day8数据类型补充,集合,深浅拷贝
思维导图:
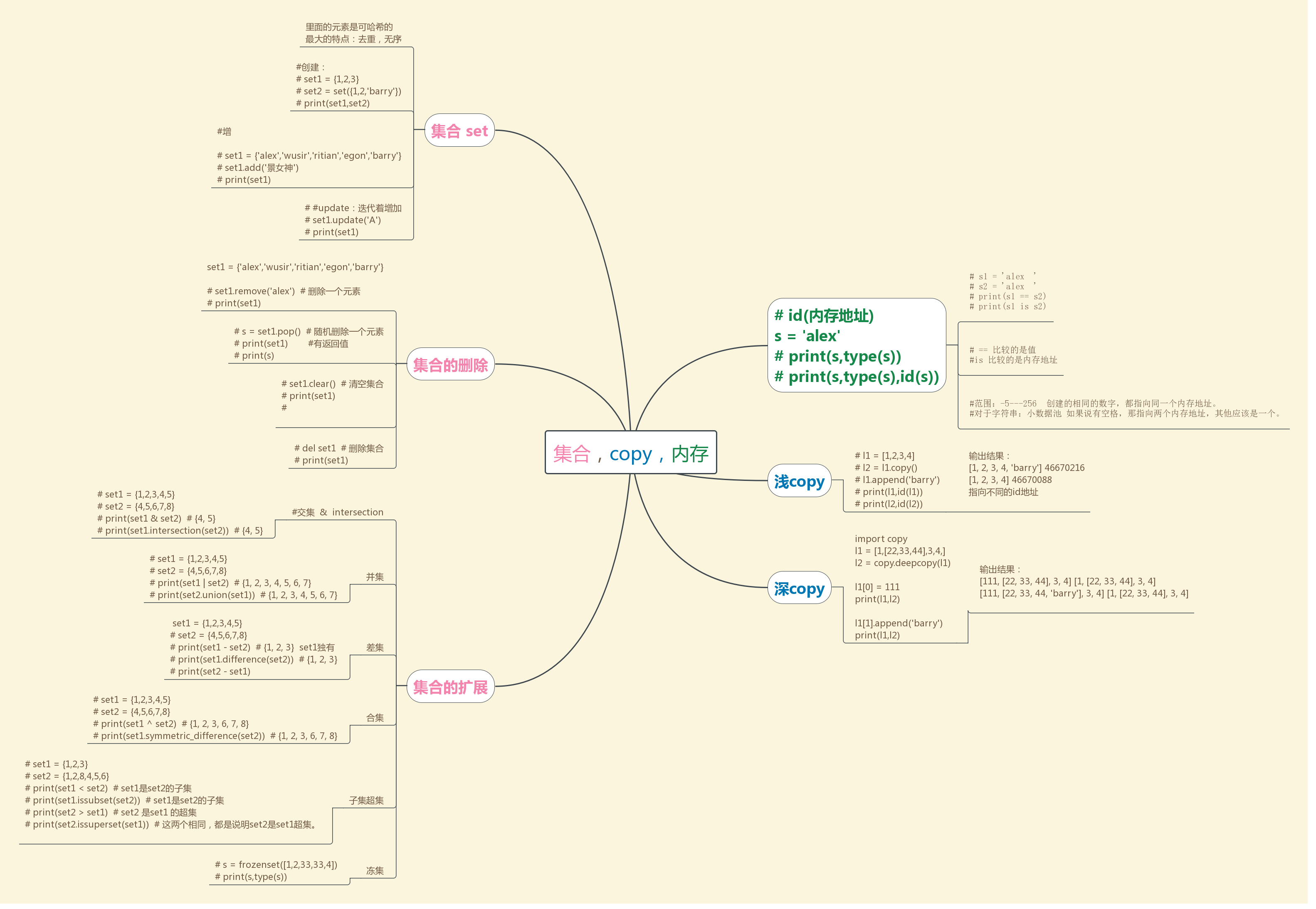
集合的补充:下面的思维导图有一个点搞错了,在这里纠正一下,没有合集,是反交集,^这个是反差集的意思 。
交集&,反交集^,差集-,并集|,然后就是子集和超集

数据类型补充:
'''
1,int
2,str
3,tuple
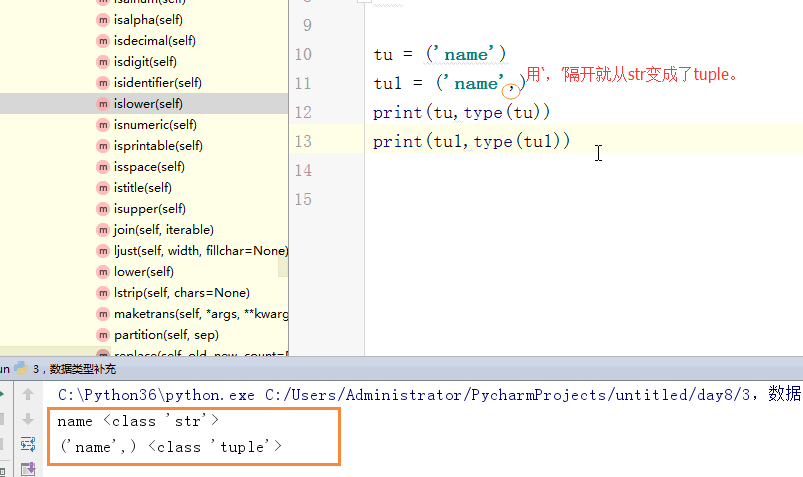
tu = (1)
tu1 = ('name',)
print(tu,type(tu)) # 1 <class 'int'>
print(tu1,type(tu1)) tu = ('dfas')
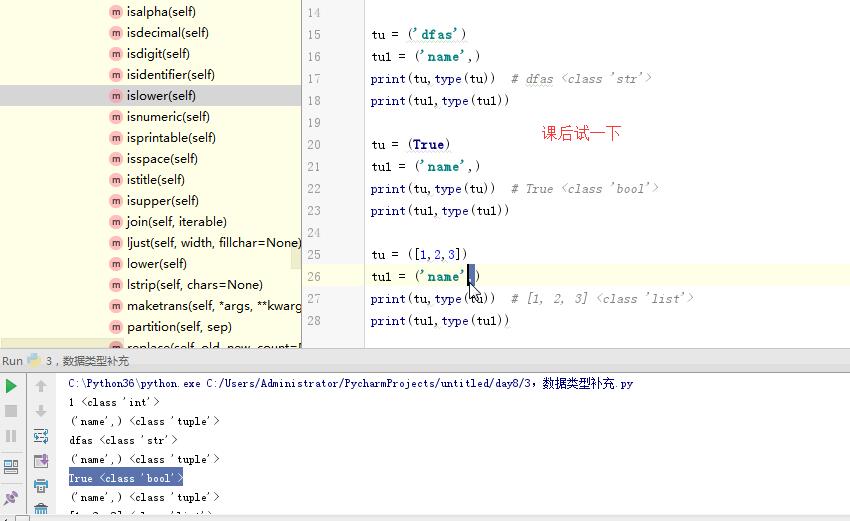
tu1 = ('name',)
print(tu,type(tu)) # dfas <class 'str'>
print(tu1,type(tu1)) tu = (True)
tu1 = ('name',)
print(tu,type(tu)) # True <class 'bool'>
print(tu1,type(tu1)) tu = ([1,2,3])
tu1 = ('name',)
print(tu,type(tu)) # [1, 2, 3] <class 'list'>
print(tu1,type(tu1))
4,列表
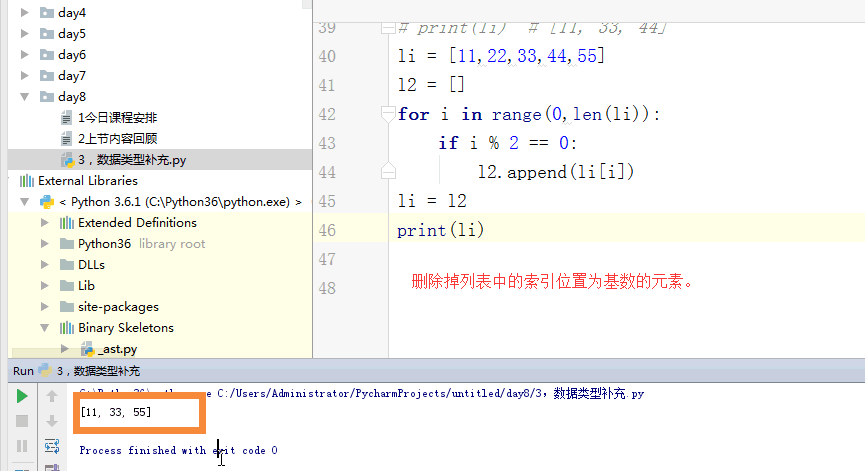
当循环列表时,如果在循环中删除某个或者某些元素,列表元素个数改变,索引改变,容易出错。 5,字典
当循环字典时,如果在循环中删除某个或者某些键值对,字典的键值对个数改变,长度改变,容易出错。 转化:
1,int --> str :str(int)
2, str ---> int:int(str) 字符串必须全部由数字组成
3,bool ---> str:str(bool)
4,str ----> bool(str) 除了空字符串,剩下的都是True
5,int ---> bool 除了0,剩下的全是True
6,bool ---> int True ---> 1 False ----> 0
7,str ---> list split
8,list ---> str() join
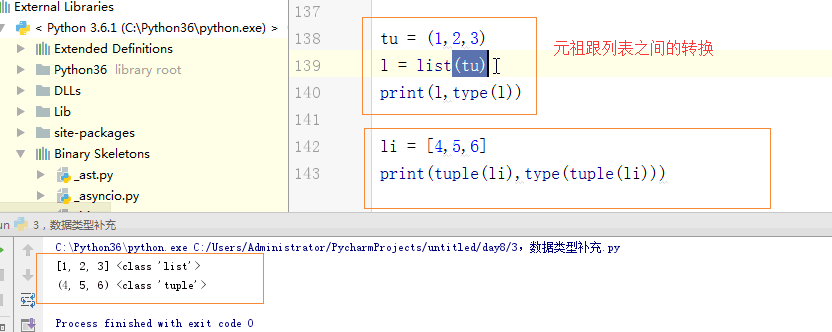
9,元祖列表:
tu = (1,2,3)
l = list(tu)
print(l,type(l)) li = [4,5,6]
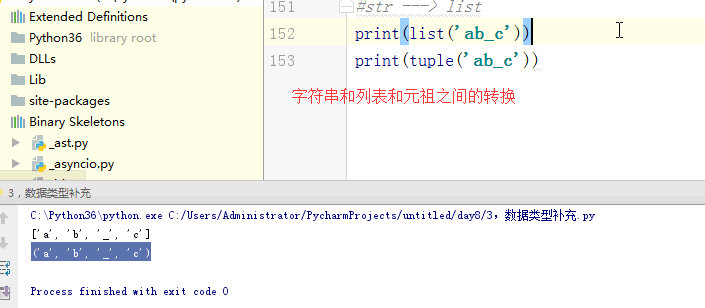
print(tuple(li),type(tuple(li))) #str ---> list
