Mybatis数据源
在描述mybatis数据源之前,先抛出几个问题,这几个问题都能在本文得到解答
1.mybatis是如何获取到mysql连接的? 2.mybatis的Connection是怎么被创建的?
1.Datasource的分类
我们已一段mybatis的配置文件为例
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">
<property name="..." value="..."/>
</transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
datasource的type共有三个选项
UNPOOLED 不使用连接池的数据源 POOLED 使用连接池的数据源 JNDI 使用JNDI实现的数据源
2.Datasource的配置加载与创建
mybatis在项目启动阶段会加载配置文件,读取xml中的配置信息到Configuration中。我们看下datasource是怎么加载进来的。这段代码在org.apache.ibatis.builder.xml.XMLConfigBuilder#parseConfiguration

点进去,找到这个方法。

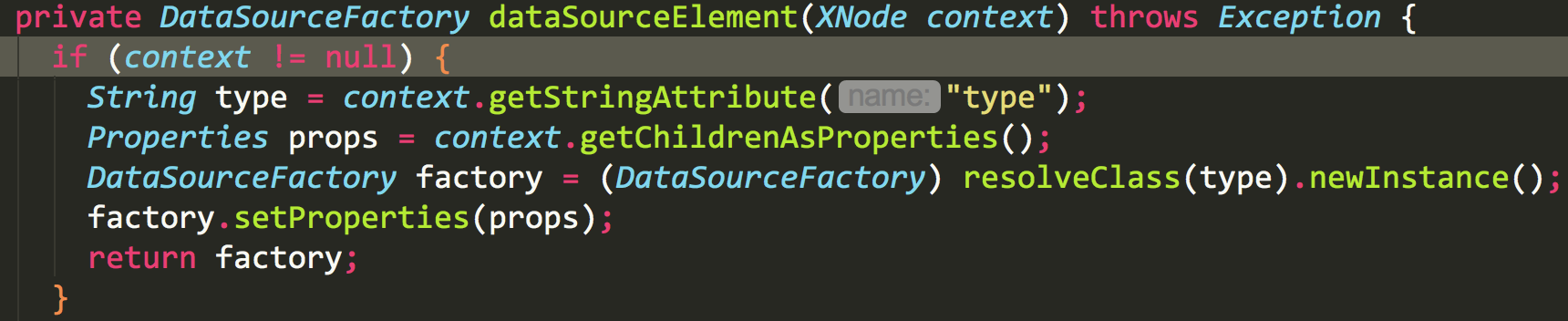
这里通过工厂模式,反射生成一个DatasourceFactory。
这里DataSourceFactory有三个子类,也就是上述三个datasource的类型。

3.Connection的创建
当Datasource的配置加载到configuration后。每一次执行sql都需要Datasource对象创建Connection去连接数据库。
我们以一次查询为例,看下这个connection到底是怎么生成的。



