TCN代码详解-Torch (误导纠正)
TCN代码详解-Torch (误导纠正)
1. 绪论
TCN网络由Shaojie Bai, J. Zico Kolter, Vladlen Koltun 三人于2018提出。对于序列预测而言,通常考虑循环神经网络结构,例如RNN、LSTM、GRU等。他们三个人的研究建议我们,对于某些序列预测(音频合成、字级语言建模和机器翻译),可以考虑使用卷积网络结构。
关于TCN基本构成和他们的原理有相当多的博客已经解释的很详细的了。总结一句话:TCN = 1D FCN + 因果卷积。下面的博客对因果卷积和孔洞卷积有详细的解释。
但是,包括TCN原文作者,上面这些博客对TCN网络结构的阐释无一例外都是使用下面这张图片。而问题在于,如果不熟悉Torch操作和基本的卷积网络操作,这张图片具有很大的误导性。
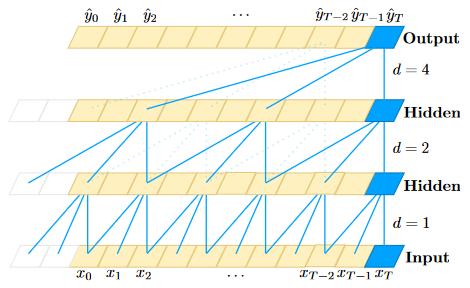
图1 膨胀因果卷积(膨胀因子d = 1,2,4,滤波器大小k = 3)
结合上图和上面列举的博客,我们可以大致理解到,TCN就是在序列上使用一维卷积核,沿着时间方向,按照空洞卷积的方式,依次计算。
例如,上图中,
- 第一个hidden层是由 \(d=1\) 的空洞卷积,卷积而来,退化为基本的一维卷积操作;
- 第二个hidden层是由 \(d=2\) 的空洞卷积,卷积而来,卷积每个值时隔开了一个值;
- 第二个hidden层是由 \(d=4\) 的空洞卷积,卷积而来,卷积每个值时隔开了三个值;
由此,上图中网络深度为3,每一层有1个卷积操作。
如果你也是这么理解,恭喜你,成功的被我带跑偏了。
2. TCN结构再次图解
上图中网络深度确实为3,但是每一层并不是只有1个卷积操作。这时候就要拿出原论文中第2个图了。
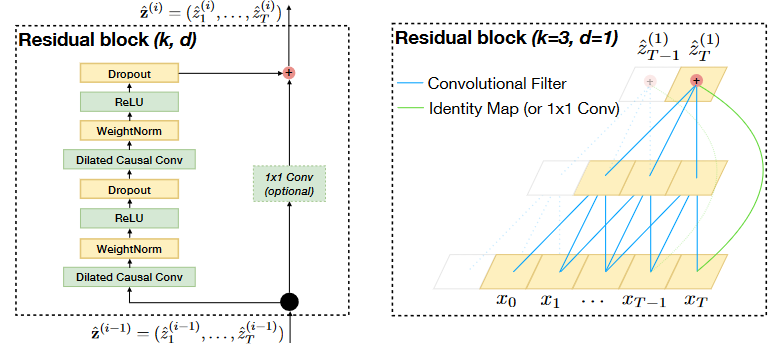
图2 TCN核心结构
这张图左边展示了TCN结构的核心,卷积+残差,作者把它命名为Residual block。我这里简称为block。
可以发现一个block有两个卷积操作和一个残差操作。因此,图1中每到下一层,都会有两个卷积操作和一个残差操作,并不是一个卷积操作。再次提醒,当 \(d=1\) 时,空洞卷积退化为普通的卷积,正如图2右图展示的。
因此,对于图1中由原始序列到第一层hidden的真实结构为:
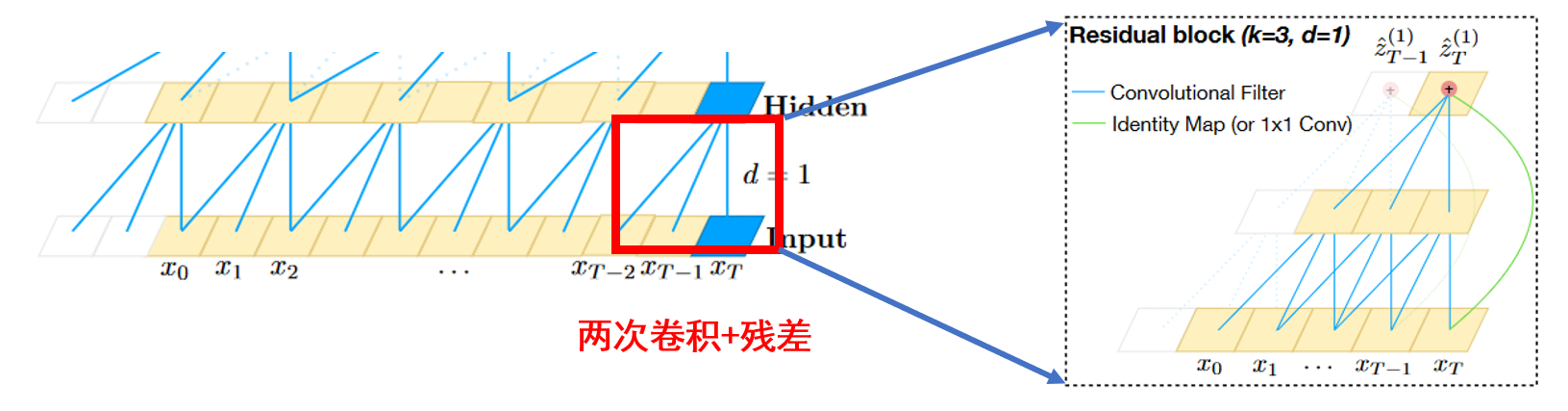
3. 结合原文的torch代码解释
很多博客再源代码解释时,基本都是一个模子,没有真正解释关键参数的含义,以及他们如何通过torch的tensor作用的。
预了解TCN结构,须明白原论文中作者描述的这样一句话:
Since a TCN’s receptive field depends on the network depth n as well as filter size k and dilation factor d, stabilization of deeper and larger TCNs becomes important.
翻译是:
