用pandas库修改excel文件里的内容,并把excel文件格式存为csv格式,再将csv格式改为html格式
假设有Excel文件data.xlsx,其中内容为:
ID age height sex weight
张三 1 39 181 female 85
李四 2 40 180 male 80
王五 3 38 178 female 78
赵六 4 59 170 male 66
现在需要将这个Excel文件中的数据读入pandas,并且在后续的处理中不关心ID列,还需要把sex列的female替换为1,把sex列的male替换为0。本文演示有关的几个操作。
(1)导入pandas模块
>>> import pandas as pd
(2)把Excel文件中的数据读入pandas
df = pd.read_excel('data.xlsx')
df
执行效果:
ID age height sex weight
张三 1 39 181 female 85
李四 2 40 180 male 80
王五 3 38 178 female 78
赵六 4 59 170 male 66
(3)删除ID列
可以得到新的DataFrame:
>>> df.drop('ID', axis=1)
age height sex weight
张三 39 181 female 85
李四 40 180 male 80
王五 38 178 female 78
赵六 59 170 male 66
也可以直接在原DataFrame上原地删除:
df.drop('ID', axis=1, inplace=True)
df
age height sex weight
张三 39 181 female 85
李四 40 180 male 80
王五 38 178 female 78
赵六 59 170 male 66
(4)替换sex列
方法一:使用replace()方法替换sex列,得到新的DataFrame,如果指定参数inplace=True,则可以原地替换。
>>> df.replace({'female':1, 'male':0})
age height sex weight
df.replace({'female':1, 'male':0})
age height sex weight
张三 39 181 1 85
李四 40 180 0 80
王五 38 178 1 78
赵六 59 170 0 66
方法二:使用map()方法+lambda表达式,原地替换。
df1 = df[:]
df1['sex'] = df1['sex'].map(lambda x:1 if x=='female' else 0)
df1
age height sex weight
张三 39 181 1 85
李四 40 180 0 80
王五 38 178 1 78
赵六 59 170 0 66
方法三:使用map()方法+字典,原地替换。
df1 = df[:]
df1['sex'] = df1['sex'].map({'female':1, 'male':0})
df1
age height sex weight
张三 39 181 1 85
李四 40 180 0 80
王五 38 178 1 78
赵六 59 170 0 66
方法四:使用loc类,原地替换。
>>>
df1 = df[:]
>>> df1.loc[df['sex']=='female', 'sex'] = 1
>>> df1.loc[df['sex']=='male', 'sex'] = 0
>>> df1
age height sex weight
张三 39 181 1 85
李四 40 180 0 80
王五 38 178 1 78
赵六 59 170 0 66
二、运用上述功能进行实战
1、先读取一个excel文件:
代码如下:
df = pd.read_excel('file:///D:/文档/Python成绩.xlsx', index_col=None, na_values=['NA']) # 读取excel文件中的数据
如果想知道文件是否读取成功可以用print函数将数据输出
如:
print(df)
然后会显示文件的数据,效果如下:

2、修改excel文件内容:
运用上述的 方法三:使用map()方法+字典,原地替换。
现在要将优秀改为90,良好改为80,及格改为60
代码如下:
df1=df[:]
df1['第二次']=df1['第二次'].map({'优秀':90,'良好':80,'及格':60})
df1['第三次:圆周率']=df1['第三次:圆周率'].map({'优秀':90,'良好':80,'及格':60})
df1['第四次:汉诺塔']=df1['第四次:汉诺塔'].map({'优秀':90,'良好':80,'及格':60})
df1['第五次:jieba库']=df1['第五次:jieba库'].map({'优秀':90,'良好':80,'及格':60})
df1['第六次:图片处理']=df1['第六次:图片处理'].map({'优秀':90,'良好':80,'及格':60})
效果如下:
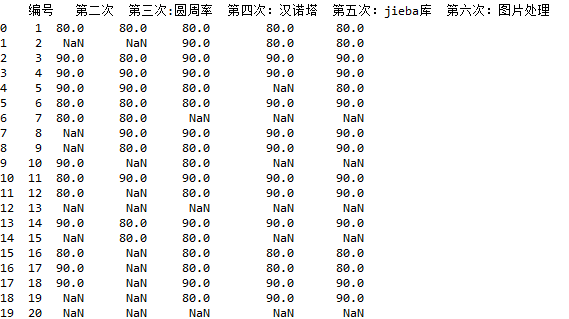
三、再将上述的NaN改为0
只需要用数据清洗之缺失数据填充fillna()就可以完成
运行代码如下:
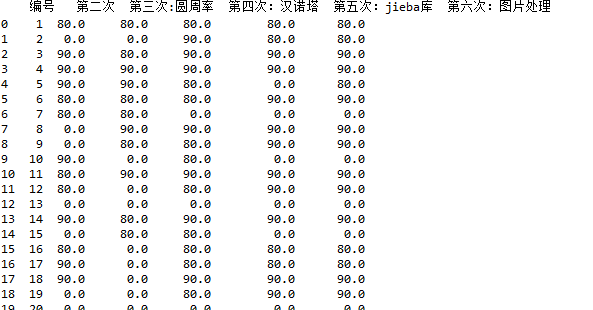
df1=df1.fillna(0)
print(df1)
效果如下:
四、最后将excel文件保存为csv文件
代码如下:
df1.to_csv('D:/文档\\thon.csv')
最后会在你保存的文件你多了一个csv文件。
五、同时可以将csv文件保存为html格式
方法一(用工具实现):
代码如下:
df1.to_html('d:\\st.html')
同样会在你保存的文件夹中会多出一个html格式的文件
方法二:
代码如下:
seg1 = '''
<!DOCTYPE HTML>\n<html>\n<body>\n<meta charset=gb2312>
<h2 align=center>2016年7月部分大中城市新建住宅价格指数</h2>
<table border='1' align="center" width=70%>
<tr bgcolor='orange'>\n'''
seg2 = "</tr>\n"
seg3 = "</table>\n</body>\n</html>"
def fill_data(locls):
seg = '<tr><td align="center">{}</td><td align="center">{}</td><td align="center">{}</td><td align="center">{}</td></tr>\n'.format(*locls)
return seg
fr = open("D:\\文档\Python123.csv", "r",encoding="utf-8-sig")
ls = []
for line in fr:
line = line.replace("\n","")
ls.append(line.split(","))
fr.close()
fw = open("D:\\文档\Python5.html", "w")
fw.write(seg1)
fw.write('<th width="25%">{}</th>\n<th width="25%">{}</th>\n<th width="25%">{}</th>\n<th width="25%">{}</th>\n'.format(*ls[0]))
fw.write(seg2)
for i in range(len(ls)-1):
fw.write(fill_data(ls[i+1]))
fw.write(seg3)
fw.close()
用pandas库修改excel文件里的内容,并把excel文件格式存为csv格式,再将csv格式改为html格式的更多相关文章
- Python Pyinstaller打包含pandas库的py文件遇到的坑
今天的主角依然是pyinstaller打包工具,为了让pyinstaller打包后exe文件不至过大,我们的py脚本文件引用库时尽可能只引用需要的部分,不要引用整个库,多使用“from *** imp ...
