[原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(四) -- 安装crowd 3.1.2
[原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(四) -- 安装crowd 3.1.2
本来已经安装完毕, 并使用Jira集成的OAuth账户管理, 但是不知道什么原因, 在confluence里始终无法通过认证, 即:按照提示认证后, 页面一闪, 然后还是老样子, 但是bitbucket确好使. 好来就像换crowd来做统一身份认证.
集成的Jira Server身份认证, 其实就是账户的统一管理入口, 当你登录confluence或bitbucket的时候, 会自动将Jira Server上的账户信息同步到confluence或bitbucket上, 然后来实现伪SSO的功能. 安装时候也说明过, 这种情况只适合小于500的账户数量.
采用crowd身份认证, 则是真正的SSO的统一身份认证系统, 所有的账户信息、分组、权限设置均在crowd上, 登录jira、confluence、bitbucket时, 会请求crow来进行身份认证.
下面言归正传, 我们安装crowd, 这里依然采用了最新版crow 3.1.2的版本.
一、跟安装Jira类似, 第一步是创建crowd数据库, 使用如下命令创建:
mysql -u root -p
输入密码后, 登录mysql>命令行, 并创建数据库.
create database crowd_db default character set utf8mb4 collate utf8mb4_general_ci;
在Mysql中创建confluence用户, 并允许远程登录.
grant all privileges on crowd_db.* to 'crowd'@'%' identified by 'XXXXX' with grant option;
grant all privileges on crowd_db.* to 'crowd'@'localhost' identified by 'XXXXX' with grant option;
flush privileges;
exit;
二、安装crowd, 将crow3.1.2的安装包atlassian-crowd-3.1.2.tar.gz和破解包一并通过samba服务传到debian9.3的机器上/usr/atlassion目录下.
2.1 通过以下命令执行安装操作:
cd /usr/atlassian
tar -zxvf atlassian-crowd-3.1.2.tar.gz /usr/atlassian/crowd
以上2条命令后, 就得到解压后的crowd文件包. 为了跟jira/confluence/bitbucket保持一致, 我们将解压后的crowd安装文件夹拷贝到/opt/atlassian/crowd/目录下, 之后编辑/opt/atlassian/crowd/crowd-webapp/WEB-INF/classes目录下的crowd-init.properties文件, 添加crowd的数据文件目录. 同样为了保持目录一致性, 我们选择/var/atlassian/application-data/crowd目录作为数据目录. 即, 执行以下命令:
vi /opt/atlassian/crowd/crowd-webapp/WEB-INF/classes/crowd-ini.properties
在末尾添加:
crow.home=/var/atlassian/application-data/crowd
2.2 把破解包里面的atlassian-extras-3.2.jar和mysql-connector-java-5.1.39.jar两个文件复制到/opt/atlassian/crowd/crowd-webapp/WEB-INF/lib/目录下即可. 其中atlassian-extras-3.2.jar是破解crowd的文件, 另一个mysql-connector-java-5.1.39.jar是连接mysql的驱动包. 【注意】破解文件与jira的破解文件不一样, 虽然这两个文件名字相同, 但是不能通用, 已亲测!
如果想使用里面的非完全汉化的语言包,crowd-language-2.9.1.jar文件也复制/opt/atlassian/crowd/crowd-webapp/WEB-INF/lib/目录下, 然后备份crowd-language-3.1.2.jar包后,闪出该文件, 并把crowd-language-2.9.1.jar文件名称改成crowd-language-3.1.2.jar, 即可。
覆盖完毕后, 通过如下命令启动crowd.
/opt/atlassian/crowd/start_crowd.sh
备注, 关闭命令是 /opt/atlassian/crowd/stop_crowd.sh
2.3 Crowd启动完毕后, 在浏览器中输入地址: 192.168.X.X:8095端口, 即可访问crowd的配置界面, 具体步骤如下:
2.3.1 在首页上, 选择"设置Crowd(Set up Crowd)".
