[ElasticSearch] ES集群状态由非正常状态(red)恢复为正常状态(green)的思路与实践
1 场景描述
1.1 资源与原规划
三台主机组成ES集群的规划:
集群名: xxx_elastic
- 172.15.3.7 es1 master
- 172.15.3.8 es2 (非master)
- 172.15.3.9 es3 (非master)
1.2 原集群状态

https://172.15.3.7:9200/_cluster/health?pretty
{
"cluster_name" : "xxx_elastic",
"status" : "red",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 492,
"active_shards" : 553,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 95,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 85.3395061728395
}
集群的异常之处: number_of_nodes / cluster status / unassigned_shards
- number_of_nodes: 3
(正常情况下,应该是: 3) - cluster status: red
(正常情况下,应该是: green)
red: 非健康状态; 部分的分片可用,表明分片有一部分损坏。一般情况下,表明存在 unassigned 的索引分片(shards:碎片,分片)。
此时执行查询部分数据仍然可以查到,遇到这种情况,还是赶快解决比较好;
这种情况Elasticsearch集群至少一个主分片(以及它的全部副本)都在缺失中。
这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
yellow: 亚健康状态;基本的分片可用,但是备份不可用(或者是没有备份);
这种情况Elasticsearch集群所有的主分片已经分片了,但至少还有一个副本是缺失的。
不会有数据丢失,所以搜索结果依然是完整的。
不过,你的高可用性在某种程度上被弱化。
如果更多的分片消失,就会丢数据了。
把 yellow 想象成一个需要及时调查的警告。
green: 最健康状态;说明所有的分片包括备份都可用; 这种情况Elasticsearch集群所有的主分片和副本分片都已分配, Elasticsearch集群是 100% 可用的。
- unassigned_shards: 95
(正常情况下,应该是: 0)
unssigned 即 未分配副本分片的问题
2 解决思路
以消除 unassigned_shards:0 为主要目标
step1 确保集群节点数达到理论节点数
即 恢复全部ES节点合为1个ES集群
(这能大幅度,乃至完全地消除 unassigned_shards 的数量)
本操作完成后,unsigned状态的索引碎片(shards)由95个降低为25个
- 修正为正确的ES节点名称(node.name)
vi /etc/elasticsearch/elasticsearch.yml
#
# Use a descriptive name for the node:
#
node.name: es3
- 确保集群所有节点: 启动状态 + 开机自启
[CentOS6]
[root@es1 ~]# chkconfig elasticsearch on (开机自启)
[root@es3 ~]# service elasticsearch start (启动ES服务)
[CentOS7]
[root@es1 ~]# systemctl enable elasticsearch (开机自启)
[root@es3 ~]# systemctl start elasticsearch (启动ES服务)
- 新节点加入集群
以 配置丢失的节点node8(es2)加入目标集群 为例
elasticsearch.yml的配置项 推荐文献: elasticsearch配置
[node7 / node8 / node9]
vi /etc/elasticsearch/elasticsearch.yml
# 配置向master节点单播通信的IP(默认通信端口为9200)
# 单播配置下,节点向指定的主机发送单播请求
# 默认配置中的主机对应的对外通信端口为9200;若该主机对外通信端口非9200端口时,需具体指定
# 一般可只填写master节点
discovery.zen.ping.unicast.hosts: ["172.15.3.7"]
# 设置master的个数
discovery.zen.minimum_master_nodes: 1
transport.tcp.port: 9300
[node8 / node9] 取消 node8 / node9 节点的默认(master)配置;
vi /etc/elasticsearch/elasticsearch.yml
node.master: false
step2 消除剩余 unassigned 的 索引分片(shards)
red状态的索引,要么reroute,要么删除之
[浏览器] https://172.15.3.7:9200/_nodes?pretty
找到node8节点的唯一主机标识 jprFXcCqRVGCSNU3M02ZbQ
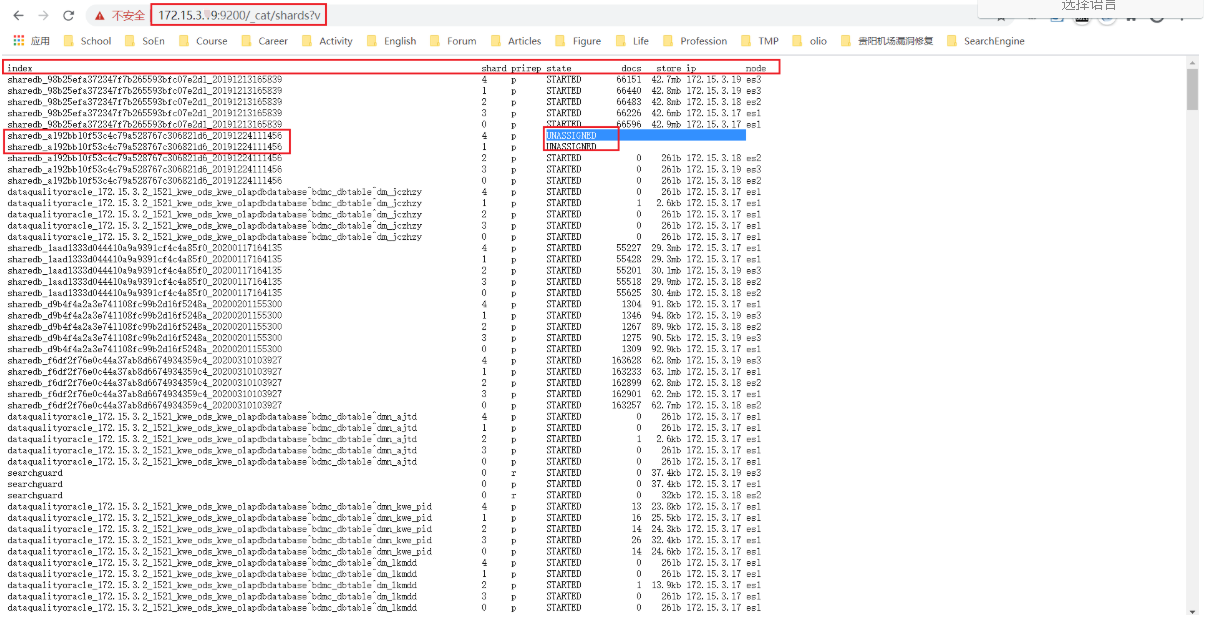
[浏览器] https://172.15.3.7:9200/_cat/shards?v
查找 UNASSIGNED 的索引
或者