transaction对象持有connection和datasource,我们再点进去

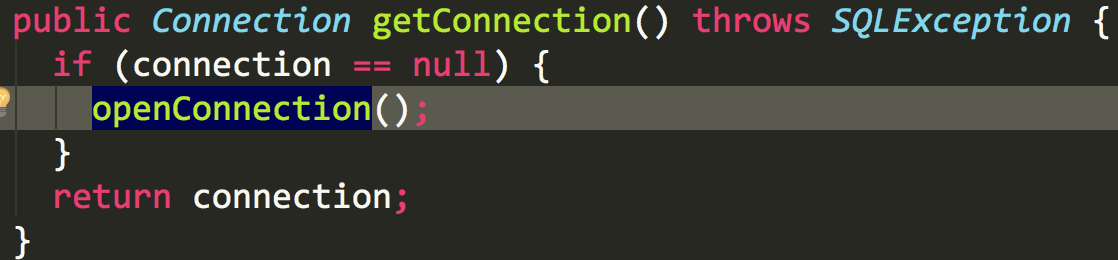
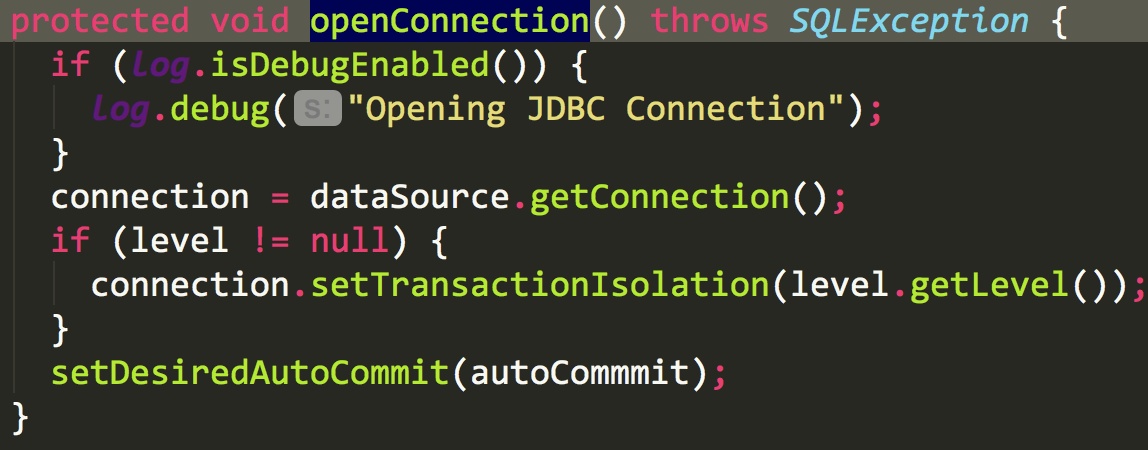
终于看到了真正获取connection是datasource,那datasource是怎么获取connection的呢?
4.连接池
datasource有三种类型,相对应的每种datasource创建connection各不相同。常见的是POOLEDA和UNPOOLED两种类型。
UNPOOLED顾名思义就是不用连接池的方式,每次用到一个就生产一个

POOLEDA类型采用了连接池的方式,内部通过Poolstate对象来维护连接池对象

Poolstate内部有两个数组,idleConnections用来存放空闲的connection,activeConnections用来存放连接中的connection。