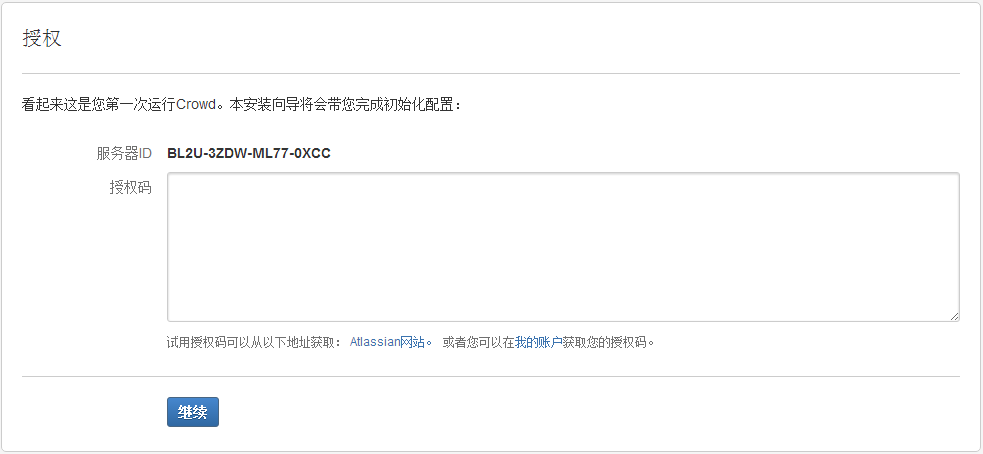
2.3.2 授权码页面, 需要到Atlanssian的官网注册30天的试用许可. 按说明操作, 随后附上图例. 只要注意, 序列号填成该页面上显示的即可.
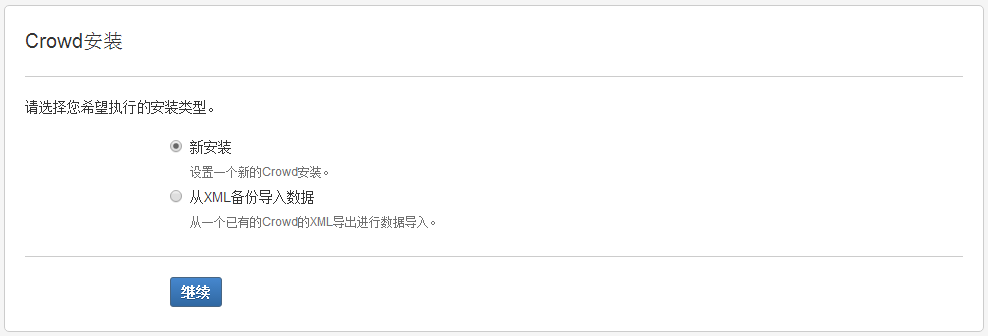
2.3.3 在Crow安装界面, 选择"新安装".
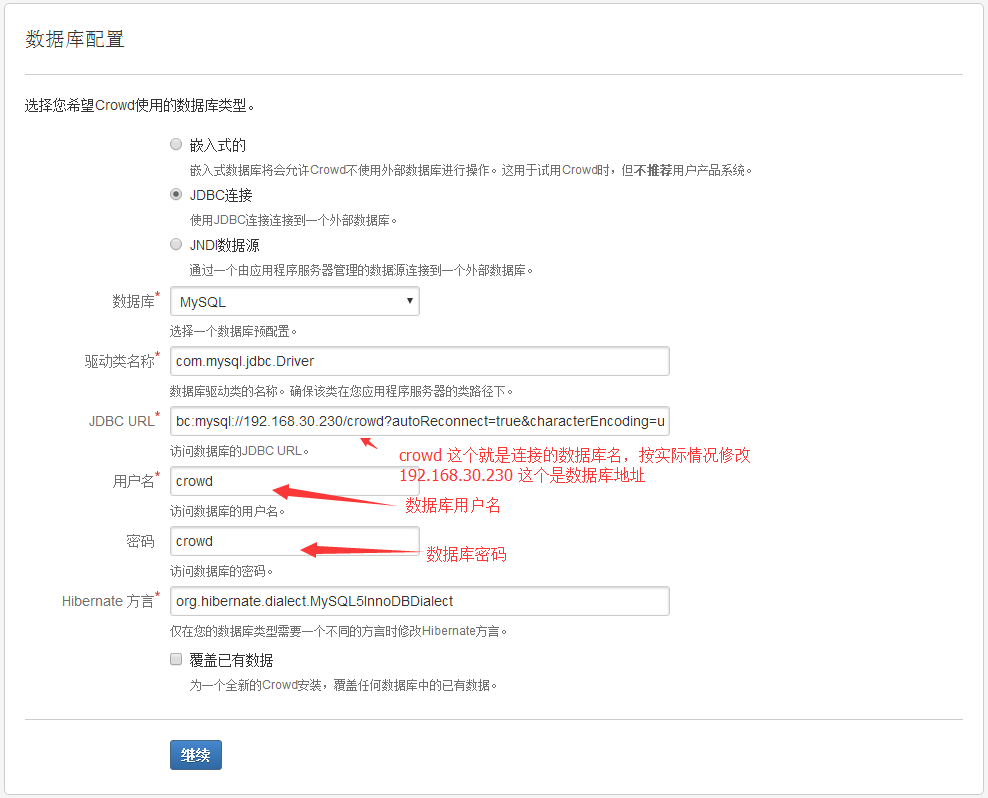
2.3.4 选择数据库设置页面, 需要选择"JDBC连接"并选择"mysql数据库", 并填上我么已经配置好的mysql数据库信息.