python爬虫之字体反爬
一、什么是字体反爬?
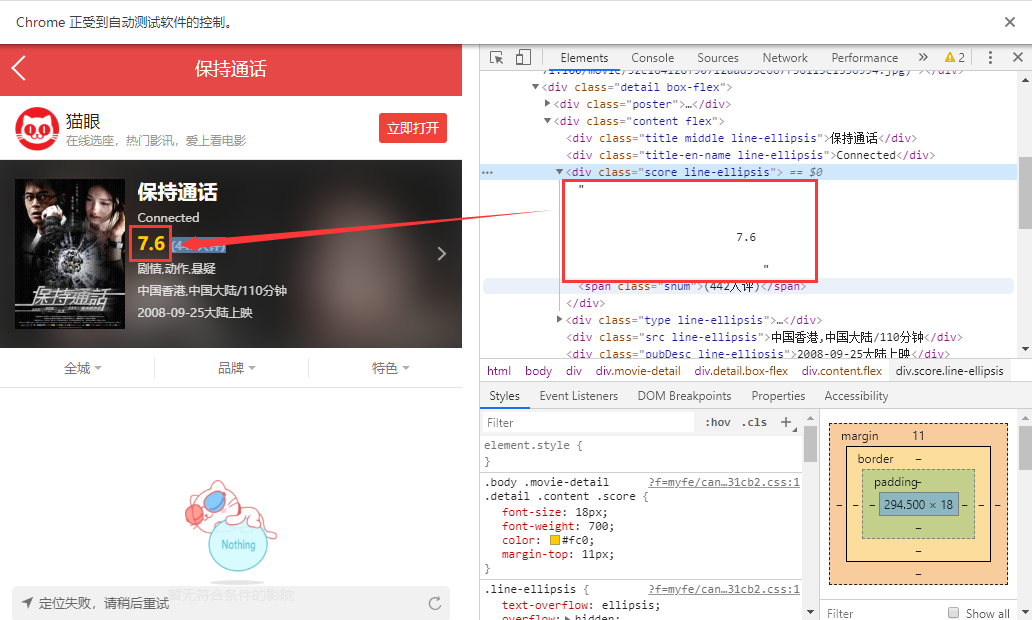
字体反爬就是将关键性数据对应于其他Unicode编码,浏览器使用该页面自带的字体文件加载关键性数据,正常显示,而当我们将数据进行复制粘贴、爬取操作时,使用的还是标准的Unicode字符映射,解析后就是干扰性数据,以猫眼电影为例:
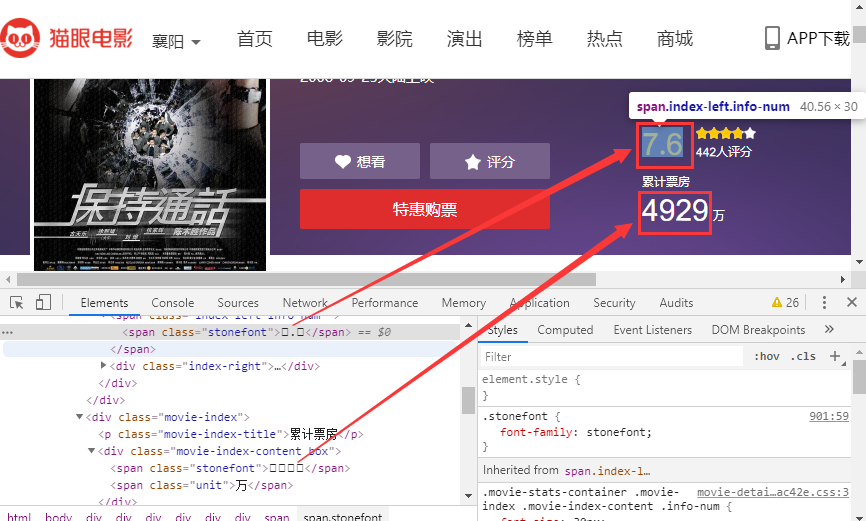
上图表明,浏览器正常渲染的数据在调试界面显示为错误的数据,即使我们复制粘贴也是这样(猜测复制粘贴的是Unicode编码)显示,这样就起到了反爬的效果。
二、解决方案
1、找到对应的字体文件

点击箭头指向的css文件
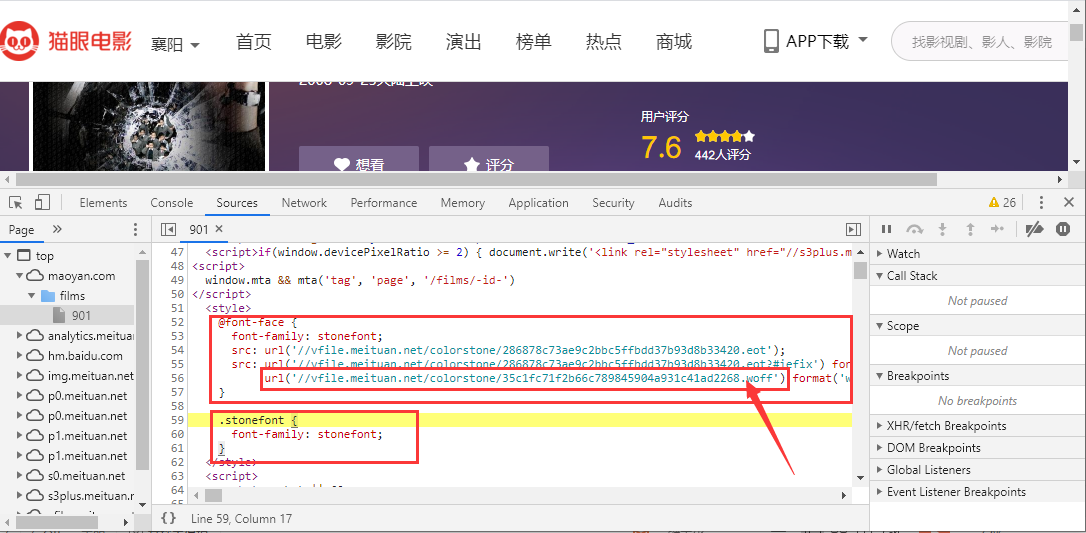
箭头指向的链接就是我们要寻找的字体文件,我们必须把这个字体文件下载下来进行分析,找到对应关系

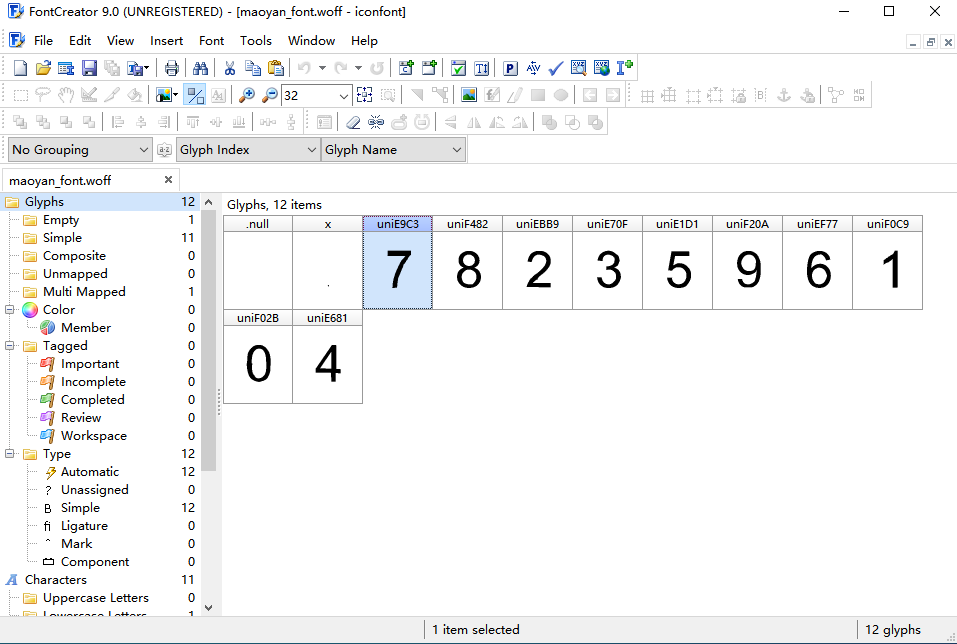

如果字体文件是固定的,我们可以手动分析,然后创建一个映射表就解决了,但是字体文件如果每请求一次就会变化,这种解决方式就不行了。
我们刷新一下链接,再下载一个字体文件对比一下,看是否变化了

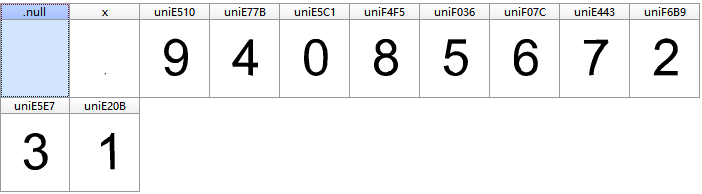
对比后,不难发现,字体文件完全不同了。
2、绕过字体反爬
目前为止,我爬过的数据从来源可以分为PC端数据、移动端Web数据和APP数据,既然PC端有字体反爬,我们可以从移动端尝试一下。
先从简单的移动端Web数据入手,可以先使用selenium,加一个手机浏览器的User-Agent,就可以在PC端浏览器显示与手机浏览器相同的效果,下图表示在移动端Web数据是没有使用字体反爬措施得。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
import time options = webdriver.ChromeOptions() options.add_argument('User-Agent="Mozilla/5.0 (Linux; U; android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"') chrome = webdriver.Chrome(r"D:\chromedriver_win32\chromedriver.exe", options=options) chrome.get("https://m.maoyan.com")
当我们分析完成后,我们就可以使用requests+lxml来编写爬虫了。
移动端APP数据也就是常说的手机APP爬虫,参照:https://www.cnblogs.com/loveprogramme/p/12209172.html
python爬虫之字体反爬的更多相关文章
- Python爬虫入门教程 64-100 反爬教科书级别的网站-汽车之家,字体反爬之二
说说这个网站 汽车之家,反爬神一般的存在,字体反爬的鼻祖网站,这个网站的开发团队,一定擅长前端吧,2019年4月19日开始写这篇博客,不保证这个代码可以存活到月底,希望后来爬虫coder,继续和汽车之 ...