由于TCN的感受野依赖于网络深度n、滤波器大小k和扩张因子d,因此更大更深的TCN的稳定变得很重要。
下面结合作者源代码,对这三个参数解释。
3.1 TemporalConvNet
网络深度n就是有多少个block,反应到源代码的变量为num_channels的长度,即 \(len(num_channels)\)。
class TemporalConvNet(nn.Module):
def __init__(self, num_inputs, num_channels, kernel_size=2, dropout=0.2):
super(TemporalConvNet, self).__init__()
"""
:param num_inputs: int, 输入通道数或者特征数
:param num_channels: list, 每层的hidden_channel数. 例如[5,12,3], 代表有3个block,
block1的输出channel数量为5;
block2的输出channel数量为12;
block3的输出channel数量为3.
:param kernel_size: int, 卷积核尺寸
:param dropout: float, drop_out比率
"""
layers = []
num_levels = len(num_channels)
# 可见,如果num_channels=[5,12,3],那么
# block1的dilation_size=1
# block2的dilation_size=2
# block3的dilation_size=4
for i in range(num_levels):
dilation_size = 2 ** i
in_channels = num_inputs if i == 0 else num_channels[i-1]
out_channels = num_channels[i]
layers += [TemporalBlock(in_channels, out_channels, kernel_size, stride=1, dilation=dilation_size,
padding=(kernel_size-1) * dilation_size, dropout=dropout)]
self.network = nn.Sequential(*layers)
def forward(self, x):
return self.network(x)
3.2 TemporalBlock
参数dilation的解释,结合上面和下面的代码。
class TemporalBlock(nn.Module):
def __init__(self, n_inputs, n_outputs, kernel_size, stride, dilation, padding, dropout=0.2):
super(TemporalBlock, self).__init__()
"""
构成TCN的核心Block, 原作者在图中成为Residual block, 是因为它存在残差连接.
但注意, 这个模块包含了2个Conv1d.