- java代码将excel文件中的内容列表转换成JS文件输出
思路分析 我们想要把excel文件中的内容转为其他形式的文件输出,肯定需要分两步走: 1.把excel文件中的内容读出来: 2.将内容写到新的文件中. 举例 一张excel表中有一个表格: 我们需要将 ...
- C# 读取Excel文件里面的内容到DataSet
摘要:读取Excel文件里面的内容到DataSet 代码: /// <summary> /// 读取Excel文件里面的内容到DataSet /// </summary> // ...
- C#创建Excel文件并将数据导出到Excel文件
工具原料: Windows 7,Visual Studio 2010, Microsoft Office 2007 创建解决方案 菜单>新建>项目>Windows窗体应用程序: 添加 ...
- Flex读取txt文件里的内容(二)
Flex读取txt文件里的内容 自己主动生成的文件 LoadTxt-app.xml: <?xml version="1.0" encoding="utf-8&quo ...
- Flex读取txt文件里的内容(一)
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/you23hai45/article/details/25248307 Flex读取txt文件里的内 ...
- 从Excel文件中读取内容
从Excel文件中读取内容 global::System.Web.HttpPostedFileBase file = Request.Files["txtFile"]; strin ...
- Flex读取txt文件里的内容报错
Flex读取txt文件里的内容 1.详细错误例如以下 2.错误原因 读取文件不存在 var file:File = new File(File.applicationDirectory.nativeP ...
- 根据Excel文件中的内容,修改指定文件夹下的文件名称
问题:根据Excel文件中内容,把文件名称由第2列,改为第1列.比如:把文件“123.jpg”修改为“1.jpg”.
随机推荐
- Sql Server数据库之触发器
阅读目录 一:触发器的优点 二:触发器的作用 三:触发器的分类 四:触发器的工作原理 五:创建触发器 六:管理触发器 概念: 触发器(trigger)是SQL server 提供给程序员和数据分析 ...
- c# linq 汇总
例子:List<string> list = new List<string>(); list.Add("1 a");list.Add("2 b& ...
- Day08 - Ruby比一比:String的+=与concat串接
前情提要: 在第七天我们透过比较Symbol和String,发现字串比符号多了更多方法!为了活用string method,今天我们接续前文,来探讨一题跟字串有关的题目: Ruby经典面试题目#08( ...
- 史上最全最详细的环境搭建教程,行百里者手把手教你在windows下搭建Anaconda+pycharm+库文件(TensorFlow,numpy)环境搭建
我是在搭建TensorFlow开发环境的道路上走了很多弯路 掉了很多头发,为了让广大同学们不在受苦受累 下面我将手把手教你学习如特快速搭建python环境 快速导入numpy,PIL,pillow,等 ...
- jQuery-UI的使用
使用效果图: 源码: <!DOCTYPE html><html lang="en"><head> <meta charset=" ...
- iframe刷新
<div title="基本信息" style="padding:2px; "> <iframe id="newsrc& ...
- 解决React Native:Error: Cannot find module 'asap/raw'
本来想做个底部切换的tab的,安装完 npm i react-native-tab-navigator --save 后跑项目就报错了,如下图 和我一样报这个错的朋友们莫慌,一步就可以解决了,执行命令 ...
- Linux-02
Linux命令 命令格式:命令 [-选项] [参数] 例如: ls -la /etc 说明:1)个别命令使用不遵循此格式 2)当有多个选项时,可以写在一起 3)简化选项与完整选项-a等于--all
- win7系统标准用户恢复administrator账号方法
一次误操作,把管理员账号给禁用了,满眼的泪花~~~~~~~~~ 标准用户,什么都干不了,怎么办呢????? 度娘一下,各种奇葩答案,就是解决不了 呵呵,最后找到了解决方法: 1.开机后BIOS过后,按 ...
- C#窗体-猜数字
1.用到的控件:groupbox.label.textbox.button.menustrip等 2.实现的功能,随机产生一个数字,输入自己猜的答案,判断是否猜对. 3.运行结果 4.代码 using ...