- Python爬虫入门教程 63-100 Python字体反爬之一,没办法,这个必须写,反爬第3篇
背景交代 在反爬圈子的一个大类,涉及的网站其实蛮多的,目前比较常被爬虫coder欺负的网站,猫眼影视,汽车之家,大众点评,58同城,天眼查......还是蛮多的,技术高手千千万,总有五花八门的反爬技术 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫-字体反爬-猫眼国内票房榜
偶然间知道到了字体反爬这个东西, 所以决定了解一下. 目标: https://maoyan.com/board/1 问题: 类似下图中的票房数字无法获取, 直接复制粘贴的话会显示 □ 等无法识别的字 ...
- python解析字体反爬
爬取一些网站的信息时,偶尔会碰到这样一种情况:网页浏览显示是正常的,用python爬取下来是乱码,F12用开发者模式查看网页源代码也是乱码.这种一般是网站设置了字体反爬 一.58同城 用谷歌浏览器打开 ...
- python爬取实习僧招聘信息字体反爬
参考博客:http://www.cnblogs.com/eastonliu/p/9925652.html 实习僧招聘的网站采用了字体反爬,在页面上显示正常,查看源码关键信息乱码,如下图所示: 查看网页 ...
- k 近邻算法解决字体反爬手段|效果非常好
字体反爬,是一种利用 CSS 特性和浏览器渲染规则实现的反爬虫手段.其高明之处在于,就算借助(Selenium 套件.Puppeteer 和 Splash)等渲染工具也无法拿到真实的文字内容. 这种反 ...
- 网络字体反爬之pyspider爬取起点中文小说
前几天跟同事聊到最近在看什么小说,想起之前看过一篇文章说的是网络十大水文,就想把起点上的小说信息爬一下,搞点可视化数据看看.这段时间正在看爬虫框架-pyspider,觉得这种网站用框架还是很方便的,所 ...
- 58 字体反爬攻略 python3
1.下载安装包 pip install fontTools 2.下载查看工具FontCreator 百度后一路傻瓜式安装即可 3.反爬虫机制 网页上看见的 后台源代码里面的 从上面可以看出,生这个字变 ...
随机推荐
- flask学习笔记1.21
先新建一个文件夹 templates from flask import Flask #创建Flask应用程序实例 #需要传入__name__,作用是为了确定资源所在的路径 app = Flask( ...
- 【线段树】Interval GCD
题目描述 给定一个长度为N的数列A,以及M条指令 (N≤5*10^5, M<=10^5),每条指令可能是以下两种之一: "C l r d",表示把 A[l],A[l+1],- ...
- 2020 CCPC Wannafly Winter Camp Day2-K-破忒头的匿名信
题目传送门 sol:先通过AC自动机构建字典,用$dp[i]$表示长串前$i$位的最小代价,若有一个单词$s$是长串的前$i$项的后缀,那么可以用$dp[i - len(s)] + val(s)$转移 ...
- B - Sequence II (HDU 5147)
Long long ago, there is a sequence A with length n. All numbers in this sequence is no smaller than ...
- 系统学习javaweb4----CSS层叠样式表(结束)
摘要:这几天临近过年,事情有点多,学习总是段段续续的,今天总算完成了CSS的基本知识学习. 学习笔记: 西瓜学习javaweb 1.css简述. 1.1 css是什么?有什么作用? HTML----- ...
- 隐马尔可夫随机场HMM
概率知识点: 0=<P(A)<=1 P(True)=1;P(False)=0 P(A)+P(B)-P(A and B) = P(A or B) P(A|B)=P(A,B)/P(B) =&g ...
- if necessary
- list集合、txt文件对比的工具类和文件读写工具类
工作上经常会遇到处理大数据的问题,下面两个工具类,是在处理大数据时编写的:推荐的是使用map的方式处理两个list数据,如果遇到list相当大数据这个方法就起到了作用,当时处理了两个十万级的list, ...
- python3多线程应用详解(第四卷:图解多线程中LOCK)
先来看下图形对比: 发现没有这种密集型计算的任务中,多线程没有穿行的速率快,原因就是多线程在线程切换间也是要耗时的而密集型计算任务执行时几乎没以偶IO阻塞,这样你说谁快
- [LC] 520. Detect Capital
Given a word, you need to judge whether the usage of capitals in it is right or not. We define the u ...