print(list('ab_c')) #str ---> list
print(tuple('ab_c')) # 0,"",{},[],(),set() ---->False '''
'''
# li = [11,22,33,44,55]
# for i in range(0,len(li)):
# # i = 0 i= 1 i = 2 i = 3
# del li[li]
#li[22,33,44,55] li [22,44,55] li [22,44] # for i in li:
# if li.index(i) % 2 == 1: # i = 11 i = 22 i = 44
# del li[li.index(i)] # li [11,22,33,44,55] li = [11,33,44,55] [11,33,44,55]
# print(li) # [11, 33, 44]
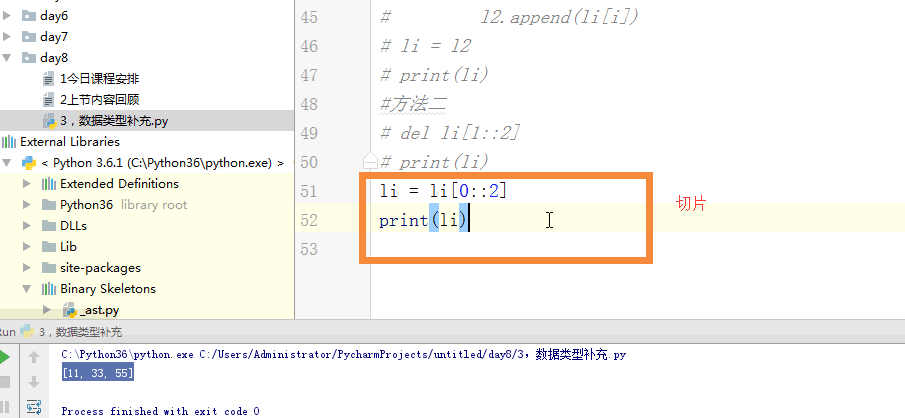
li = [11,22,33,44,55]
# 方法一
# l2 = []
# for i in range(0,len(li)):
# if i % 2 == 0:
# l2.append(li[i])
# li = l2
# print(li)
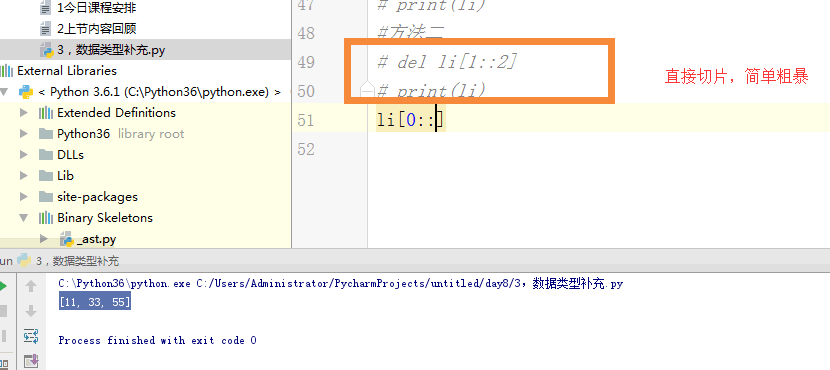
#方法二
# del li[1::2]
# print(li)
# li = li[0::2]
# print(li) #方法三
# li = [11,22,33,44,55]
# for i in range(0,len(li)//2):
# # i = 0 # i = 1
# del li[i+1]
# # li = [11,33,44,55] li = [11,33,55]
# print(li) # li = [11,22,33,44,55]
# # for i in range(len(li)-1,0,-1):
# # print(i)
# for i in range(len(li)-1,0,-1):
# if i % 2 == 1:
# del li[i]
# print(li)
'''
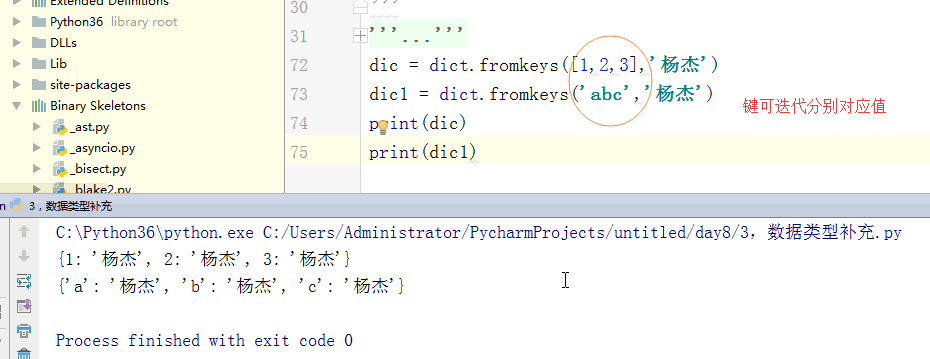
# dic = dict.fromkeys([1,2,3],'杨杰')
# # dic1 = dict.fromkeys('abc','杨杰')
# print(dic)
# dic[4] = 'dfdsa' # print(dic1)
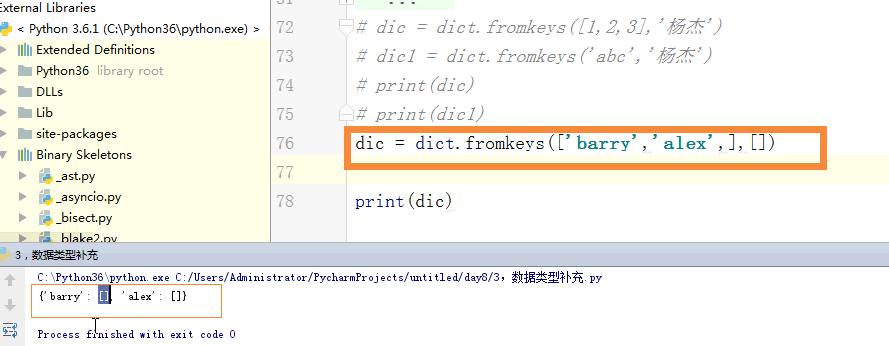
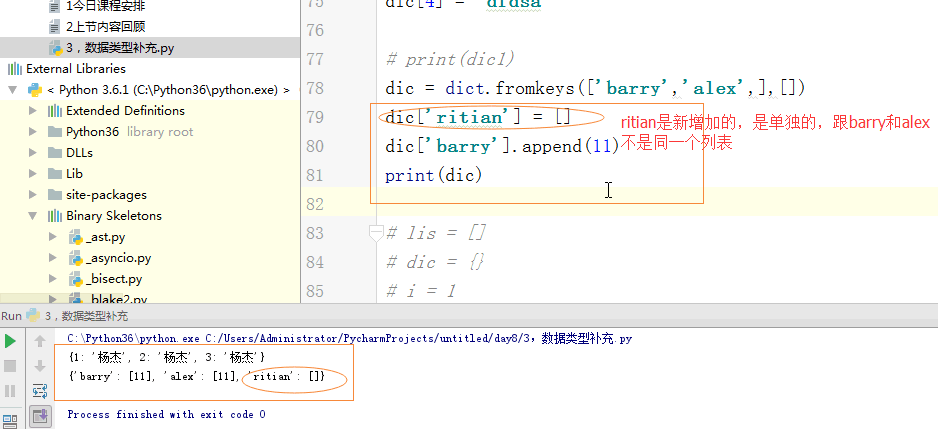
