ConvFormer: Closing the Gap Between CNN and Vision Transformers概述
0.前言
相关资料:
github
论文解读
论文基本信息:
发表时间:arxiv2022(2022.9.16)
1.针对的问题
CNN虽然效率更高,能够建模局部关系,易于训练,收敛速度快。然而,它们大多采用静态权重,限制了它们的表示能力和通用性。而全局注意力机制虽然提供了动态权重,能从每个实例预测,从而在大数据集中获得强大的性能和鲁棒性,但是计算代价太高。
2.主要贡献
•提出了一种新颖的注意力机制MCA,该机制具有动态性,针对不同的分辨率模式采用了不同大小的卷积核。
•基于MCA,设计了一个综合了ViT和CNN优点的通用CNN骨干网ConvFormer。
•对多个视觉任务进行了广泛的实验,包括图像分类、目标检测和语义分割,以评估ConvFormer。实验结果表明,ConvFormer实现了最先进的性能。
3.方法
本文提出的方法比较简单。MCA的两个关键组成部分是多级特征融合和门控机制。
多级特征融合能够捕捉不同分辨率下输入图像的不同模式,结合多尺度特征图。
门控机制进行特征重校准,学习选择性地强调含信息量大的特征,抑制非平凡特征。
MCA框架如下:
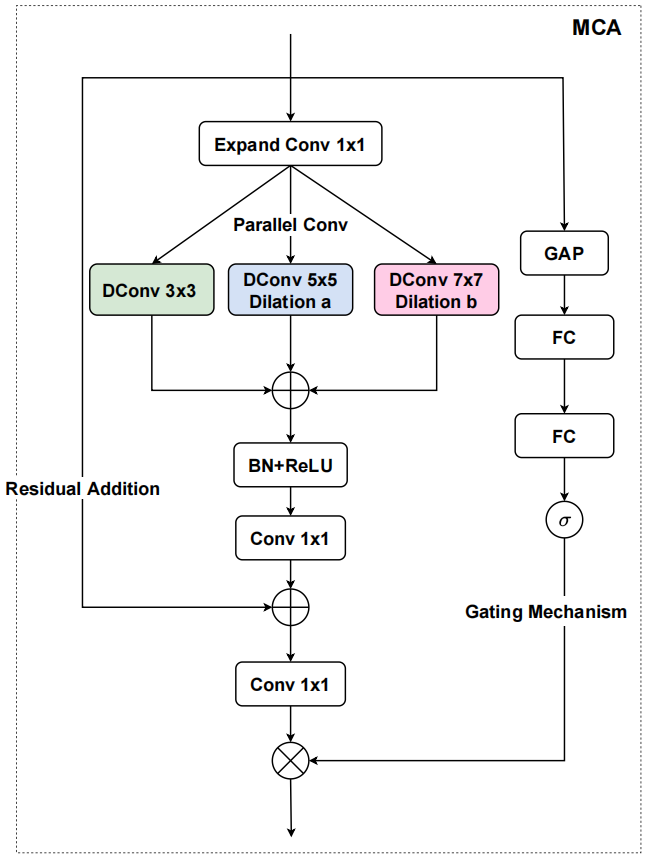
设输入为x,先用一个1×1卷积层,将通道数量扩展N倍。然后,通过3×3,5×5,7 ×7深度卷积并行学习多尺度特征,这里,5×5和7 ×7的是膨胀深度卷积,膨胀率分别为2和3,以获得更大的感受野。然后输入BatchNorm和ReLU来防止过拟合。接下来,为了应用残差连接进行更好的优化,通过1×1的卷积层来减少通道数量到与原始输入x一致,得到x'。
对于门控机制,首先使用全局平均池化层获取全局信息,然后是连续的两个全连接层。最后,利用sigmoid函数计算注意力向量Attn。
最后,将x通过1×1卷积的输出与Attn相乘得到最终输出。
ConvFormer总体框架如下:
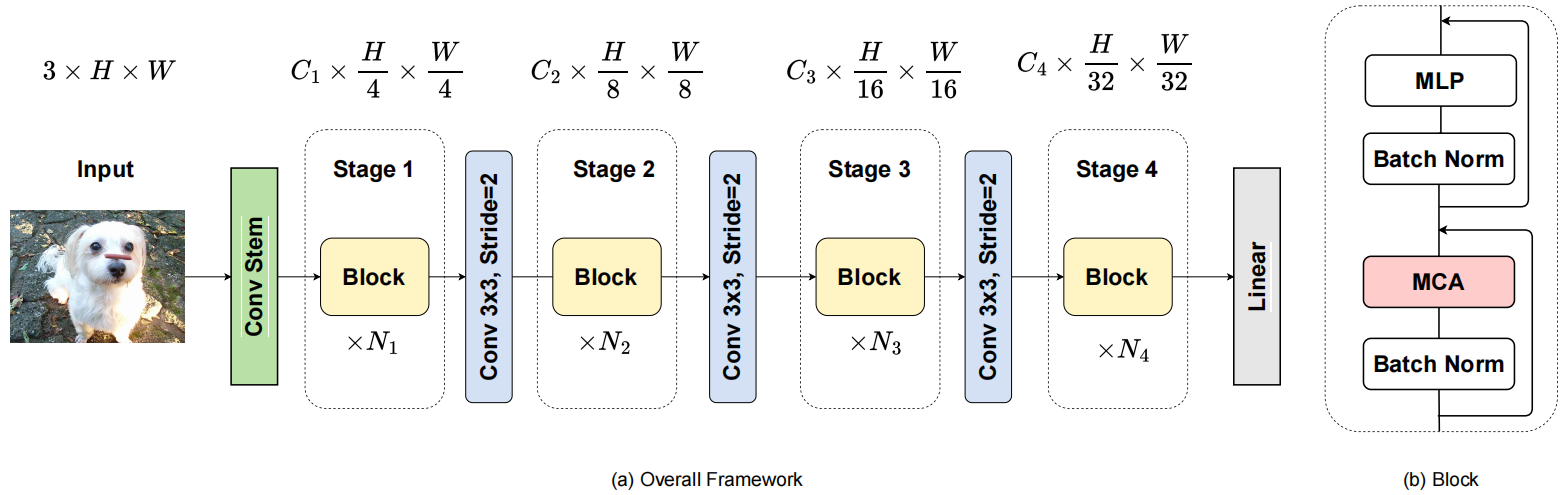
