分库分表之后全局id怎么生成
数据库自增id:
这个就是说你的系统里每次得到一个id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个id。拿到这个id之后再往对应的分库分表里去写入。
这个方案的好处就是方便简单;缺点就是单库生成自增id,要是高并发的话,就会有瓶颈的;
适合的场景:你分库分表就俩原因,要不就是单库并发太高,要不就是单库数据量太大;除非是你并发不高,但是数据量太大导致的分库分表扩容,你可以用这个方案,因为可能每秒最高并发最多就几百,那么就走单独的一个库和表生成自增主键即可。
uuid:
好处就是本地生成,不要基于数据库来了;不好之处就是,uuid太长了,作为主键性能太差了,不适合用于主键。
适合的场景:如果你是要随机生成个什么文件名了,编号之类的,你可以用uuid,但是作为主键是不能用uuid的。
获取系统当前时间:
适合的场景:一般如果用这个方案,是将当前时间跟很多其他的业务字段拼接起来,作为一个id,如果业务上你觉得可以接受,那么也是可以的。你可以将别的业务字段值跟当前时间拼接起来,组成一个全局唯一的编号,订单编号,时间戳 + 用户id + 业务含义编码
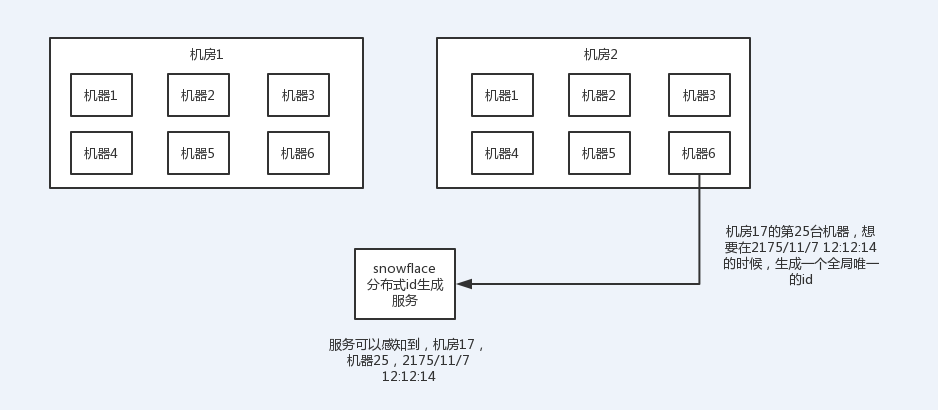
snowflake算法:
twitter开源的分布式id生成算法,就是把一个64位的long型的id,1个bit是不用的,用其中的41 bit作为毫秒数,用10 bit作为工作机器id,12 bit作为序列号
1 bit:不用,为啥呢?因为二进制里第一个bit为如果是1,那么都是负数,但是我们生成的id都是正数,所以第一个bit统一都是0
41 bit:表示的是时间戳,单位是毫秒。41 bit可以表示的数字多达2^41 - 1,也就是可以标识2 ^ 41 - 1个毫秒值,换算成年就是表示69年的时间。
10 bit:记录工作机器id,代表的是这个服务最多可以部署在2^10台机器上哪,也就是1024台机器。但是10 bit里5个bit代表机房id,5个bit代表机器id。意思就是最多代表2 ^ 5个机房(32个机房),每个机房里可以代表2 ^ 5个机器(32台机器)。
12 bit:这个是用来记录同一个毫秒内产生的不同id,12 bit可以代表的最大正整数是2 ^ 12 - 1 = 4096,也就是说可以用这个12bit代表的数字来区分同一个毫秒内的4096个不同的id
64位的long型的id,64位的long -> 二进制
0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 11001 | 0000 00000000
转自:中华石杉Java工程师面试突击
分库分表之后全局id怎么生成的更多相关文章
- 分库分表之后全局id咋生成?
1.面试题 分库分表之后,id主键如何处理? 2.面试官心里分析 其实这是分库分表之后你必然要面对的一个问题,就是id咋生成?因为要是分成多个表之后,每个表都是从1开始累加,那肯定不对啊,需要一个全局 ...
- SpringBoot 使用Sharding-JDBC进行分库分表及其分布式ID的生成
为解决关系型数据库面对海量数据由于数据量过大而导致的性能问题时,将数据进行分片是行之有效的解决方案,而将集中于单一节点的数据拆分并分别存储到多个数据库或表,称为分库分表. 分库可以有效分散高并发量,分 ...
- 分布式中的分库分表之后,ID 主键如何处理?
面试题 分库分表之后,id 主键如何处理?(唯一性,排序等) 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定 ...
- 面试官:分库分表之后,id 主键如何处理?
面试题 分库分表之后,id 主键如何处理? 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定不对啊,需要一个全 ...
- 分库分表之后,id 主键如何处理?
其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定不对啊,需要一个全局唯一的 id 来支持.所以这都是你实际生产环境中必须考虑的 ...
- 分库分表之后,id 主键如何处理
基于数据库的实现方案 数据库自增 id 这个就是说你的系统里每次得到一个 id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个 id.拿到这个 id 之后再往对应的分 ...
- 面试系列38 分库分表之后,id主键如何处理?
(1)数据库自增id 这个就是说你的系统里每次得到一个id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个id.拿到这个id之后再往对应的分库分表里去写入. 这个方案 ...
- 分库分表之后,id主键如何处理?
(1)数据库自增id 这个就是说你的系统里每次得到一个id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个id.拿到这个id之后再往对应的分库分表里去写入. 这个方案 ...
- 分库分表数据库自增 id
分库分表之后,ID 主键如何处理? 面试题 分库分表之后,id 主键如何处理? 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 ...
随机推荐
- mlock实现原理及应用【转】
转自:https://blog.csdn.net/yiyeguzhou100/article/details/78085857 https://wenku.baidu.com/view/e25b4af ...
- Hash算法【转】
转自:http://www.cnblogs.com/wangjy/archive/2011/09/08/2171638.html Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度 ...
- select2使用方法总结
官网:http://select2.github.io/ 调用 <link href="~/Content/select2.min.css" rel="styles ...
- 使用percona-xtrabackup工具对mysql数据库的备份方案
使用percona-xtrabackup工具对mysql数据库的备份方案 需要备份mysql的主机 172.16.155.23存放备份mysql的主机 172.16.155.22 目的:将155.23 ...
- Redis持久化存储(AOF与RDB两种模式)
Redis中数据存储模式有2种:cache-only,persistence; cache-only即只做为“缓存”服务,不持久数据,数据在服务终止后将消失,此模式下也将不存在“数据恢复”的手段,是一 ...
- mgo 的 session 与连接池
简介 mgo是由Golang编写的开源mongodb驱动.由于mongodb官方并没有开发Golang驱动,因此这款驱动被广泛使用.mongodb官网也推荐了这款开源驱动,并且作者在github也表示 ...
- GIT入门文档
集中式(SVN): 集中式版本控制系统,版本库是集中存放在中央服务器的,用的都是自己的电脑,所以要先从中央服务器取得最新的版本,然后开始干活,干完活了,再把自己的活推送给中央服务器. 集中式版本控制系 ...
- signal & slot
The Qt signals/slots and property system are based on the ability to introspect the objects at runti ...
- use Swig to create C/C++ extension for Python
SWIG is a software development tool that simplifies the task of interfacing different languages to C ...
- Tomcat服务的安装及配置
在进行Java Web开发时必须有Web服务器的支持,常用的Web服务器便是Tomcat,本文主要介绍Tomcat的安装和配置.客户端通过Web浏览器发送一个基于HTTP协议的请求到服务器上后,服务器 ...