# dic = dict.fromkeys(['barry','alex',],[])
# dic['ritian'] = []
# dic['barry'] = []
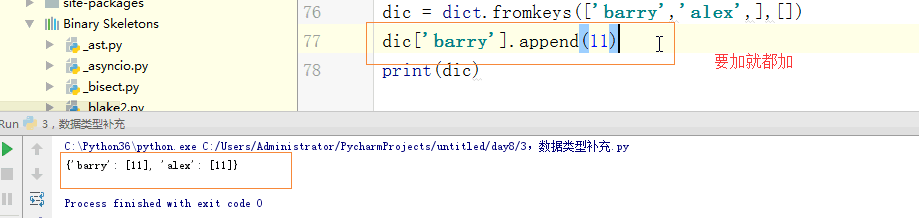
# dic['barry'].append(11)
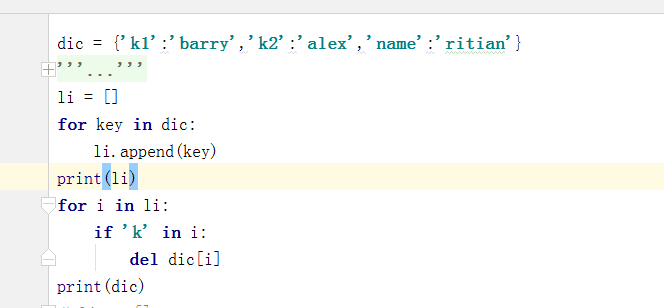
# print(dic) dic = {'k1':'barry','k2':'alex','name':'ritian'}
'''
# for i in dic:
# if 'k' in i:
# del dic[i]
# a = dic.keys()
# for i in list(a):
# if 'k' in i:
# del dic[i]
# print(dic)
'''
# for i in dic:
# if 'k' in i:
# del dic[i]
# print(dic)
# for key in dic:
# print(key)
# li = []
# for key in dic:
# li.append(key)
# print(li)
# for i in li:
# if 'k' in i:
# del dic[i]
# print(dic)
# lis = []
# dic = {}
# i = 1
# dic["k1"] = i
# print("此时字典为%s:"%dic)
# lis.append(dic)
# print("此时列表为%s:"%lis)
# j = 2
# dic["k1"] = j
# print("此时字典为%s:"%dic)
# lis.append(dic)
# print("此时列表为%s:"%lis) # tu = (1,2,3)
# l = list(tu)
# print(l,type(l))
#
# li = [4,5,6]
# print(tuple(li),type(tuple(li))) # #str ---> list
# print(list('ab_c'))
#
# #str ---> list
# print(tuple('ab_c')) # 0,"",{},[],(),set() ---->False
今日内容梗概:
1,上节内容回顾 2,数据类型补充 3,集合。 4,深浅拷贝。
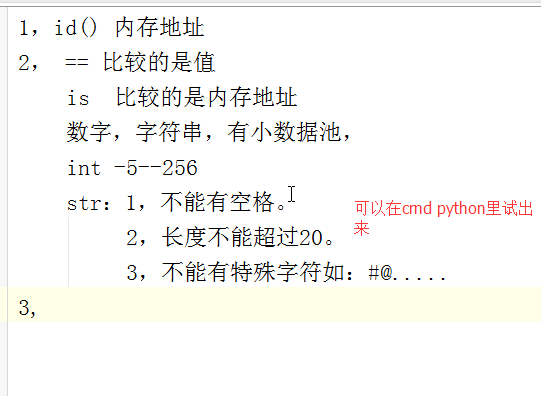
上节内容回顾:
1,id() 内存地址 2, == 比较的是值 is 比较的是内存地址 数字,字符串,有小数据池, int -5--256 str:1,不能有空格。 2,长度不能超过20。 3,不能有特殊字符如:#@.....
