hbase-数据恢复流程
引用《https://blog.csdn.net/nigeaoaojiao/article/details/54909921》
hlog介绍:

hlog构建:

从图中可以看出,对于一个hlog日志,整一个region server中的region数据都写入到同一个日志中,日志中最小单元的格式为<HLogKey,WALEdit>
hlogKey格式:
- sequenceid,自增id
- write time,写入时间,修改操作何时写入日志的时间戳
- cluster ids,集群id,满足用户多集群之间复制的需求
- region 信息
- table name,表名
hlog滚动:
region server每个一段时间就会生成一个log文件(默认1小时,可以设置),设置日志滚动机制,类似于binlog的处理机制。虽然会产生会多文件,但是考虑到删除文件时,直接将文件删除是最方便的方式。
hlog失效:
当一个日志文件的数据全部从MemStore中flush到了HFile中,该日志文件即可以被删除掉了。可以通过自增id——sequenceid判断,当一个文件中的sequenceid小于Memstore中flush记录的最大的sequenceid即可判断。当一个log被判定为失效后,会被移到oldWALs目录下
hlog删除:
hmaster后台启动一个线程每个一段时间(默认一分钟)检查文件夹OldWALs,判断下面的log是否真正的失效,确认失效即删除。
hbase日志恢复流程:
regionServer是否存活:
hbase中,master检查regionServer是否存活是通过zookeeper实现的,regionServer通过向zookeeper注册节点(/hbase/rs目录下),并且定时向zookeeper上报心跳来证明自己处于存活状态。master通过查看该目录的节点查看regionServer是否存活。
region server出问题的情况:
- regionServer出现长时间的full gc
- regionServer宕机
- zookeeper出问题
- 网络问题
- 等等

在master看来,就是在zookeeper中查看不到具体的region Server注册的节点,这时候就会进行数据恢复。
hbase的日志恢复有三种方式:
- logSplitting
- Distributed log splitting
- Distributed log replay
logSplitting:
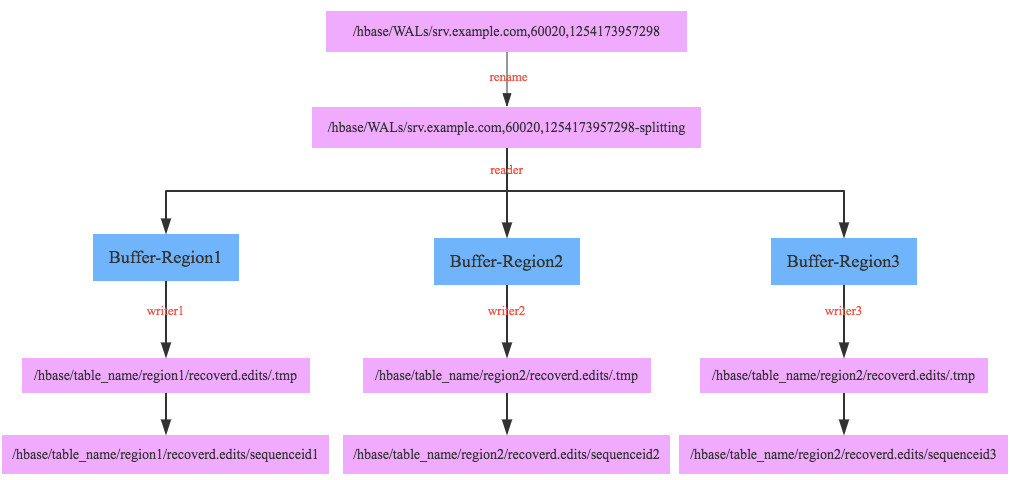
hbase的日志分割方式,整个过程都由HMaster执行。
- 首先将日志复制一份,重命名后缀加-splitting。
- 启动一个线程依次读取log,根据hlogkey中不同的region,写入到不同的buffer中。知道全部的log读完
- 对应每个buffer启动一个线程,将每个buffer的数据写入到hdfs中
- 之后,等hmaster分配完region后,将hdfs中数据写入到对应的region中
因为是单线程恢复,在出现大量的机器宕机后,需要恢复的数据过大,耗时会变得非常长。
Distributed log splitting:
DLS是LS的分布式实现,借助了master和多个regionserver的计算能力,将hlog的splitting任务分散到不同的regionserver上。

