纸上谈兵: 堆 (heap)
纸上谈兵: 堆 (heap)
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明。谢谢!
堆(heap)又被为优先队列(priority queue)。尽管名为优先队列,但堆并不是队列。回忆一下,在队列中,我们可以进行的限定操作是dequeue和enqueue。dequeue是按照进入队列的先后顺序来取出元素。而在堆中,我们不是按照元素进入队列的先后顺序取出元素的,而是按照元素的优先级取出元素。
这就好像候机的时候,无论谁先到达候机厅,总是头等舱的乘客先登机,然后是商务舱的乘客,最后是经济舱的乘客。每个乘客都有头等舱、商务舱、经济舱三种个键值(key)中的一个。头等舱->商务舱->经济舱依次享有从高到低的优先级。
再比如,封建社会的等级制度,也是一个堆。在这个堆中,国王、贵族、骑士和农民是从高到低的优先级。
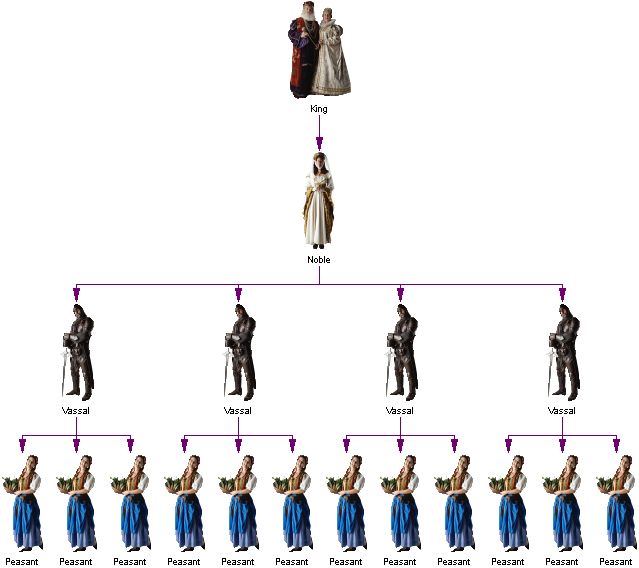
封建等级
Linux内核中的调度器(scheduler)会按照各个进程的优先级来安排CPU执行哪一个进程。计算机中通常有多个进程,每个进程有不同的优先级(该优先级的计算会综合多个因素,比如进程所需要耗费的时间,进程已经等待的时间,用户的优先级,用户设定的进程优先程度等等)。内核会找到优先级最高的进程,并执行。如果有优先级更高的进程被提交,那么调度器会转而安排该进程运行。优先级比较低的进程则会等待。“堆”是实现调度器的理想数据结构。
(Linux中可以使用nice命令来影响进程的优先级)
堆的实现
堆的一个经典的实现是完全二叉树(complete binary tree)。这样实现的堆成为二叉堆(binary heap)。
完全二叉树是增加了限定条件的二叉树。假设一个二叉树的深度为n。为了满足完全二叉树的要求,该二叉树的前n-1层必须填满,第n层也必须按照从左到右的顺序被填满,比如下图:
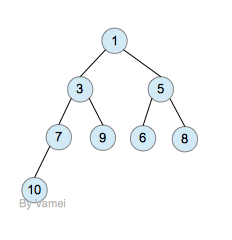
为了实现堆的操作,我们额外增加一个要求: 任意节点的优先级不小于它的子节点。如果在上图中,设定小的元素值享有高的优先级,那么上图就符合该要求。
这类似于“叠罗汉”。叠罗汉最重要的一点,就是让体重大的参与者站在最下面,让体重小的参与者站在上面 (体重小,优先级高)。为了让“堆”稳固,我们每次只允许最上面的参与者退出堆。也就是,每次取出的优先级最高的元素。

三个“叠罗汉”堆
我已经在排序算法简介及其C实现中实际使用了堆。堆的主要操作是插入和删除最小元素(元素值本身为优先级键值,小元素享有高优先级)。在插入或者删除操作之后,我们必须保持该实现应有的性质: 1. 完全二叉树 2. 每个节点值都小于或等于它的子节点。
在插入操作的时候,会破坏上述堆的性质,所以需要进行名为percolate_up的操作,以进行恢复。新插入的节点new放在完全二叉树最后的位置,再和父节点比较。如果new节点比父节点小,那么交换两者。交换之后,继续和新的父节点比较…… 直到new节点不比父节点小,或者new节点成为根节点。这样得到的树,就恢复了堆的性质。
我们插入节点2:
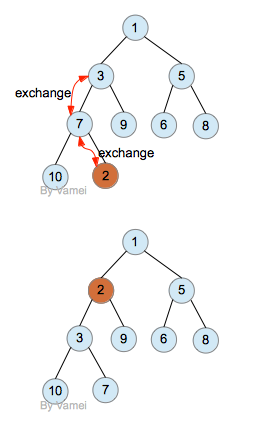
插入
删除操作只能删除根节点。根节点删除后,我们会有两个子树,我们需要基于它们重构堆。进行percolate_down的操作: 让最后一个节点last成为新的节点,从而构成一个新的二叉树。再将last节点不断的和子节点比较。如果last节点比两个子节点中小的那一个大,则和该子节点交换。直到last节点不大于任一子节点都小,或者last节点成为叶节点。
删除根节点1。如图:

删除根节点
下面是代码。与我们在二叉搜索树中使用表不同,我们这里使用数组来表示完全二叉树。数组下标为0的元素不用于储存节点,而用于记录完全二叉树中元素的总数。

/* By Vamei
Use an big array to implement heap
DECLARE: int heap[MAXSIZE] in calling function
heap[0] : total nodes in the heap