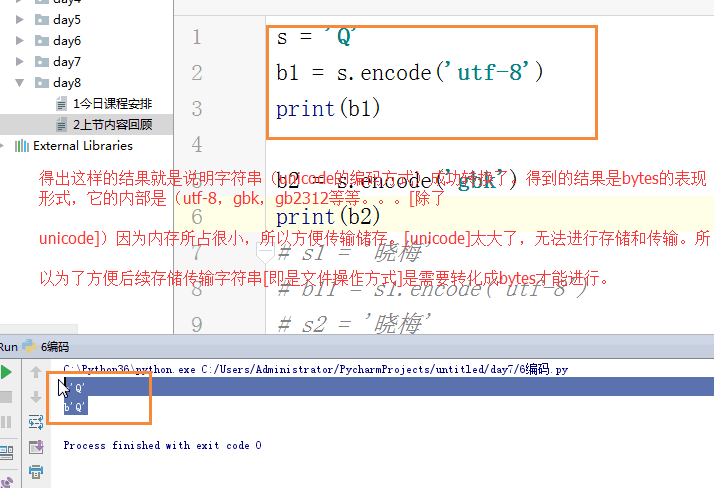
3,enmurate枚举 iterable: str,list,tuple,dict,set for i in enmurate(iterable): pirnt(i) for i in enmurate(['barry','alex']): pirnt(i) # (0,'barry') (1,'alex') for index,i in enmurate(['barry','alex']): pirnt(index,i) # 0,'barry' 1,'alex' for index,i in enmurate(['barry','alex'],100): pirnt(index,i) # 100,'barry' 101,'alex' 4,编码 py3: str:表现形式:s = 'alex' 实际编码方式:unicode bytes:表现形式:s = b'alex' 实际编码方式:utf-8,gbk,gb2312... s = b'\x2e\x2e\x2e\x2e\x2e\x2e' unicode:所有字符(无论英文,中文等) 1个字符:4个字节 gbk:一个字符,英文1个字节,中文两个字节。 utf-8:英文 1 个字节,欧洲:2个字节,亚洲:3个字节。
集合:
# set1 = {'1','alex',2,True,2,'alex'}
# print(set1)
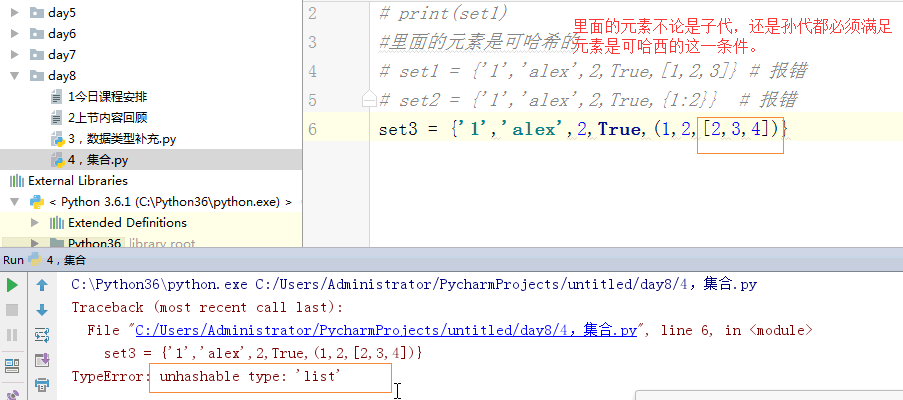
#里面的元素是可哈希的
# set1 = {'1','alex',2,True,[1,2,3]} # 报错
# set2 = {'1','alex',2,True,{1:2}} # 报错
# set3 = {'1','alex',2,True,(1,2,[2,3,4])} # 报错
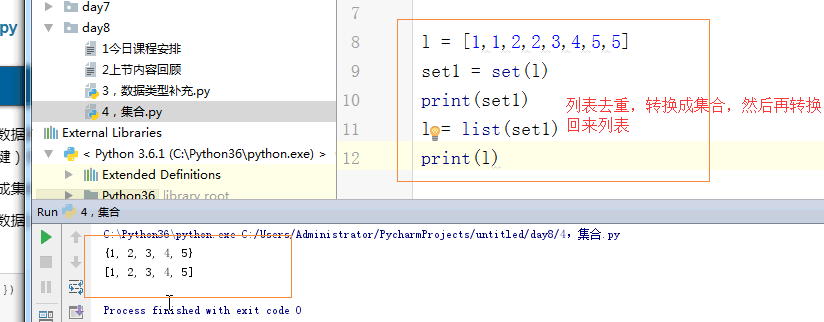
# l = [1,1,2,2,3,4,5,5]
# set1 = set(l)
# print(set1)
# l = list(set1)
# print(l)
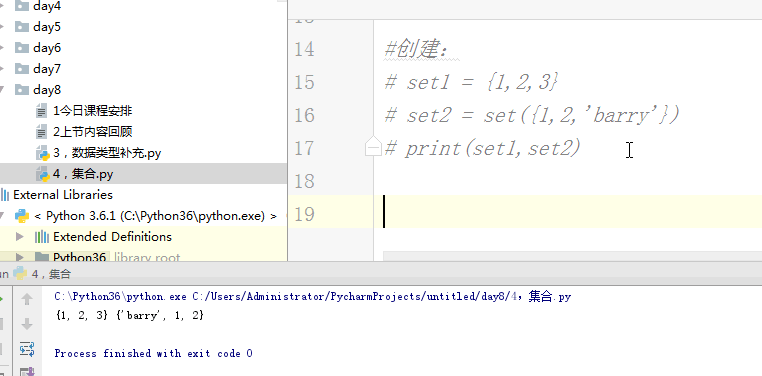
#创建:
# set1 = {1,2,3}
# set2 = set({1,2,'barry'})
# print(set1,set2)
#增