- hmaster分别将每个log(该日志在hdfs上的路径)作为一个任务发布到zookeeper上(/hbase/splitWAL节点下),设置起始状态为TASK_UNASSIGNED。
- 所有存活的regionserver都注册这个节点上等待任务,一旦hmaster发布任务,全部regionserver开始竞争任务,即全部regionserver尝试修改任务状态为TASK_OWNED,修改成功即竞争成功。
- regionserver抢占任务成功后,分配任务给相应的线程处理。处理成功修改状态为TASK_DONE,失败修改状态为TASK_ERR。
- hmaster一直监听者该节点,一旦有状态修改就会收到通知,如果任务成功,则删除对应任务节点,如果任务失败,则从新发布任务。
- 具体regionserver处理一个任务的流程和LS处理流程一样
DLS有一个问题,生成的小文件过多,对于M个region,N个hlog日志最终会生成M*N个文件。
Distributed log replay:
DLR方式相对于DLS方式来说,流程上做了一些改动:
- DLR先分配region,在切分回放HLog,region重新分配后状态被设置为recovering,该状态只能写不能读取。而在HLog splitting分配到buffer后,不写文件,而是直接执行回放操作。
hbase-数据恢复流程的更多相关文章
- hbase读写流程
一. Hbase读流程 META表记录着表的原信息,根据rowkey查询META表,获取所在region信息 客户端去相应的regionServer查询数据,先查询memStore(memstore是 ...
- HBase Scan流程分析
HBase Scan流程分析 HBase的读流程目前看来比较复杂,主要由于: HBase的表数据分为多个层次,HRegion->HStore->[HFile,HFile,...,MemSt ...
- 8.hbase写入流程和读取流程
1 hbase写入流程 hbase中无论是新增数据还是修改已有行,其内部流程都是一样的,hbase执行写入时会写到两个地方,write-ahead log 简称wal 也叫hlog 预写式日志 和 M ...
- Mysql 数据恢复流程 基于binlog redolog undolog
注:文中有个易混淆的地方 sql事务,即每次数据库操作生成的事务,这个事务trx_id只在undolog里存储,同时undolog维护了此事务是否完成的状态. 日志持久化事务,为了保证redolog和 ...
- hbase读写流程分析
前言 最近被大佬问到一个问题,hbase查询数据在最坏的场景下需要进行几次rpc,当时就懵了..下面主要对client端代码进行分析.阅读文章和看源码更配~ 读数据 流程总览 1. 从zookeepe ...
- oracle 执行 delete user$ 误删所有用户信息后的数据恢复流程
起因: 在oracle测试过程中,不小心执行了delete user$ 命令,导致oracle当前实例所有的用户信息丢失,包括sys用户. 第一次使用DUL工具数据恢复:失败 下载ParnassusD ...
- Hbase读写流程和寻址机制
写操作流程 (1) Client通过Zookeeper的调度,向RegionServer发出写数据请求,在Region中写数据. (2) 数据被写入Region的MemStore,直到MemStore ...
- Hbase获取流程
1\\.客户端chou操作 2.服务器dauncaozuo操作 3\存储优化
- Hbase存储流程
- HBase 数据恢复
参考链接: https://community.hortonworks.com/content/supportkb/48748/hbase-master-wont-start-with-followi ...
随机推荐
- 合并hive/hdfs小文件
磁盘: heads/sectors/cylinders,分别就是磁头/扇区/柱面,每个扇区512byte(现在新的硬盘每个扇区有4K) 文件系统: 文件系统不是一个扇区一个扇区的来读数据,太慢了,所以 ...
- Java ---- 链表逆序
public class LinkedListRevert { public static void main(String[] args) { Node next3 = new Node(4,nul ...
- leetcode每日刷题计划-简单篇day9
Num 38 报数 Count and Say 题意读起来比较费劲..看懂了题还是不难的 注意最后的长度是sz的长度,开始写错写的len 在下次计算的时候len要更新下 说明 直接让char和int进 ...
- 71.纯 CSS 创作一个跳 8 字型舞的 loader
原文地址:https://segmentfault.com/a/1190000015534639#articleHeader0 感想:rotateX() 和rotateZ()一起使用好懵呀. HTML ...
- Linux 工作目录切换命令
1.pwd 显示当前用户所处的目录 2.cd 切换工作路径 cd [目录名称],cd - 返回上次所处的目录 cd ~ 返回当前用户的根目录 cd.. 返回上级目录 3.ls 显示目录中的文件信息,l ...
- css实现布局
1.两栏布局 两栏布局一般就是一栏定宽一栏自适应(也就是流动).分的细的话还有左栏定宽右栏自适应.右栏定宽左栏自适应. 举个栗子:一栏定宽200px,一栏自适应. <head> <m ...
- leetcode top 100 题目汇总
首先表达我对leetcode网站的感谢,与高校的OJ系统相比,leetcode上面的题目更贴近工作的需要,而且支持的语言广泛.对于一些比较困难的题目,可以从讨论区中学习别人的思路,这一点很方便. 经过 ...
- Java mysql
- neo4j性能调优(转)
最近在公司实习做的就是优化neo4j图形数据库查询效率的事,公司提供的是一个在Linux上搭建且拥有几亿个节点的数据库.开始一段时间主要是熟悉该数据库的一些基本操作,直到上周才正式开始步入了优化数据库 ...
- Unity 读写文本 文件
1. LitJson的使用 https://blog.csdn.net/qq_35669619/article/details/78928966 https://blog.csdn.net/qq_14 ...