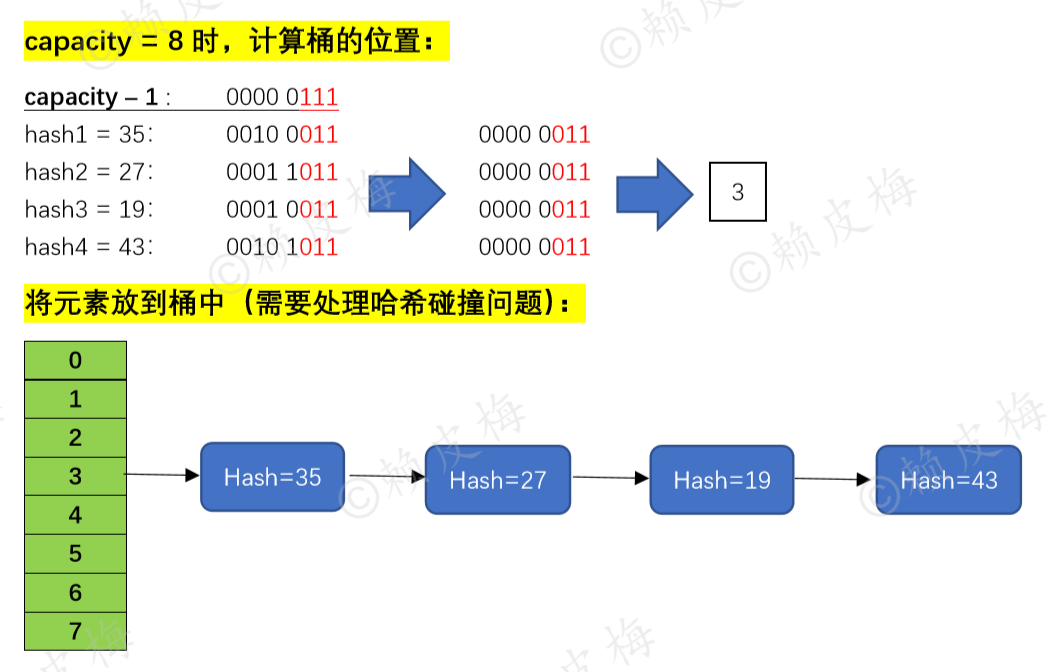
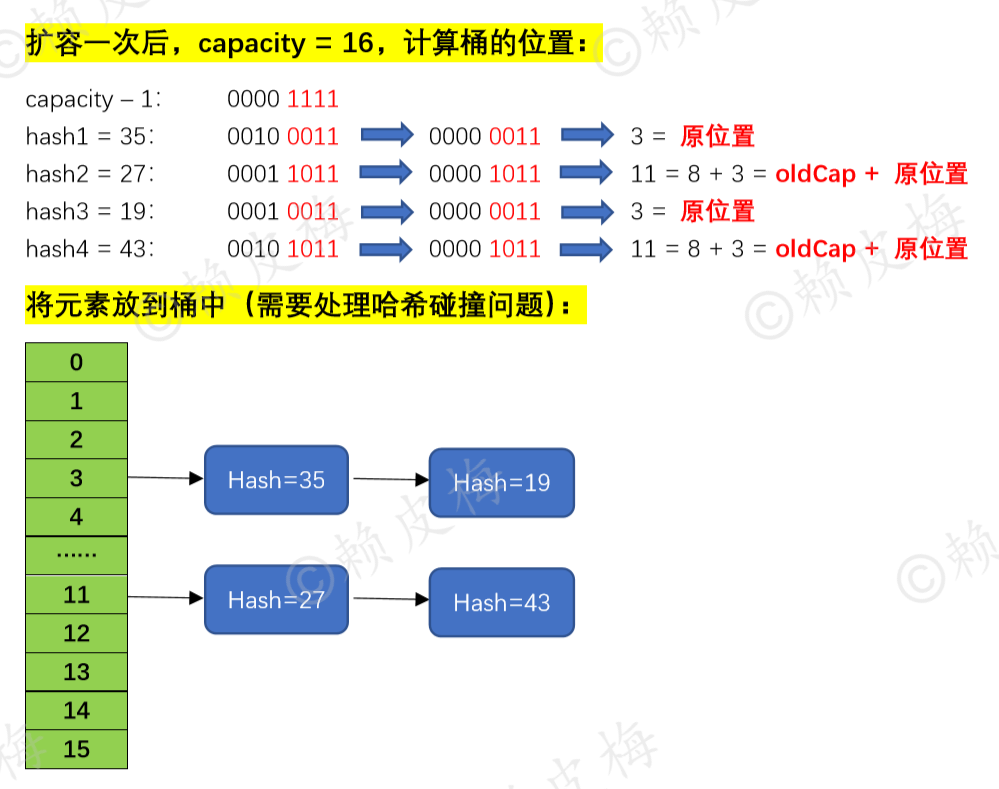
final Node<K,V>[] resize() { //扩容 //---------------- -------------------------- 1.计算新容量(新桶) newCap 和新阈值 newThr。 --------------------------------- Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length;//看容量是否已初始化 int oldThr = threshold;//下次扩容要达到的阈值。threshold(阈值) = capacity * loadFactor。 int newCap, newThr = 0; if (oldCap > 0) {//容量已初始化过了:检查容量和阈值是否达到上限《========== if (oldCap >= MAXIMUM_CAPACITY) {//oldCap >= 2^30,已达到扩容上限,停止扩容 threshold = Integer.MAX_VALUE; return oldTab; } // newCap < 2^30 && oldCap > 16,还能再扩容:2倍扩容 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // 扩容:阈值*2。(注意:阈值是有可能越界的) } //容量未初始化 && 阈值 > 0。 //【啥时会满足层判断:使用HashMap(int initialCapacity, float loadFactor)或 HashMap(int initialCapacity)构造函数实例化HashMap时,threshold才会有值。】 else if (oldThr > 0) newCap = oldThr;//初始容量设为阈值 else { //容量未初始化 && 阈值 <= 0 : //【啥时会满足这层判断:①使用无参构造函数实例化HashMap时;②在“if (oldCap > 0)”判断层newThr溢出了。】 newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) {//什么情况下才会进入这个判断框:前面执行了else if (oldThr > 0),并没有为newThr赋值,就会进入这个判断框。 float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; //------------------------------------------------------2.