# set1 = {'alex','wusir','ritian','egon','barry'}
# set1.add('景女神')
# print(set1)
# #update:迭代着增加
# set1.update('A')
# print(set1)
# set1.update('老师')
# print(set1)
# set1.update([1,2,3])
# print(set1)
# set1 = {'alex','wusir','ritian','egon','barry'}
# set1.remove('alex') # 删除一个元素
# print(set1)
# s = set1.pop() # 随机删除一个元素 有返回值
# print(set1)
# print(s)
#
# set1.clear() # 清空集合
# print(set1)
#
# del set1 # 删除集合
# print(set1)
# for i in set1:
# print(i)
# tu = ()
# print(tu,type(tu))
#交集 & intersection
# set1 = {1,2,3,4,5}
# set2 = {4,5,6,7,8}
# print(set1 & set2) # {4, 5}
# print(set1.intersection(set2)) # {4, 5}
# set1 = {1,2,3,4,5}
# set2 = {4,5,6,7,8}
# print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7}
# print(set2.union(set1)) # {1, 2, 3, 4, 5, 6, 7}
# set1 = {1,2,3,4,5}
# set2 = {4,5,6,7,8}
# print(set1 - set2) # {1, 2, 3} set1独有
# print(set1.difference(set2)) # {1, 2, 3}
# print(set2 - set1)
# set1 = {1,2,3,4,5}
# set2 = {4,5,6,7,8}
# print(set1 ^ set2) # {1, 2, 3, 6, 7, 8}
# print(set1.symmetric_difference(set2)) # {1, 2, 3, 6, 7, 8}
# set1 = {1,2,3}
# set2 = {1,2,8,4,5,6}
# print(set1 < set2) # set1是set2的子集
# print(set1.issubset(set2)) # set1是set2的子集
# print(set2 > set1) # set2 是set1 的超集
# print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。
# s = frozenset([1,2,33,33,4])
# print(s,type(s))
集合的补充:之前的思维导图有一个点搞错了,在这里纠正一下,没有合集,是反交集,^这个是反差集的意思 。
