分库分表之后全局id怎么生成
数据库自增id:
这个就是说你的系统里每次得到一个id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个id。拿到这个id之后再往对应的分库分表里去写入。
这个方案的好处就是方便简单;缺点就是单库生成自增id,要是高并发的话,就会有瓶颈的;
适合的场景:你分库分表就俩原因,要不就是单库并发太高,要不就是单库数据量太大;除非是你并发不高,但是数据量太大导致的分库分表扩容,你可以用这个方案,因为可能每秒最高并发最多就几百,那么就走单独的一个库和表生成自增主键即可。
uuid:
好处就是本地生成,不要基于数据库来了;不好之处就是,uuid太长了,作为主键性能太差了,不适合用于主键。
适合的场景:如果你是要随机生成个什么文件名了,编号之类的,你可以用uuid,但是作为主键是不能用uuid的。
获取系统当前时间:
适合的场景:一般如果用这个方案,是将当前时间跟很多其他的业务字段拼接起来,作为一个id,如果业务上你觉得可以接受,那么也是可以的。你可以将别的业务字段值跟当前时间拼接起来,组成一个全局唯一的编号,订单编号,时间戳 + 用户id + 业务含义编码
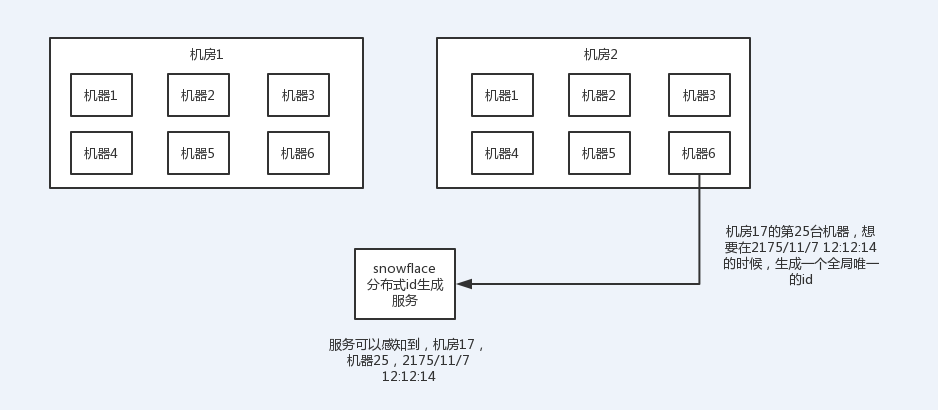
snowflake算法:
twitter开源的分布式id生成算法,就是把一个64位的long型的id,1个bit是不用的,用其中的41 bit作为毫秒数,用10 bit作为工作机器id,12 bit作为序列号
1 bit:不用,为啥呢?因为二进制里第一个bit为如果是1,那么都是负数,但是我们生成的id都是正数,所以第一个bit统一都是0
41 bit:表示的是时间戳,单位是毫秒。41 bit可以表示的数字多达2^41 - 1,也就是可以标识2 ^ 41 - 1个毫秒值,换算成年就是表示69年的时间。
10 bit:记录工作机器id,代表的是这个服务最多可以部署在2^10台机器上哪,也就是1024台机器。但是10 bit里5个bit代表机房id,5个bit代表机器id。意思就是最多代表2 ^ 5个机房(32个机房),每个机房里可以代表2 ^ 5个机器(32台机器)。
12 bit:这个是用来记录同一个毫秒内产生的不同id,12 bit可以代表的最大正整数是2 ^ 12 - 1 = 4096,也就是说可以用这个12bit代表的数字来区分同一个毫秒内的4096个不同的id
64位的long型的id,64位的long -> 二进制
0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 11001 | 0000 00000000
转自:中华石杉Java工程师面试突击
分库分表之后全局id怎么生成的更多相关文章
- 分库分表之后全局id咋生成?
1.面试题 分库分表之后,id主键如何处理? 2.面试官心里分析 其实这是分库分表之后你必然要面对的一个问题,就是id咋生成?因为要是分成多个表之后,每个表都是从1开始累加,那肯定不对啊,需要一个全局 ...