在该页面, 会自动读取mysql connector的信息, 也就是驱动类名、Hibenate都已经选择好了, 只要修改一下JDBC URL中的连接串, 并填写用户名和密码即可.
【注意】连接串的修改,需要该IP和数据库名称,2个地方, 即:http://127.0.0.1/crowd_db?.........类似的地址, ip后面的内容是数据库名称.
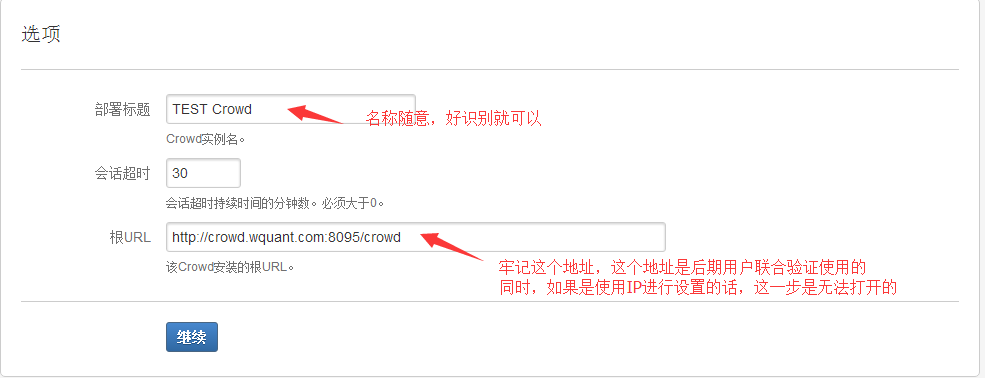
2.3.5 在漫长的等待之后, 进入选项页面, 我们填入"部署标题名(Crowd实例名)"、"crowd的根url"(请记清改url, 以后对crowd的访问都通过该地址).
2.3.6 在配置邮件页面, 直接选择稍后配置即可.