交集&,反交集^,差集-,并集|,然后就是子集和超集
copy深浅:
# l1 = [1,2,3]
# l2 = l1
# l1.append('barry')
# print(l1) # [1,2,3,'barry']
# print(l2) # [1,2,3] # dic = {'name':'barry'}
# dic1 = dic
# dic['age'] = 18
# print(dic)
# print(dic1) # s = 'alex'
# s1 = s
# s3 = s.replace('e','E')
# print(s)
# print(s1)
# print(s3)
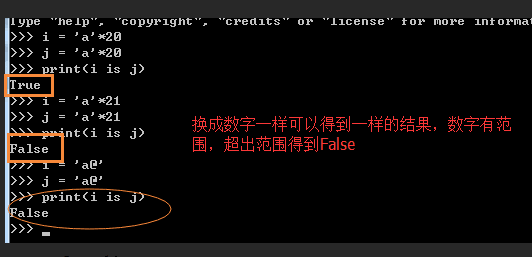
# s = 'alex'
# s1 = s
# print(id(s),id(s1))
# s = 'alex '
# s1 = 'alex '
# print(id(s),id(s1)) # 浅copy 以list举例
# l1 = [1,2,3,4]
# l2 = l1.copy()
# l1.append('barry')
# print(l1,id(l1))
# print(l2,id(l2)) # l1 = [1,[22,33,44],3,4,]
# l2 = l1.copy()
# l1[1].append('55')
# # print(l1,id(l1),id(l1[1]))
# # print(l2,id(l2),id(l2[1]))
# l1[0] = 111
# print(l1,l2) #深copy
import copy
l1 = [1,[22,33,44],3,4,]
l2 = copy.deepcopy(l1) l1[0] = 111
print(l1,l2) l1[1].append('barry')
print(l1,l2)
#深浅copy的区别是,浅copy的列表嵌,
从第一层开始,改变原本的,copy的那一份并不会变
从第二层的列表开始,改变原本的,copy的那一份也会跟着改变;
l = [1,2,3,[3,4]]
l1 = l.copy()
l[-1].append(8);
l.append(89)
print(l,l1)
输出结果是:[1, 2, 3, [3, 4, 8],89] [1, 2, 3, [3, 4, 8]]
#对于深copy来说,不论有几层的嵌套,随便改变里面的每一层,都不会影响原本的或者copy的那一份。
import copy
l = [1,2,3,[3,4]]
l1 = copy.deepcopy(l)
l[-1].append(8)