:param n_inputs: int, 输入通道数或者特征数
:param n_outputs: int, 输出通道数或者特征数
:param kernel_size: int, 卷积核尺寸
:param stride: int, 步长, 在TCN固定为1
:param dilation: int, 膨胀系数. 与这个Residual block(或者说, 隐藏层)所在的层数有关系.
例如, 如果这个Residual block在第1层, dilation = 2**0 = 1;
如果这个Residual block在第2层, dilation = 2**1 = 2;
如果这个Residual block在第3层, dilation = 2**2 = 4;
如果这个Residual block在第4层, dilation = 2**3 = 8 ......
:param padding: int, 填充系数. 与kernel_size和dilation有关.
:param dropout: float, dropout比率
"""
self.conv1 = weight_norm(nn.Conv1d(n_inputs, n_outputs, kernel_size,
stride=stride, padding=padding, dilation=dilation))
# 因为 padding 的时候, 在序列的左边和右边都有填充, 所以要裁剪
self.chomp1 = Chomp1d(padding)
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(dropout)
self.conv2 = weight_norm(nn.Conv1d(n_outputs, n_outputs, kernel_size,
stride=stride, padding=padding, dilation=dilation))
self.chomp2 = Chomp1d(padding)
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(dropout)
self.net = nn.Sequential(self.conv1, self.chomp1, self.relu1, self.dropout1,
self.conv2, self.chomp2, self.relu2, self.dropout2)
# 1×1的卷积. 只有在进入Residual block的通道数与出Residual block的通道数不一样时使用.
# 一般都会不一样, 除非num_channels这个里面的数, 与num_inputs相等. 例如[5,5,5], 并且num_inputs也是5
self.downsample = nn.Conv1d(n_inputs, n_outputs, 1) if n_inputs != n_outputs else None
# 在整个Residual block中有非线性的激活. 这个容易忽略!
self.relu = nn.ReLU()
self.init_weights()
def init_weights(self):
self.conv1.weight.data.normal_(0, 0.01)
self.conv2.weight.data.normal_(0, 0.01)
if self.downsample is not None:
self.downsample.weight.data.normal_(0, 0.01)
def forward(self, x):
out = self.net(x)
res = x if self.downsample is None else self.downsample(x)
return self.relu(out + res)
3.3 Chomp1d
裁剪模块。这里注意,padding的时候对数据列首尾都添加了,torch官方解释如下:
padding controls the amount of padding applied to the input. It can be either a string {‘valid’, ‘same’} or a tuple of ints giving the amount of implicit padding applied on both sides.
注意这里是both sides。例如,还是上述代码中的例子,kernel_size = 3,在第一层(对于第一个block),padding = 2。对于长度为20的序列,先padding,长度为\(20+2\times2=24\),再卷积,长度为\((24-3)+1=22\)。所以要裁掉,保证输出序列与输入序列相等。
class Chomp1d(nn.Module):
def __init__(self, chomp_size):
super(Chomp1d, self).__init__()
self.chomp_size = chomp_size
def forward(self, x):
return x[:, :, :-self.chomp_size].contiguous()
4. 验证TCN的输入输出
根据上述代码的解释和理解,我们可以方便的呃验证其输入和输出。
# 输入27个通道,或者特征
# 构建1层的TCN,最后输出一个通道,或者特征
model2 = TemporalConvNet(num_inputs=27, num_channels=[32,16,4,1], kernel_size=3, dropout=0.3)
import torch
# 检测输出
with torch.no_grad():
# 模型输入一定是 (batch_size, channels, length)
model2.eval()
print(model2(torch.randn(16,27,20)).shape)
打印结果为(16, 1, 20) 。通道数降为1。输入序列长度20, 输出序列长度也是20。
TCN代码详解-Torch (误导纠正)的更多相关文章
- Github-jcjohnson/torch-rnn代码详解
Github-jcjohnson/torch-rnn代码详解 zoerywzhou@gmail.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2016-3- ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- ASP.NET MVC 5 学习教程:生成的代码详解
原文 ASP.NET MVC 5 学习教程:生成的代码详解 起飞网 ASP.NET MVC 5 学习教程目录: 添加控制器 添加视图 修改视图和布局页 控制器传递数据给视图 添加模型 创建连接字符串 ...