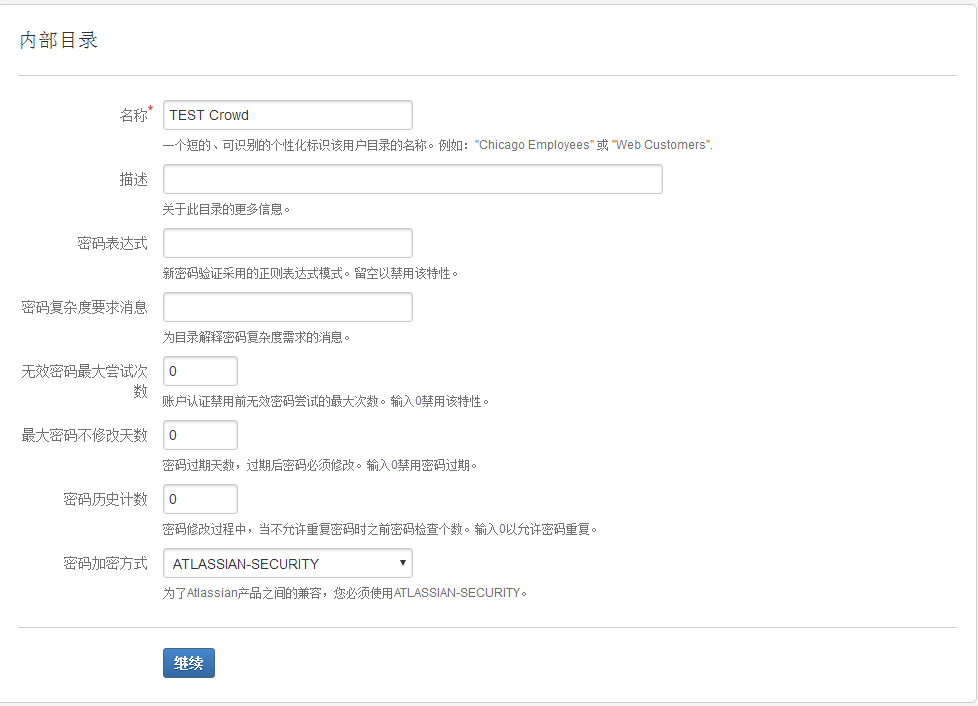
2.3.7 在内部目录页面, 主要填入"名称", 即crowd用户目录名称, 其他都是安全性要求的配置, 根据需要来选择即可.我们是内网用户, 所以直接都没选.
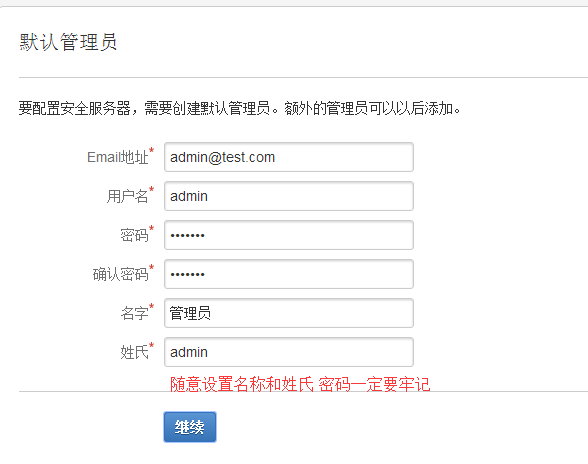
2.3.8 在配置默认管理员页面, 我们填入管理员信息, 按要求做就好. 最后两行的名字和姓氏可以任意.
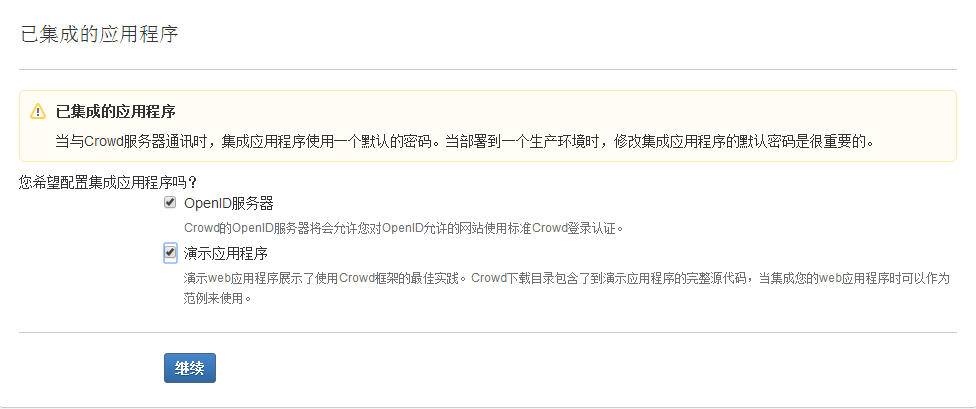
2.3.9 在已集成的应用程序页面, 勾选"OpenID服务器"并选择继续.
2.3.10 进入欢迎及登录页面, crowd的安装配置就已经完成了.