print(l,l1)
[1, 2, 3, [3, 4, 8]] [1, 2, 3, [3, 4]]
l1 = [1, 2, 3, ['barry', 'alex']] # 浅copy
l2 = l1.copy()
# l1[3].append('b')
# l1.insert(l1[0], 'abs')
# print(l1, id(l1))
# print(l2, id(l2))
'''
[1, 2, 3, ['barry', 'alex', 'b']] 4367967368
[1, 2, 3, ['barry', 'alex', 'b']] 4367868680 l2是copy出来的,浅copy的时候,原来的内嵌列表改变,它也跟着变;
'''
'''
[1, 'abs', 2, 3, ['barry', 'alex']] 4367963272
[1, 2, 3, ['barry', 'alex']] 4367868680 原来的外层改变,它不变
''' # 深copy
l3 = copy.deepcopy(l1)
l1[3].append('bpo')
l1.append('bpo') # print(l3,id(l3))
# print(l1,id(l1)) '''
[1, 2, 3, ['barry', 'alex']] 4368117640
[1, 2, 3, ['barry', 'alex', 'bpo'], 'bpo'] 4367967368 # 对于深copy来说,不论改变原来的哪一层,copy出来的都不会随之改变
'''
周末计划安排:
1,周六上午:整理知识点,+ 错题。 2,周六下午:小憩一下,做作业,看个电影。 3,周天上午:睡个懒觉,整理作业+预习。 4,周天下午:自由发挥。
周六作业: # 30、购物车 # 功能要求:要求用户输入总资产,例如:2000显示商品列表, 让用户根据序号选择商品,加入购物车购买,如果商品总额大于总资产,提示账户余额不足, 否则,购买成功。 # goods=[{"name":"电脑","price":1999}, {"name":"鼠标","price":10}, {"name":"游艇","price":20}, {"name":"美女","price":998}, ]
shopping_car = []
1 input(钱) 序号,商品,钱 序号选择:判断条件 深一步,你的 input(钱) 与 price":1999比较








day8数据类型补充,集合,深浅拷贝的更多相关文章
- Day7--Python--基础数据类型补充,集合,深浅拷贝
一.基础数据类型补充 1.join() 把列表中的每一项(必须是字符串)用字符串拼接 与split()相反 lst = ["汪峰", "吴君如", " ...