输入图片首先输入一个卷积stem,该模块由一个stride为2的7 × 7卷积层,一个stride为1的3×3卷积层和一个stride为2的不重叠的2×2卷积层组成。这样,生成的输入特征空间大小为 H/4×W/4。
表示X∈RN×C1× H/4× W/4为输入特征,N为batch大小,C1为通道数。然后,将输入的特征输入重复的ConvFormer,每个ConvFormer由两个子块组成。具体来说,第一个子块的主要组件包括MCA和BatchNorm模块,第二个子块由两个全连接的层和一个非线性激活GELU组成,也就是一个MLP。
4.补充
作者在论文中提到注意力可以分为四种基本类别:通道注意力,自适应地重新校准每个通道的权重,以关注不同的对象。时序注意力强调捕捉帧间的交互作用并决定何时进行注意力。分支注意力是一种动态的分支选择机制,使得信息可以在不同分支间流动。空间注意力产生注意力掩膜,自适应地选择重要的空间区域。而MCA就是采用通道注意力机制。
ConvFormer: Closing the Gap Between CNN and Vision Transformers概述的更多相关文章
- How Do Vision Transformers Work?[2202.06709] - 论文研读系列(2) 个人笔记
[论文简析]How Do Vision Transformers Work?[2202.06709] 论文题目:How Do Vision Transformers Work? 论文地址:http:/ ...
- 论文笔记:DeepFace: Closing the Gap to Human-Level Performance in Face Verification
2014 CVPR Facebook AI研究院 简单介绍 人脸识别中,通常经过四个步骤,检测,对齐(校正),表示,分类 论文主要阐述了在对齐和表示这两个步骤上提出了新的方法,模型的表现超越了前人的工 ...
- Awesome Deep Vision
Awesome Deep Vision A curated list of deep learning resources for computer vision, inspired by awes ...