三、在Crowd上配置SSO, 这个内容是坑我时间较长的部分, 网上有写这部门内容的帖子不是版本太老、就是描述不清楚. 就迎着头皮看了好半天官方文档, 也说得是不明就里. 经过自己2天的琢磨, 终于搞定了.
网上的帖子, 好些是对照着官网指南来写的, 官网指南上描述的crowd与jira、confluence、bitbucket集成的内容, 目的应该是要把对jira、confluence、bitbucket的账号管理功能集中在crowd中, 因此需要分别针对jira、confluence、bitbucket创建不同的directory, 每个directory里面有设置了很多重复的账号, 跟SSO相差的比较远. 现有的教程, 好些也都是参照官网这个集成指南来的, 害得我搞了很久都不行, 来来回回卸载了很多遍.
3.0 这里先买个关子, 说下重装jira、confluence、bitbucket会遇到的问题. 当我们重新安装jira、confluence、bitbucket的时候, 安装文件会在系统里新增一个 XXX2-N 的账户. 什么意思呢? 就是你第一次安装的时候, 用户名和组设置为Jira(或confluence、atlbitbucket), 当你重新安装的时候, 系统不会用这个用户名, 而会采用Jira2、Jira3、Jira4这种一直往后排, 然后看我们的服务启动列表里面, 就是一连串的Jira、Jira1、Jira2.....等等. 现在我们来说如何解决这个问题, 如果是第一次安装的朋友们, 这里可以忽略.
3.0.1 修改安装目录的用户名及用户组, 即将根目录的JiraX用户名,JiraX 用户组名, 都改成Jira. 执行以下命令即可:
cd /opt/atlassian/jira
chmod -R jira:root /opt/atlassian/jira
cd /opt/atlassian/confluence
chmod -R confluence:root /opt/atlassian/confluence
cd /opt/atlassian/bitbucket
chomod -R atlbitbucket:root /opt/atlassian/bitbucket
3.0.2 修改数据目录的用户名及用户组, 执行以下命令:
cd /var/atlassian/application-data/jira
chmod -R jira:jira /var/atlassian/application-data/jira
cd /var/atlassian/application-data/confluence
chmod -R confluence:confluence /var/atlassian/application-data/confluence
cd /data/atlassian/application-data/bitbucket
chomod -R atlbitbucket:atlbitbucket /data/atlassian/application-data/bitbucket
3.0.3 修改安装目录中指定的执行用户名, 按以下命令操作:
vi /opt/atlassian/jira/bin/user.sh
将其中的JiraX改成Jira即可. 同理修改Confluence和bitbucket
vi /opt/atlassian/confluence/user.sh
vi /opt/atlassian/bitbucket/5.7.0/bin/set-bitbucket-user.sh
3.0.4 删除多余的用户名及用户组名:
vi /etc/passwd
vi /etc/passwd-
vi /etc/group
vi /etc/group-
将其中的jiraX、confluenceX、atlbitbucektX通通删除即可.
3.1 接下来, 言归正传, 咱们说说SSO的配置. 首先说下概念, 在crowd、jira、confluence、bitbucket中, 使用 "用户目录(Directory)" 来管理用户、组, 也就是说directory是承载用户和用户组的容器. 而application是用来标识jira、confluence、bitbucket的标记.
有了这两个概念, 我们就不难明白如何来做SSO. 官网的教程, 是针对jira、confluence、bitbucket三个应用, 在crowd中创建3个不同的容器(Directory), 目的是在crowd中集中管理个应用的账户, 而我们的目的是要做SSO, 即希望"同一个账户在不同的application之间流转", 因此我们只需要创建一个容器(Directory)即可. 具体操作如下:
3.1.1 登录crowd, 在页面顶部的菜单中, 点击 "目录(Directories)", 然后点击 "添加目录(Add directory)"后, 选择 "内部的(Internal)". 输入目录名称即可, 例如:XXX Crowd Directory.