for a node i, its children are i*2 and i*2+1 (if exists)
its parent is i/2 */ void insert(int new, int heap[])
{
int childIdx, parentIdx;
heap[0] = heap[0] + 1;
heap[heap[0]] = new; /* recover heap property */
percolate_up(heap);
} static void percolate_up(int heap[]) {
int lightIdx, parentIdx;
lightIdx = heap[0];
parentIdx = lightIdx/2;
/* lightIdx is root? && swap? */
while((parentIdx > 0) && (heap[lightIdx] < heap[parentIdx])) {
/* swap */
swap(heap + lightIdx, heap + parentIdx);
lightIdx = parentIdx;
parentIdx = lightIdx/2;
}
} int delete_min(int heap[])
{
int min;
if (heap[0] < 1) {
/* delete element from an empty heap */
printf("Error: delete_min from an empty heap.");
exit(1);
} /* delete root
move the last leaf to the root */
min = heap[1];
swap(heap + 1, heap + heap[0]);
heap[0] -= 1; /* recover heap property */
percolate_down(heap); return min;
} static void percolate_down(int heap[]) {
int heavyIdx;
int childIdx1, childIdx2, minIdx;
int sign; /* state variable, 1: swap; 0: no swap */ heavyIdx = 1;
do {
sign = 0;
childIdx1 = heavyIdx*2;
childIdx2 = childIdx1 + 1;
if (childIdx1 > heap[0]) {
/* both children are null */
break;
}
else if (childIdx2 > heap[0]) {
/* right children is null */
minIdx = childIdx1;
}
else {
minIdx = (heap[childIdx1] < heap[childIdx2]) ?
childIdx1 : childIdx2;
} if (heap[heavyIdx] > heap[minIdx]) {
/* swap with child */
swap(heap + heavyIdx, heap + minIdx);
heavyIdx = minIdx;
sign = 1;
}
} while(sign == 1);
}
你可以尝试一下构建自己的main函数,测试相关的操作。
总结
堆,优先级
插入元素,删除最大优先级元素
欢迎继续阅读“纸上谈兵: 算法与数据结构”系列。
纸上谈兵: 堆 (heap)的更多相关文章
- JVM的堆(heap)、栈(stack)和方法区(method)
JVM主要由类加载器子系统.运行时数据区(内存空间).执行引擎以及与本地方法接口等组成.其中运行时数据区又由方法区Method Area.堆Heap.Java stack.PC寄存器.本地方法栈组成. ...
- [转]JVM 内存初学 (堆(heap)、栈(stack)和方法区(method) )
这两天看了一下深入浅出JVM这本书,推荐给高级的java程序员去看,对你了解JAVA的底层和运行机制有比较大的帮助.废话不想讲了.入主题: 先了解具体的概念:JAVA的JVM的内存可分为3个区:堆(h ...