具体的获取一个Connection连接如下
private final PoolState state = new PoolState(this);
private PooledConnection popConnection(String username, String password) throws SQLException {
boolean countedWait = false;
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0; while (conn == null) {
//这个对象锁锁的范围有点大,不过这也是因为PoolState内部的两个集合是ArrayList会产生并发问题
synchronized (state) {
//有空闲连接
if (state.idleConnections.size() > 0) {
// Pool has available connection
conn = state.idleConnections.remove(0);
if (log.isDebugEnabled()) {
log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
}
} else {
// Pool does not have available connection
if (state.activeConnections.size() < poolMaximumActiveConnections) {
// Can create new connection
conn = new PooledConnection(dataSource.getConnection(), this);
@SuppressWarnings("unused")
//used in logging, if enabled
Connection realConn = conn.getRealConnection();
if (log.isDebugEnabled()) {
log.debug("Created connection " + conn.getRealHashCode() + ".");
}
} else {
// Cannot create new connection
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
if (longestCheckoutTime > poolMaximumCheckoutTime) {
// Can claim overdue connection
state.claimedOverdueConnectionCount++;
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
state.activeConnections.remove(oldestActiveConnection);
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
oldestActiveConnection.getRealConnection().rollback();
}
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
oldestActiveConnection.invalidate();
if (log.isDebugEnabled()) {
log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
}
} else {
// Must wait
try {
if (!countedWait) {
state.hadToWaitCount++;
countedWait = true;
}
if (log.isDebugEnabled()) {
log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
}
long wt = System.currentTimeMillis();
state.wait(poolTimeToWait);
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
} catch (InterruptedException e) {
break;
}
}
}
}
if (conn != null) {
if (conn.isValid()) {
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
} else {
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
}
state.badConnectionCount++;
localBadConnectionCount++;
conn = null;
if (localBadConnectionCount > (poolMaximumIdleConnections + 3)) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Could not get a good connection to the database.");
}
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
} } if (conn == null) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
} return conn;
}
1. 先看是否有空闲(idle)状态下的PooledConnection对象,如果有,就直接返回一个可用的PooledConnection对象;否则进行第2步。
2. 查看活动状态的PooledConnection池activeConnections是否已满;如果没有满,则创建一个新的PooledConnection对象,然后放到activeConnections池中,然后返回此PooledConnection对象;否则进行第三步;
3. 看最先进入activeConnections池中的PooledConnection对象是否已经过期:如果已经过期,从activeConnections池中移除此对象,然后创建一个新的PooledConnection对象,添加到activeConnections中,然后将此对象返回;否则进行第4步。
4. 线程等待,循环2步
以上描述的是通过连接池获取connection,那在关闭connection后,参照获取连接的步骤,首先从activeConnections中移除,再判断idle数组是否已经满了,如果满了再判断下数组中第一个连接是否已经任然可用,如果可用再把这个这个连接销毁。
上文我们提到了PoolState
两个集合里面存放着PooledConnection对象,PooledConnection对象是Connection的代理类
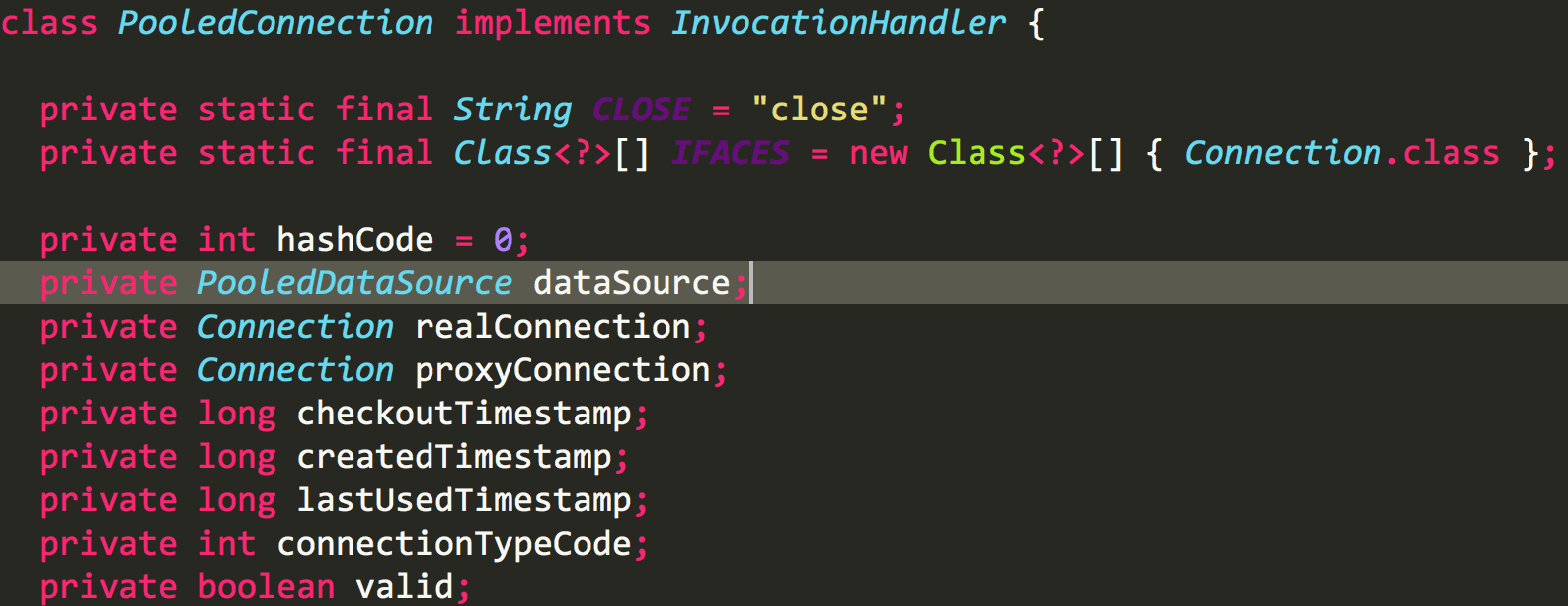
PooledConnection相比Connection多了什么呢,答案就在invoke方法中,当connection对象调用close方法时,会调用datasource的pushConnection方法,pushConnection的方法大致和上面的猜想一致