3.2.2 接下来, 我们创建用户组. 点击"组(Groups)" -> "添加组(Add Group)"之后, 输入组名"jira-administrators"后, 【注意】选择我们刚才新建的目录“XXX Crowd Directory”, 确定即可。
按照刚才的步骤, 分别创建(jira-software-users、confluence-administrators、confluence-users、stash-users)几个组, 这些组都是jira、confluence、bitbucket中的用户组。
3.3.3 创建好之后, 我们开始创建用户, 点击“用户(Users)” -> "添加用户(Add User)", 创建Admin用户及其他用户.【注意】这里依然要选择我们刚才创建的容器目录“XXX Crowd Directory”。
点击"创建(create)"后, 弹出用户属性界面, 在"组(Groups)"中添加要配备的单个或多个组即可. "应用(Applications)"现在可以忽略, 下一步才会用到.
3.3.4 当我们创建好用户、用户组之后, 我们需要为jira应用程序、confluence应用程序、bitbucket应用程序设置应用标识, 即:
点击顶部"应用(Applications)" -> "添加应用(Add application)", 选择应用类型(例如:JIra)、填入标识名称(例如:Jira Crowd Server)、填入密码, 点击"下一步".
填入URL(如http://localhost:8081), 之后,点击"解析IP地址(Resolve IP Address)"后, 选择容器目录(XXX Crowd Directory)后, 点击下一步.
在选择"目录组"的时候, 我们为了保证验证效率, 手动选择需要验证的组(如:jira-administrators和jira-software-users)两个组. 当然这里选择"允许所有用户验证(Allow all users to authenticate)"也是可以的, 只是每次都是拿全部用户数据去验证.
接下来, 一路完成确认即可. 在该页面中, 也可以使用Application Test来验证用户是否能成功认证, 还可以在options中, 选择"使用小写", 来避免用户名大小写的影响. 这不不做也可以.
3.3.5 按照刚才的步骤, 在创建Confluence Crowd Server标识、bitbucket Crowd Server标识, 【注意】前者选择“confluence-administrators和confluence-users”组, 后者选择“stash-users”组即可。
3.3.6 接下来, 我们分别到Jira、confluence、bitbucket中配置用户目录.
登录jira平台, 选择"系统" -> "设置"" -> "外部用户管理"置为"打开"状态后保存. 之后点击顶部菜单的"用户管理" -> "用户目录". 在右侧选择"添加目录" -> "Atlassian 人群(Atlassian crowd)"后, 填入"任意名称"、url地址(http://localhost:8095/crowd/)、上面我们创建的Application标识(如:Jira Crowd Directory)并填入当时配置的密码测试并保存即可. 之后, 按动"用户目录列表"中的"顺序箭头", 把新增的用户目录放在最上面即可. 【说明】在用户目录列表界面, 仅保留我们刚添加的用户目录及默认的"内部类型"的用户目录即可(这里好像不需要禁用internal账户). 另外, 为加快账户同步时间, 我们可以在"创建用户目录"时, 选择"每次登陆时同步"选项.
按照同样的步骤, 操作confluence平台, 首先选择"系统" -> "用户及安全" -> " 安全配置", 在右侧页面, 启用"外部用户管理" 后保存(这里启用外部管理可能就跳转到Jira自带的用户管理服务了, 这里应该不启用). 之后选择"系统" -> "用户及安全" -> "用户目录", 按照刚才的操作添加标识为"Confluence Crowd Directory"的用户目录即可. 并且需要将Internal账户给禁用.
按照同样的步骤, 操作bitbucket平台, 选择"管理" -> "账号" -> "用户目录"后, 按照先前的操作, 添加标识为"bitbucket crowd directory"的用户目录, 并且需要将Internal账户给禁用.
至此, 关于账户配置的部分完毕.
3.3.7 接下来的最后一步, 我们需要配置"单点登录SSO"的问题.
配置Jira的单点登录, 打开crowd安装目录, 拷贝/opt/atlassian/crowd/client/conf目录下的crowd.properties文件到/opt/atlassian/jira/atlassian-jira/WEB-INF/classes目录下, 并修改文件为以下形式:
cp /opt/atlassian/crowd/client/conf/crowd.properties /opt/atlassian/jira/atlassian-jira/WEB-INF/classes/crowd.properties
vi /opt/atlassian/jira/atlassian-jira/WEB-INF/classes/crowd.properties
修改为一下形式, 其中application.name是我们设置的Jira程序的Application标识.