- 堆heap和栈Stack(百科)
堆heap和栈Stack 在计算机领域,堆栈是一个不容忽视的概念,堆栈是两种数据结构.堆栈都是一种数据项按序排列的数据结构,只能在一端(称为栈顶(top))对数据项进行插入和删除.在单片机应用中,堆栈 ...
- (转)Java里的堆(heap)栈(stack)和方法区(method)(精华帖,多读读)
[color=red][/color]<一> 基础数据类型直接在栈空间分配, 方法的形式参数,直接在栈空间分配,当方法调用完成后从栈空间回收. 引用数据类型,需要用new来创建,既在栈 ...
- Java中堆(heap)和栈(stack)的区别
简单的说: Java把内存划分成两种:一种是栈内存,一种是堆内存. 在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配. 当在一段代码块定义一个变量时,Java就在栈中为这个变量分 ...
- 优先队列Priority Queue和堆Heap
对COMP20003中的Priority queue部分进行总结.图片来自于COMP20003 queue队列,顾名思义特点先进先出 priority queue优先队列,出来的顺序按照优先级prio ...
- python数据结构之堆(heap)
本篇学习内容为堆的性质.python实现插入与删除操作.堆复杂度表.python内置方法生成堆. 区分堆(heap)与栈(stack):堆与二叉树有关,像一堆金字塔型泥沙:而栈像一个直立垃圾桶,一列下 ...
- JVM 内存初学 堆(heap)、栈(stack)和方法区(method)
这两天看了一下深入浅出JVM这本书,推荐给高级的java程序员去看,对你了解JAVA的底层和运行机制有比较大的帮助.废话不想讲了.入主题:先了解具体的概念:JAVA的JVM的内存可分为3个区:堆(he ...
- 转:JVM 内存初学 (堆(heap)、栈(stack)和方法区(method) )
原文地址:JVM 内存初学 (堆(heap).栈(stack)和方法区(method) ) 博主推荐 深入浅出JVM 这本书 先了解具体的概念:JAVA的JVM的内存可分为3个区:堆(heap).栈( ...
随机推荐
- 用STS构建spring boot
操作步骤:1. 登录地址http://spring.io/tools 下载sts,spring-tool-suite-3.9.5.RELEASE-e4.8.0-win32-x86_64.zip2. 解 ...
- Java:ConcurrentLinkedQueue的实现原理分析
本文是作者原创,首发于InfoQ:http://www.infoq.com/cn/articles/ConcurrentLinkedQueue 1. 引言 在并发编程中我们有时候需要使用线程安全 ...
- lsf运行lsload命令显示“lsload: Host does not have a software license”
因为这个问题也是花费好长时间了,对一个小白的我来说真的挺激动的.下面说一下我的解决思路吧.不过造成这个问题也有很多种原因,需要对症下药. 我入手解决是从这个网站上看到同样的问题,然后通过一个个排除最后 ...
- Error resolving template [xxx], template might not exist or might not be exist
Springboot+thymeleaf+mybatis 抛Error resolving template [xxx], template might not exist的异常 原因是我们在pom. ...
- docker + mysql安装sonarqube
docker sonarqube地址:https://hub.docker.com/_/sonarqube docker mysql地址:https://hub.docker.com/_/mysql ...
- EC20指令测试
cat /dev/ttyUSB2 & echo -e "AT+CGMM\r\n" >/dev/ttyUSB2 //输出模块型号 echo -e "AT+ ...
- python生成exe文件
安装pyinstaller pyinstaller支持python2和python3 命令行安装:pip install pyinstaller pyinstaller --icon=duoguan. ...
- linux系统中使用socket直接发送ARP数据
这个重点是如这样创建socket: sock_send = socket ( PF_PACKET , SOCK_PACKET , htons ( ETH_P_ARP) ) ; 其后所有收发的数据都是 ...
- 交叉编译ffmpeg(hi3520d)
./configure \--prefix=/usr/local/ffmpeg-3520D \--cross-prefix=/opt/hisi-linux-nptl/arm-hisiv100-linu ...
- JavaScript自定义鼠标右键菜单
下面为JavaScript代码 window.onload = function () { //好友列表 var f = 0; //判断指定id的元素在页面中是否存在 if (document.get ...