Mybatis数据源的更多相关文章
- 《深入理解mybatis原理》 Mybatis数据源与连接池
对于ORM框架而言,数据源的组织是一个非常重要的一部分,这直接影响到框架的性能问题.本文将通过对MyBatis框架的数据源结构进行详尽的分析,并且深入解析MyBatis的连接池. 本文首先会讲述MyB ...
- 《深入理解mybatis原理3》 Mybatis数据源与连接池
<深入理解mybatis原理> Mybatis数据源与连接池 对于ORM框架而言,数据源的组织是一个非常重要的一部分,这直接影响到框架的性能问题.本文将通过对MyBatis框架的数据源结构 ...
- mybatis深入理解(二)-----Mybatis数据源与连接池
对于ORM框架而言,数据源的组织是一个非常重要的一部分,这直接影响到框架的性能问题.本文将通过对MyBatis框架的数据源结构进行详尽的分析,并且深入解析MyBatis的连接池.本文首先会讲述MyBa ...
- mybatis数据源与连接池
1.概念介绍1.1 数据源:顾名思义,数据的来源,它包含了数据库类型信息,位置和数据等信息,一个数据源对应一个数据库. 1.2 连接池:在做持久化操作时,需要通过数据库连接对象来连接数据库,而连接池就 ...
- MyBatis 数据源的原理和机制
回顾JDBC JDBC访问数据库流程 加载驱动 获取Connection连接对象(消耗性能) 获取PrepareStatement对象 执行SQL语句 获取结果集 关闭Connection连接对象 存 ...
- 浩哥解析MyBatis源码(四)——DataSource数据源模块
原创作品,可以转载,但是请标注出处地址:http://www.cnblogs.com/V1haoge/p/6634880.html 1.回顾 上一文中解读了MyBatis中的事务模块,其实事务操作无非 ...
- 浩哥解析MyBatis源码(五)——DataSource数据源模块之非池型数据源
1 回顾 上一篇中我解说了数据源接口DataSource与数据源工厂接口DataSourceFactory,这二者是MyBatis数据源模块的基础,包括本文中的非池型非池型数据源(UnpooledDa ...
- MyBatis源码解析(五)——DataSource数据源模块之非池型数据源
原创作品,可以转载,但是请标注出处地址:http://www.cnblogs.com/V1haoge/p/6675633.html 1 回顾 上一篇中我解说了数据源接口DataSource与数据源工厂 ...
- MyBatis源码解析(四)——DataSource数据源模块
原创作品,可以转载,但是请标注出处地址:http://www.cnblogs.com/V1haoge/p/6634880.html 1.回顾 上一文中解读了MyBatis中的事务模块,其实事务操作无非 ...
随机推荐
- Web表现层
目录 Web表现层调用过程... 2 延迟... 3 什么是延迟... 3 延迟的构成... 3 最基本的优化思路:... 4 Web表现层性能优化... 4 Web性能的基本指标... 4 Web性 ...
- go 函数类型
在go中,函数也可以被当成数据类型 e.g:下面有两个函数,+.-,然后定义了一个函数类型FuncType1,然后对funcType1附于不同的函数,则funcType1就可以执行相应的函数 pack ...
- 启动eclipse could not create the java Vittual Machine
查询并几种方法: 1.都说是 eclipse.ini 环境初始文件的内存问题,续增大堆内存大小,具体配置如,如果找不到问题所在可以试试(该方法是确定环境变量没问题下试行) -Xms64m-Xmx25 ...
- HelloWorld带我入门JAVA(一)
基本环境配置可以百度完成,给个比较全面的网址http://c.biancheng.net/java/10/ 创建第一个java工程 通过Eclipse运行程序 启动Eclipse,在菜单中选择“文件 ...
- JSF初学之概念篇1
先转一篇介绍JSF的文章: Javaserver Faces 简介 — 什么是 JSF? 作者:Chris Schalk,Oracle Corporation2005 年 4 月 什么是 JSF? J ...
- java面试问题收集(2)
1 Integer int相等问题 Integer对象和int比较的时候会有一个拆箱的过程,始终相等 Integer和new Integer对象不会相等,引用不同 两个Integer对象比较,Inte ...
- 不停止nginx服务,使配置文件生效
ps -ef | grep "nginx: master process" | grep -v "grep" | awk -F ' ' '{print $2}' ...
- HashMap内部结构及实现原理
简单介绍 在研究HashMap之前,我们先大概了解下其他数据结构在新增,查找等基础操作执行性能 数组:采用一段连续的存储单元来存储数据.对于指定下标的查找,时间复杂度为O(1):通过给定值进行查找,需 ...
- 在Spring-Boot中实现通用Auth认证的几种方式
code[class*="language-"], pre[class*="language-"] { background-color: #fdfdfd; - ...
- Java开发环境配置(Jdk、Tomcat、eclipse)
Java项目通常会在像eclipse这样的集成开发工具上进行高效的开发,开发之前需要进行一系列的安装及配置,会经过以下几个步骤: 1.官网上下载jdk.tomcat.eclipse 2.安装上面下载的 ...