- python摸爬滚打之day07----基本数据类型补充, 集合, 深浅拷贝
1.补充 1.1 join()字符串拼接. strs = "阿妹哦你是我的丫个哩个啷" nw_strs = "_".join(strs) print(nw_s ...
- python基础(9):基本数据类型四(set集合)、基础数据类型补充、深浅拷贝
1. 基础数据类型补充 li = ["李嘉诚", "麻花藤", "⻩海峰", "刘嘉玲"] s = "_&qu ...
- Python基础数据类型补充及深浅拷贝
本节主要内容:1. 基础数据类型补充2. set集合3. 深浅拷贝主要内容:一. 基础数据类型补充首先关于int和str在之前的学习中已经讲了80%以上了. 所以剩下的自己看一看就可以了.我们补充给一 ...
- is,数据类型补充,set,深浅拷贝
十二.基础数据类型补充: 1.join 可以把列表变成字符串. s = ‘abc’ s1 = s.join(‘非常可乐’) print(s1) #非abc常abc可abc乐abc s = " ...
- day8 python学习 集合 深浅拷贝
1.内存地址: 字符串在20位以内,没有空格,没有特殊字符的情况下,同样的字符串内存地址是一样的 2.元组中:在只有一个值的时在后边加逗号和没有逗号的区别 t1=(1) 不加逗号这个值是什么类型就打印 ...
- 基本数据类型补充,set集合,深浅拷贝等
1.join:将字符串,列表,用指定的字符连接,也可以用空去连接,这样就可以把列表变成str ll = ["wang","jian","wei&quo ...
- python学习打卡 day07 set集合,深浅拷贝以及部分知识点补充
本节的主要内容: 基础数据类型补充 set集合 深浅拷贝 主要内容: 一.基础数据类型补充 字符串: li = ["李嘉诚", "麻花藤", "⻩海峰 ...
- 6.Python初窥门径(小数据池,集合,深浅拷贝)
Python(小数据池,集合,深浅拷贝) 一.小数据池 什么是小数据池 小数据池就是python中一种提高效率的方式,固定数据类型,使用同一个内存地址 小数据池 is和==的区别 == 判断等号俩边的 ...
- day09-3 数据类型总结,深浅拷贝
目录 数据类型总结,深浅拷贝 存一个值还是多个值 有序 or 无序 可变 or 不可变 浅拷贝和深拷贝的区别(只针对可变类型) 1.拷贝: 3.深拷贝 总结: 数据类型总结,深浅拷贝 存一个值还是多个 ...
随机推荐
- PyJWT 使用
最近要用 Falsk 开发一个大点的后端,为了安全考虑,弃用传统的Cookie验证.转用JWT. 其实 Falsk 有一个 Falsk-JWT 但是我觉得封装的太高,还是喜欢通用的 PyJWT . J ...
- vue---分页搜索功能
<template> <div> <div class="searc"> <input type="search" p ...
- C# 将Excel转换为PDF
C# 将Excel转换为PDF 转换场景 将Excel转换为PDF是一个很常用的功能,常见的转换场景有以下三种: 转换整个Excel文档到PDF转换Excel文档的某一个工作表到PDF转换Excel文 ...
- django 中自带的加密方法
导入django 自带的加密算法 和flask中的哈希加密有一曲同工之妙. from django.contrib.auth.hashers import make_password, ...
- ionic2 子页面隐藏去掉底部tabs导航,子页面全占满显示方法(至今为止发现的最靠谱的方法)
项目中遇到 tabs 字页面 可以用以下代码隐藏的方式: imports: [ BrowserModule, // IonicModule.forRoot(MyApp), HttpModule, Io ...
- unity 3D 学习笔记
1.父对象的初始位置设,即刚开始的空对象的根节点位置应当设置成(0,0,0) 这样设置可以避免以后出现奇怪的坐标. GameObject实际上就是一些组件的容器. unity 使用公用变量原因是,在U ...
- JS去除空格和换行的正则表达式(推荐)
//去除空格 String.prototype.Trim = function() { return this.replace(/\s+/g, ""); } //去除换 ...
- 数据增强(每10度进行旋转,进行一次增强,然后对每张图片进行扩充10张patch,最后得到原始图片数*37*10数量的图片)
# -*- coding: utf-8 -*-"""Fourmi Editor This is a temporary script file.""& ...
- 使用python调用wps v9转换office文件到pdf
#!/usr/bin/python2.6 # -*- coding: utf-8 -*- # pip install timeout-decorator import os import win32c ...
- CAS单点登录--转载
一:单点登录介绍 单点登录( Single Sign-On , 简称 SSO )是目前比较流行的服务于企业业务整合的解决方案之一, SSO 使得在多个应用系统中,用户只需要 登录一次 就可以访问所有相 ...