扩容:------------------------------------------------------------------ @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//扩容 table = newTab; //--------------------------------------------- 3.将键值对节点重新放到新的桶数组里。------------------------------------------------ ……//此处源码见下文“二、2.” return newTab; } |

|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
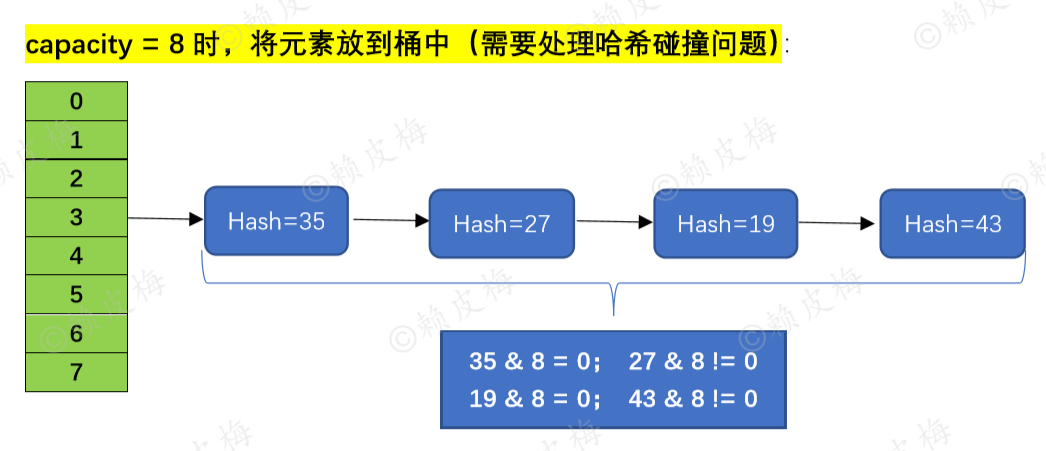
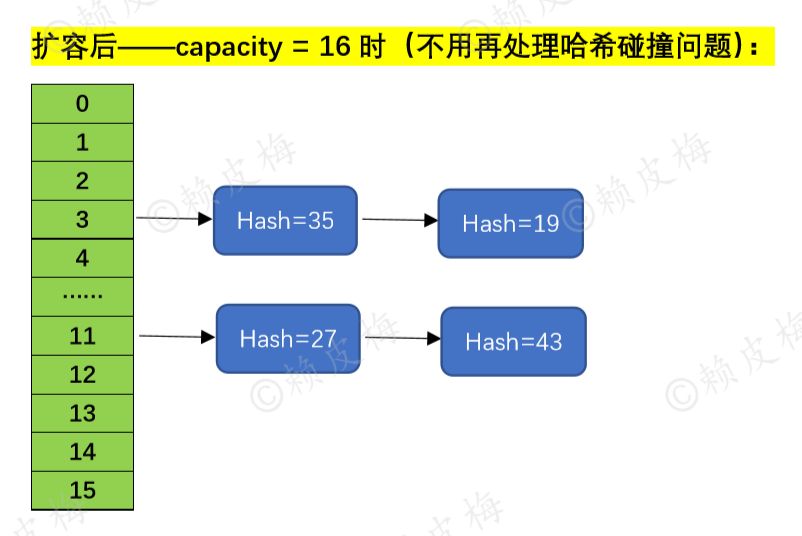
final Node<K,V>[] resize() { //扩容方法 //---------------- -------------------------- 1.计算新容量(新桶) newCap 和新阈值 newThr: ------------------------------------------- …… //此处源码见前文“一、3.” //---------------------------------------------------------2.扩容:------------------------------------------------------------------ …… //此处源码见前文“一、3.” //--------------------------------------------- 3.将键值对节点重新放到新的桶数组里:------------------------------------------------ if (oldTab != null) {//容量已经初始化过了: for (int j = 0; j < oldCap; ++j) {//一个桶一个桶去遍历,j 用于记录oldCap中当前桶的位置 Node<K,V> e; if ((e = oldTab[j]) != null) {//当前桶上有节点,就赋值给e节点 oldTab[j] = null;//把该节点置为null(现在这个桶上什么都没有了) if (e.next == null)//e节点后没有节点了:在新容器上重新计算e节点的放置位置《===== ①桶上只有一个节点 newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode)//e节点后面是红黑树:先将红黑树拆成2个子链表,再将子链表的头节点放到新容器中《===== ②桶上是红黑树 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { //遍历链表,并将链表节点按原顺序进行分组《===== ③桶上是链表 next = e.next; if ((e.hash & oldCap) == 0) {//“定位值等于0”的为一组: if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else {//“定位值不等于0”的为一组: if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); //将分好的子链表放到newCap中: if (loTail != null) { loTail.next = null; newTab[j] = loHead;//原链表在oldCap的什么位置,“定位值等于0”的子链表的头节点就放到newCap的什么位置 } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; //“定位值不等于0”的子节点的头节点在newCap的位置 = 原链表在oldCap中的位置 + oldCap } } } } } return newTab; } |


为什么jdk1.8 HashMap的容量一定要是2的n次幂的更多相关文章
- jdk1.8 HashMap底层数据结构:深入解析为什么jdk1.8 HashMap的容量一定要是2的n次幂
前言 1.本文根据jdk1.8源码来分析HashMap的容量取值问题: 2.本文有做 jdk1.8 HashMap.resize()扩容方法的源码解析:见下文“一.3.扩容:同样需要保证扩容后的容量是 ...
- HashMap的容量大小增长原理(JDK1.6/1.7/1.8)
. 前言 HashMap的容量大小会根据其存储数据的数量多少而自动扩充,即当HashMap存储数据的数量到达一个阈值(threshold)时,再往里面增加数据,便可能会扩充HashMap的容量. 可能 ...
- JDK1.8 HashMap源码分析
一.HashMap概述 在JDK1.8之前,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的节点都存储在一个链表里.但是当位于一个桶中的元素较多,即hash值相等的元素较多时 ...