application.name jira-crowd-directory
application.password XXXXX
application.login.url http://localhost:8095/crowd/console/
crowd.server.url http://localhost:8095/crowd/services/
crowd.base.url http://localhost:8095/crowd/
session.isauthenticated session.isauthenticated
session.tokenkey session.tokenkey
session.validationinterval 2
session.lastvalidation session.lastvalidation
修改/opt/atlassian/jira/atlassian-jira/WEB-INF/classes目录下的seraph-config.xml, 将其中的:
<authenticator class="com.atlassian.jira.security.login.JiraSeraphAuthenticator" />
给注释掉, 并取消一下内容的注释:
<authenticator class="com.atlassian.jira.security.login.SSOSeraphAuthenticator" />
保存后, 即可完成SSO的设置, 等待冲洗启动Jira后可可以了.
3.3.8 同理, 我们配置一下confluence的SSO.
直接打开/opt/atlassian/confluence/confluence/WEB-INF/classes/crowd.properties文件, 该文件已经存在, 直接修改为以下形式:
vi /opt/atlassian/confluence/confluence/WEB-INF/classes/crowd.properties
修改为一下形式, 其中application.name是我们设置的confluence程序的Application标识.
application.name confluence-crowd-directory
application.password XXXXX
application.login.url http://localhost:8095/crowd/console/
crowd.server.url http://localhost:8095/crowd/services/
crowd.base.url http://localhost:8095/crowd/
session.isauthenticated session.isauthenticated
session.tokenkey session.tokenkey
session.validationinterval 2
session.lastvalidation session.lastvalidation
修改/opt/atlassian/confluence/confluence/WEB-INF/classes目录下的seraph-config.xml, 将其中的:
<authenticator class="com.atlassian.confluence.user.ConfluenceAuthenticator" />
给注释掉, 并取消一下内容的注释:
<authenticator class="com.atlassian.confluence.user.ConfluenceCrowdSSOAuthenticator" />
保存后, 即可完成SSO的设置, 等待冲洗启动Confluence后可可以了.
3.3.9 最后我们配置一下, bitbucket的SSO的问题.
我们编辑一下/data/atlassian/application-data/bitbucket/shared/bitbucket.properties文件, 在末尾加上一下内容即可:
plugin.auth-crowd.sso.enabled=true
至此, 所有的配置就完毕了, 重启后就可以使用了.
补充一个无关紧要的东西, Linux下VM虚拟硬盘的扩充:
1. gparted-live-0.30.0-1-amd64.iso
备份/home分区到别的硬盘后, 从最后一个分区开始删除, 只至只剩主分区.
用gparted调整分区大小后, 再创建扩展分区、linux swap分区、刚才的home分区, 然后把数据再考回来.
2. 重启登录系统后, 使用df -hl 命令查看磁盘分区情况, 发现没有swap分区.
使用 free -m 命令查看内存使用情况, 可发现swap为0
使用 fdisk -l 查看硬盘情况, 发现 swap分区名称为/dev/sda5
使用 blkid 查到/dev/sda5的UUID值.
vi /etc/fstab文件, 修改swap下面的UUID的值为刚查到的值.
使用 swapon -a 命令, 从/etc/fstab启动所有swap分区
然后保存重启即可.
照例, 贴一些别人帖子的图, 帖子地址如下: http://www.linuxidc.com/Linux/2017-02/140141p2.htm



[原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(四) -- 安装crowd 3.1.2的更多相关文章
- [原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(四) -- 安装bitbucket 5.7.0
[原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(四) -- 安装bitbucket 5.7.0 安装Bitbucket的教程, 网上能找见的不多, ...
- [原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(三) -- 安装confluence 6.6.1
[原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(三) -- 安装confluence 6.6.1 有了安装Jira的经验, 这次再安装conflue ...
- [原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(二) -- 安装jira 7.5.4
[原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(二) -- 安装jira 7.5.4 环境都配置好以后, 开始搭建Jira的环境, 这里参考了一篇文 ...
- [原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(一) -- 安装jdk(含jre)及 MySql 5.6.39
[原创] debian 9.3 搭建Jira+Confluence+Bitbucket项目管理工具(一) -- 安装jdk(含jre)及 MySql 5.6.39 回老家已经有一段时间了, 四五线 ...