- SpringBoot 使用Sharding-JDBC进行分库分表及其分布式ID的生成
为解决关系型数据库面对海量数据由于数据量过大而导致的性能问题时,将数据进行分片是行之有效的解决方案,而将集中于单一节点的数据拆分并分别存储到多个数据库或表,称为分库分表. 分库可以有效分散高并发量,分 ...
- 分布式中的分库分表之后,ID 主键如何处理?
面试题 分库分表之后,id 主键如何处理?(唯一性,排序等) 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定 ...
- 面试官:分库分表之后,id 主键如何处理?
面试题 分库分表之后,id 主键如何处理? 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定不对啊,需要一个全 ...
- 分库分表之后,id 主键如何处理?
其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定不对啊,需要一个全局唯一的 id 来支持.所以这都是你实际生产环境中必须考虑的 ...
- 分库分表之后,id 主键如何处理
基于数据库的实现方案 数据库自增 id 这个就是说你的系统里每次得到一个 id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个 id.拿到这个 id 之后再往对应的分 ...
- 面试系列38 分库分表之后,id主键如何处理?
(1)数据库自增id 这个就是说你的系统里每次得到一个id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个id.拿到这个id之后再往对应的分库分表里去写入. 这个方案 ...
- 分库分表之后,id主键如何处理?
(1)数据库自增id 这个就是说你的系统里每次得到一个id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个id.拿到这个id之后再往对应的分库分表里去写入. 这个方案 ...
- 分库分表数据库自增 id
分库分表之后,ID 主键如何处理? 面试题 分库分表之后,id 主键如何处理? 面试官心理分析 其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 ...
随机推荐
- 1.Python_字符串_常用办法总结
明确:对字符串的操作方法都不会改变原来字符串的值. 1.去掉空格和特殊符号 name.strip() 去掉空格和换行符 name.strip("xx") 去掉某个字符串 name. ...
- 【ARTS】01_14_左耳听风-20190211~20190217
ARTS: Algrothm: leetcode算法题目 Review: 阅读并且点评一篇英文技术文章 Tip/Techni: 学习一个技术技巧 Share: 分享一篇有观点和思考的技术文章 Algo ...
- dubbo源码分析6——SPI机制中的AOP
在 ExtensionLoader 类的loadFile方法中有下图的这段代码: 类如现在这个ExtensionLoader中的type 是Protocol.class,也就是SPI接口的实现类中Xx ...
- MySQL中binlog参数:binlog_rows_query_log_events-记录具体的SQL【转】
在使用RBR也就是行格式的时候,去解析binlog,需要逆向才能分析出对应的原始SQL是什么,而且,里面对应的是每一条具体行变更的内容.当然,你可以开启general log,但如果我们需要的只是记录 ...
- 初识python异步模块Trio
Trio翻译过来是三重奏的意思,它提供了更方便异步编程,是asyncio的更高级的封装. 它试图简化复杂的asyncio模块.使用起来比asyncio和Twisted要简单的同时,拥有其同样强大功能. ...
- vue后台项目记录
1.当我们用axios进行接口访问时,必须同时使用Qs,否则后端接收不到所传的数据! npm 安装qs,然后引用 import Qs from 'qs' // 创建axios实例 const serv ...
- MFCWinInet学习
http://blog.csdn.net/segen_jaa/article/details/6278167 背景: 功能:服务端下载文件 服务端:用Java写Sevlet进行有效性验证 客户端:用C ...
- Linux将公网ip映射到局域网ip
测试环境如下: monitor: msc1:公网IP:103.6.164.128 eth0 内网IP:192.168.0.57 eth0内网IP:192.168.0.16 eth1 通过访问monit ...
- hibernate框架学习之一级缓存
l缓存是存储数据的临时空间,减少从数据库中查询数据的次数 lHibernate中提供有两种缓存机制 •一级缓存(Hibernate自身携带) •二级缓存(使用外部技术) lHibernate的一级缓存 ...
- 【原创】大数据基础之Logstash(3)应用之file解析(grok/ruby/kv)
从nginx日志中进行url解析 /v1/test?param2=v2¶m3=v3&time=2019-03-18%2017%3A34%3A14->{'param1':' ...