- ICCV2021 | Tokens-to-Token ViT:在ImageNet上从零训练Vision Transformer
前言 本文介绍一种新的tokens-to-token Vision Transformer(T2T-ViT),T2T-ViT将原始ViT的参数数量和MAC减少了一半,同时在ImageNet上从 ...
- 《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》论文笔记
论文题目:<Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition> 论文作者:Qibin ...
- Deep Learning模型之:CNN卷积神经网络(一)深度解析CNN
http://m.blog.csdn.net/blog/wu010555688/24487301 本文整理了网上几位大牛的博客,详细地讲解了CNN的基础结构与核心思想,欢迎交流. [1]Deep le ...
- 深度解析CNN
[1]Deep learning简介 [2]Deep Learning训练过程 [3]Deep Learning模型之:CNN卷积神经网络推导和实现 [4]Deep Learning模型之:CNN的反 ...
- cnn(卷积神经网络)比较系统的讲解
本文整理了网上几位大牛的博客,详细地讲解了CNN的基础结构与核心思想,欢迎交流. [1]Deep learning简介 [2]Deep Learning训练过程 [3]Deep Learning模型之 ...
- DeepFace--Facebook的人脸识别(转)
DeepFace基本框架 人脸识别的基本流程是: detect -> aligh -> represent -> classify 人脸对齐流程 分为如下几步: a. 人脸检测,使用 ...
- face recognition[翻译][深度学习理解人脸]
本文译自<Deep learning for understanding faces: Machines may be just as good, or better, than humans& ...
随机推荐
- 连接MySql时提示%d format: a number is required, not str
代码: sql = "select * from appelementinfo" coon = pymysql.connect(user='root', password='', ...
- Jmeter 之在linux中监控Memory、CPU、I/O资源等操作方法
在做性能测试时,单纯的只看响应时间.错误率.中间值远远不够的,有时需要监控服务cpu.内存等指标来判断影响性能的瓶颈在哪. 操作步骤: 一.Linux下配置jmeter环境 1.在linux环境下安装 ...
- Wireshark网卡无法找到或没有显示的问题
问题背景 最近在处理公司内网域名解析的问题,发现配置好一个新域名在内网环境可以正常解析成内网IP,但使用深信服VPN却无法正常解析,并且其他域名使用深信服VPN可以正常解析,所以参考<内网域名解 ...
- YMOI 2019.6.8
题解 YMOI 2019.6.8 前言 第二回考试,承让拿了第一次rank1,(●ˇ∀ˇ●) 题解 这次考试总体发挥比较好,每一道题都尽可能得取得了所能及的所有分.虽然多少还是有失误,不过在所难免.保 ...
- 【AI编译器原理】系列来啦!我们要从入门到放弃!
随着深度学习的应用场景的不断泛化,深度学习计算任务也需要部署在不同的计算设备和硬件架构上:同时,实际部署或训练场景对性能往往也有着更为激进的要求,例如针对硬件特点定制计算代码. 这些需求在通用的AI框 ...
- python连接kafka-2.0
import sysimport timeimport osimport jsonimport vertica_pythonimport loggingimport pykafkafrom pykaf ...
- AIGC 很火,想微调个自己的模型试试看?(不是卖课的)
去年,我们发布过一篇关于 DreamBooth 编程马拉松的活动通知,获得了全球社区的广泛关注和参与,中国社区的成员们也对这个活动有非常高的热情.同时我们也收到了后台留言反馈说参与活动需要使用的 Go ...
- Flutter踩坑日记,自己挖的坑,哭着也要走出来。
1. 系统运行缓慢,疯狂点击右上角小X,再次启动后Emulator启动黑屏,关机重启也不好使,其他 Emulator也无法使用. 执行以下步骤: 第一检查内存是否够用 啊 不够用了 那么 [解决方法 ...
- saas解决redis数据库分离的一种方案
package com.xf.config; import java.util.HashMap; import java.util.Map; import java.util.Set; import ...
- Kubernetes环境cert-manager部署与应用
本作品由Galen Suen采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可.由原作者转载自个人站点. 概述 本文用于整理基于Kubernetes环境的cert-manager部 ...