- [原创] debian 9.3 搭建Jira+Confluence+Bitbucket+crowd+seafile (零) 修改端口的问题
[原创] debian 9.3 搭建Jira+Confluence+Bitbucket+seafile (零) 修改端口的问题 来来来,今天说个没有人说过的事, 搭建好Jira+Confluenc ...
- [原创] debian 9.3 搭建seafile企业私有网盘
[原创] debian 9.3 搭建seafile企业私有网盘 需求是这样的, 个人疲惫于 "成为大伙的文件中转站" ,公司不管大大小小的文件,都要打电话过来“转个xx文件”.“帮 ...
- Atlassian 系列软件安装(Crowd+JIRA+Confluence+Bitbucket+Bamboo)
公司使用的软件开发和协作工具为 Atlassian 系列软件,近期需要从腾讯云迁移到阿里云环境,简单记录下安装和配置过程.(Atlassian 的文档非常详尽,过程中碰见的问题都可以找到解决办法.) ...
- [原创]ObjectARX开发环境搭建之VS2010+ObjectARX2012Wizard+Addin工具条问题修复
目前ObjectARX版本越来越高,也越来越简化开发,如果需要同时开发低版本和高版本的ARX程序,就需要搭建批量编译环境,以满足ARX开发的需要. 批量编译的搭建网络上已经有了很多的教程,基本上都是基 ...
- JIRA+JIRA Agile敏捷项目管理工具
jira插件下载地址 http://www.confluence.cn/pages/viewpage.action?pageId=1671327 下载GreenHopper插件 安装Jira-agil ...
随机推荐
- ORACLE数据库在导入导出时序列不一致的问题
ORACLE数据库在导入导出时序列不一致的问题 在使用ORACLE数据库时,当给一个表设置自增字段时,我们经常会使用到序列+触发器来完成.但当你需要对数据库进行导入导出时,序列很容易出问题. 当你 ...
- 华硕ASUSPRO P5440UA笔记本电脑安装驱动
领了一台公司的办公笔记本,按照套路重装了系统(win10),后面发现悲剧了 采坑1: 从华硕通过型号搜索下来的无线网卡(WIFI) 驱动无法安装(双击启动没有反映) 解决:通过设备Id上google搜 ...
- 2018-2019-2 20175227张雪莹《Java程序设计》实验三 《敏捷开发与XP实践》
2018-2019-2 20175227张雪莹<Java程序设计> 实验三 <敏捷开发与XP实践> 实验报告封面 课程:Java程序设计 班级:1752班 姓名:张雪莹 学号: ...
- 廖雪峰Java8JUnit单元测试-1JUnit简介-1JUnit测试
测试驱动开发(Test Driver Development) 1.使用main()方法测试的缺点: 只能有1个main()方法,不能把测试代码分离 没有打印出测试结果和期望结果,例如expected ...
- Logic and Proofs--离散数学
Propositions: A proposition is a declarative sentence(that is, a sentence that declares a fact ) tha ...
- 利用CNN神经网络实现手写数字mnist分类
题目: 1)In the first step, apply the Convolution Neural Network method to perform the training on one ...
- Python课程第三天作业
一.统计⽂件数据中出现的的所有字符与该字符出现的个数(不区分⼤⼩写,标点与空格也算) ⽂件内容: hello friend, can you speak English! # 结果: { 'h': 1 ...
- Selenium自动化Chrome浏览器 在windows下窗口最大化
本人由于是搞自动化时间不长,所以踩了很多坑.准备把踩得这些坑记录下来. 自动化测试最基础的就是打开浏览器然后让Windows窗口最大化. 一开始百度了好多窗口最大化的方法,最常用的是: WebDriv ...
- {"error":"Content-Type header [application/x-www-form-urlencoded] is not supported","status":406}
ElasticSearch-head 查询报 406错误码 {"error":"Content-Type header [application/x-www-form-u ...
- (转)GraphicsMagick、命令行使用示例
GraphicsMagick是从 ImageMagick 5.5.2 分支出来的,但是现在他变得更稳定和优秀,GM更小更容易安装.GM更有效率.GM的手册非常丰富GraphicsMagick的命令与I ...