- 关于HashMap初始化容量问题
使用阿里云代码规范插件扫描后出现以下提示: hashmap should set a size when initalizing,即hashmap应该在初始化时设置一个大小 在网上搜到一篇讲解(htt ...
- JDK1.8 HashMap$TreeNode.balanceInsertion 红黑树平衡插入
红黑树介绍 1.节点是红色或黑色. 2.根节点是黑色. 3.每个叶子节点都是黑色的空节点(NIL节点). 4 每个红色节点的两个子节点都是黑色.(从每个叶子到根的所有路径上不能有两个连续的红色节点) ...
- JDK1.8 HashMap$TreeNode.rotateLeft 红黑树左旋
红黑树介绍 1.节点是红色或黑色. 2.根节点是黑色. 3.每个叶子节点都是黑色的空节点(NIL节点). 4 每个红色节点的两个子节点都是黑色.(从每个叶子到根的所有路径上不能有两个连续的红色节点) ...
- java基础 - 什么是hashmap的负载因子,hashmap的容量(即桶个数)为什么是2的幂次
HashMap的负载因子是指,比如容量为16,负载因子为0.75,则当HashMap的元素个数达到16*0.75=12时,触发扩容.(16和0.75是初始默认的容量和负载因子). HashMap的容量 ...
- 为什么要指定HashMap的容量?HashMap指定容量初始化后,底层Hash数组已经被分配内存了吗?
为什么要指定HashMap的容量? 首先创建HashMap时,指定容量比如1024后,并不是HashMap的size不是1024,而是0,插入多少元素,size就是多少: 然后如果不指定HashMap ...
- HashMap初始化容量过程
集合是Java开发日常开发中经常会使用到的,而作为一种典型的K-V结构的数据结构,HashMap对于Java开发者一定不陌生.在日常开发中,我们经常会像如下方式以下创建一个HashMap: Map&l ...
随机推荐
- gitee上传下载代码命令
在想要下载的文件夹下,鼠标右键,git bash 1.输入git init 进行初始化 2.git remote add origin https://gitee.com/XXXXXXXXXXXXXX ...
- 数据处理pandas
1.缺失值时间戳不为NaN,为NaT, 同样判断都为isna()或notna()方法2.删值\去重 df.dropna() df.drop_duplicates() 3.上下值插值 df.fillna ...
- 计算机网络(3): ICMP报文
- POJ 1655 Balancing Act【树的重心模板题】
传送门:http://poj.org/problem?id=1655 题意:有T组数据,求出每组数据所构成的树的重心,输出这个树的重心的编号,并且输出重心删除后得到的最大子树的节点个数,如果个数相同, ...
- 面向对象 part3 构造函数 原型函数
6.2创建对象 方法:对象字面量 object构造函数 缺点:都是创建单个对象.同一个接口创建多个对象,会产生大量重复代码 6.2.1工厂模式 用函数封装以特定的接口创建对象 function cr ...
- webpack--删除dist目录
1.安装clean-webpack-plugin插件 npm install clean-webpack-plugin --D 2.在webpack.dev.conf.js或者webpack.conf ...
- ERP上线通用模板
一.引言 随着现代信息技术的发展与广泛应用,现代社会的快速发展和越来越追求效率的现状,对各行各业的管理的水平有了进一步的提高.XX企业作为我国的国民经济发展的基础产业,其信息化建设的水平直接关系 ...
- Xshell便捷设置实现linux复制粘贴
说明:在window系统中,Ctrl+C是复制的快捷键,Ctrl+V是粘贴的快捷键,但在xshell中,Ctrl+C 代表着中断当前指令. 解决办法如下: 1. 使用xshell中的复制粘贴快捷键复 ...
- maven tomcat 自动部署配置
1:Tomacat 配置 /tomcat-users.xml 添加如下: <role rolename="manager-gui"/> <role rolenam ...
- Java注解基础
0.背景 Java注解--Annotation产生于JDK5.作为code的特殊“标记”,注解可以在编译.类加载.运行时被读取,并执行处理. 开发利用注解在源码中嵌入补充信息,工具(代码分析.开发.部 ...