web之robots.txt
什么是roots协议
使用原则
文件写法
安全隐患
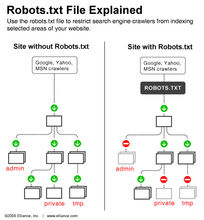
如果robots.txt文件编辑的太过详细,反而会泄露网站的敏感目录或者文件,比如网站后台路径,从而得知其使用的系统类型,从而有针对性地进行利用。
web之robots.txt的更多相关文章
- 远端WEB服务器上存在/robots.txt文件
解决方案: 1. 可直接删除(可参考:http://zh.wikipedia.org/wiki/Robots.txt) ,但不利于SEO等 2. 修改Web服务器配置 可以通过Web服务器(如Apac ...
- python web指纹获取加目录扫描加端口扫描加判断robots.txt
前言: 总结上几次的信息收集构造出来的. 0x01: 首先今行web指纹识别,然后在进行robots是否存在.后面是目录扫描 然后到使用nmap命令扫描端口.(nmap模块在windows下使用会报停 ...
- [nginx]Nginx禁止访问robots.txt防泄漏web目录
关于robots.txt文件:搜索引擎通过一种程序robot(又称spider),自动访问互联网上的网页并获取网页信 息.您可以在您的网站中创建一个纯文本文件robots.txt,在这个文件中声明该网 ...
- Robots.txt - 禁止爬虫(转)
Robots.txt - 禁止爬虫 robots.txt用于禁止网络爬虫访问网站指定目录.robots.txt的格式采用面向行的语法:空行.注释行(以#打头).规则行.规则行的格式为:Field: v ...
- Robots.txt 协议详解及使用说明
一.Robots.txt协议 Robots协议,也称为爬虫协议.机器人协议等,其全称为“网络爬虫排除标准(Robots Exclusion Protocol)”.网站通过Robots协议告诉搜索引擎哪 ...
- 通过[蜘蛛协议]Robots.txt禁止搜索引擎收录的方法
什么是robots.txt文件? 搜索引擎通过一种程序robot(又称spider),自动访问互联网上的网页并获取网页信息. 您可以在您的网站中创建一个纯文本文件robots.txt,在这个文件中 ...
- 转载robots.txt的学习
转载原地址: http://www.monring.com/seo/aspdotseo-robot.html 在国内,robots.txt文件,对于用户来说他是个可有可无的东西,也不会有人去看.但对于 ...
- robots.txt禁止搜索引擎收录
禁止搜索引擎收录的方法 一.什么是robots.txt文件? 搜索引擎通过一种程序robot(又称spider),自动访问互联网上的网页并获取网页信息. 您可以在您的网站中创建一个纯文 ...
- 如何设置让网站禁止被爬虫收录?robots.txt
robot.txt只是爬虫禁抓协议,user-agent表示禁止哪个爬虫,disallow告诉爬出那个禁止抓取的目录. 如果爬虫够友好的话,会遵守网站的robot.txt内容. 一个内部业务系统,不想 ...
随机推荐
- JS实现PC端URL跳转到对应移动端URL
在做移动端网站时,有时因技术问题或其他原因无法制作响应式版面,而移动端页面只能放到子目录下,但是手机端通过搜索引擎进入网站电脑端子页面,无法匹配到移动端页面,使得用户体验很不好,即影响排名也影响转化. ...
- 50个SQL语句(MySQL版) 问题二
--------------------------表结构-------------------------- student(StuId,StuName,StuAge,StuSex) 学生表 tea ...
- Rocket - jtag - JtagStateMachine
https://mp.weixin.qq.com/s/cFXVOBHayV2w27jpT5RglA 简单介绍JtagStateMachine的实现. 1. 简单介绍 根据IEEE 1149.1-200 ...
- Docker容器同步主机时间
方法一: 查看本地是否有/etc/localtime文件 cat /etc/localtime 如果没有就新建文件 cp /usr/share/zoneinfo/Asia/Shanghai /et ...
- 从0开始探究vue-组件化-组件之间传值
理解 Vue中有个非常重要的核心思想,就是组件化,组件化是为了代码复用 什么是组件化 组件化,就像一个电脑主机里的主板,有内存条的插口,有硬盘,光驱等等的插口,我们的项目,就像一个电脑主机,通过各种组 ...
- C# Winform 学习(五)
目标 1.MDI应用程序 2.图片框控件 3.图片集控件 4.定时器控件 一.MDI应用程序 1.理解: 单文档界面:SDI(word) 多文档界面:MDI(excel) 2.特点: 1)每个MDI程 ...
- Java实现 LeetCode 121 买卖股票的最佳时机
121. 买卖股票的最佳时机 给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格. 如果你最多只允许完成一笔交易(即买入和卖出一支股票),设计一个算法来计算你所能获取的最大利润. 注意你不 ...
- Java实现 LeetCode 12 整数转罗马数字
12. 整数转罗马数字 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M. 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例如, 罗马数字 2 ...
- java实现 洛谷 P1017 进制转换
import java.util.Scanner; public class Main { private static Scanner cin; public static void main(St ...
- syslog客户端java实现
//package com.tony.util; import java.io.*; import java.net.*; /** * UDP客户端程序,用于对服务端发送数据,并接收服务端的回应信息. ...