- Github-karpathy/char-rnn代码详解
Github-karpathy/char-rnn代码详解 zoerywzhou@gmail.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2016-1-10 ...
- 代码详解:TensorFlow Core带你探索深度神经网络“黑匣子”
来源商业新知网,原标题:代码详解:TensorFlow Core带你探索深度神经网络“黑匣子” 想学TensorFlow?先从低阶API开始吧~某种程度而言,它能够帮助我们更好地理解Tensorflo ...
- JAVA类与类之间的全部关系简述+代码详解
本文转自: https://blog.csdn.net/wq6ylg08/article/details/81092056类和类之间关系包括了 is a,has a, use a三种关系(1)is a ...
- Java中String的intern方法,javap&cfr.jar反编译,javap反编译后二进制指令代码详解,Java8常量池的位置
一个例子 public class TestString{ public static void main(String[] args){ String a = "a"; Stri ...
- Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测
Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测 2017年12月13日 17:39:11 机器之心V 阅读数:5931 近日,Artur Suilin 等人发布了 Kaggl ...
- 基础 | batchnorm原理及代码详解
https://blog.csdn.net/qq_25737169/article/details/79048516 https://www.cnblogs.com/bonelee/p/8528722 ...
- 非极大值抑制(NMS,Non-Maximum Suppression)的原理与代码详解
1.NMS的原理 NMS(Non-Maximum Suppression)算法本质是搜索局部极大值,抑制非极大值元素.NMS就是需要根据score矩阵和region的坐标信息,从中找到置信度比较高的b ...
随机推荐
- KingbaseES中的参数查看与修改
KingbaseES数据库的配置参数都在kingbase.conf文件中,这些参数有些是直接修改就可以生效,有些需要重启数据库才能生效,而有些根本就不能修改.数据库把这些参数分为以下几类: inter ...
- 谷歌MapReduce经典论文翻译(中英对照)
MapReduce: Simplified Data Processing on Large Clusters(MapReduce: 简化大型集群下的数据处理) 作者:Jeffrey Dean and ...
- 采用docker方式安装ElastAlert,图形化配置告警规则----具体内容有删改,仅供查看
1.创建几个文件夹保存ElastAlert相关配置信息,用来挂载到容器中使用 2.编写核心配置,创建 ${ELASTALERT}/config/config.yaml用来存储核心配置: 3.Elast ...
- 自定义mapping与常见参数
PUT test { "mappings": { "dynamic": true, "properties": { "firstn ...
- Keepalived + Nginx 实现高可用 Web 负载均衡
一.Keepalived 简要介绍 Keepalived 是一种高性能的服务器高可用或热备解决方案, Keepalived 可以用来防止服务器单点故障的发生,通过配合 Nginx 可以实现 web 前 ...
- 我的 Kafka 旅程 - Producer
原理阐述 Producer生产者是数据的入口,它先将数据序列化后于内存的不同队列中,它用push模式再将内存中的数据发送到服务端的broker,以追加的方式到各自分区中存储.生产者端有两大线程,以先后 ...
- 银河麒麟安装node,mysql,forever环境
这就是国产银河系统的界面,测试版本是麒麟V10 链接: https://pan.baidu.com/s/1_-ICBkgSZPKvmcdy1nVxVg 提取码: xhep 一.传输文件 cd /hom ...
- 自定义映射resultMap
resultMap处理字段和属性的映射关系 如果字段名与实体类中的属性名不一致,该如何处理映射关系? 第一种方法:为查询的字段设置别名,和属性名保持一致 下面是实体类中的属性名: private In ...
- 矩阵顺时针打印(C++)(? 为什么不能AC,9度1391)
#include <iostream> #include <fstream> using namespace std; int a[1000][1000]; void prin ...
- 小程序uni-app发起网络异步请求
// uni.request({ // url: 'api/boxs/search', // // 使用监听函数防止this指向改变 // success: res => { // // 判断是 ...