[root@es1 ~]# curl --insecure -u admin:admin "https://172.15.3.9:9200/_cat/shards" | grep UNASSIGNED
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
sharedb_bae200fe08354928976fd075bb944a5e_20191223160406 1 p UNASSIGNED
sharedb_bae200fe08354928976fd075bb944a5e_20191223160406 3 p UNASSIGNED
sharedb_01d4aa88707448dc9010030249a0b8ab_20200401151836 p UNASSIGNED
...
[root@es1]# curl -XDELETE -u admin:admin --insecure "https://172.15.3.7:9200/sharedb_bae200fe08354928976fd075bb944a5e_20191223160406 "
{"acknowledged":true}
(逐次删除状态为red的索引, sharedb_bae200fe08354928976fd075bb944a5e_20191223160406 为索引号)
Over~~
{
"cluster_name" : "xxx_elastic",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 542,
"active_shards" : 609,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
补充:ES的安装/配置 文件的一般路径
ps -ef | grep elasticsearch
/etc/elasticsearch/...
/etc/elasticsearch/elasticsearch.yml
/usr/share/elasticsearch/...
/usr/share/elasticsearch/logs/...
/usr/share/elasticsearch/plugins/search-guard-6/tools/hash.sh
/usr/share/elasticsearch/plugins/search-guard-6/tools/sgadmin.sh
/usr/share/elasticsearch/plugins/search-guard-6/sgconfig/sg_internal_users.yml
/opt/elsatic-6.4.1/...
/opt/elsatic-6.4.1/configure_file/elasticsearch.yml
/home/elasticsearch/...
X 文献
- [ElasticSearch]常用URL路径 - 推荐/博客园
- 记一次elasticsearch错误(SearchPhaseExecutionException: all shards failed) - 参考/博客园
- elasticsearch配置 - 博客园
[ElasticSearch] ES集群状态由非正常状态(red)恢复为正常状态(green)的思路与实践的更多相关文章
- elasticsearch(es) 集群恢复触发配置(Local Gateway参数)
elasticsearch(es) 集群恢复触发配置(Local Gateway) 当你集群重启时,几个配置项影响你的分片恢复的表现. 首先,我们需要明白如果什么也没配置将会发生什么. 想象一下假设你 ...
- 解决ES集群状态异常教程(存在UNASSIGNED)
解决ES集群状态异常教程(存在UNASSIGNED)_百度经验 https://jingyan.baidu.com/article/9158e00013f787a255122843.html
- elasticSearch中集群状态的guan'l
es中集群出现上面的问题一般是磁盘空间不够引起的,就是node节点所在的磁盘空间不足引起的 es整个集群放在c盘,都快满了 说明es的磁盘已经快被使用完了,我们可以临时更新下磁盘空间大小 修改 ES分 ...
- ELK之 elasticsearch ES集群 head安装
最近项目用到 jenkins ELK 也在一次重新学习了一次 jenkins 不用说了 玩得就是 插件 + base---shell , ELK 这几年最流得log收集平台,当然不止 ...
- 【ELK】【docker】6.Elasticsearch 集群启动多节点 + 解决ES节点集群状态为yellow
本章其实是ELK第二章的插入章节. 本章ES集群的多节点是docker启动在同一个虚拟机上 ====================================================== ...
- ubuntu12.04+Elasticsearch2.3.3伪分布式配置,集群状态分片调整
目录 [TOC] 1.什么是Elashticsearch 1.1 Elashticsearch介绍 Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎.能够快速搜索数 ...
- 线上 ELK 集群健康值 red 状态问题排查与解决
之前一直运行正常的数据分析平台,最近一段时间没有注意发现日志索引数据一直未生成,大概持续了n多天,当前状态: 单台机器, Elasticsearch(下面称ES)单节点(空集群),1000+shrad ...
- 磁盘空间引起ES集群shard unassigned的处理过程
1.问题描述 早上醒来发现手机有很多ES状态为red的告警,集群就前几天加了几个每天有十多亿记录的业务,当时估算过磁盘容量,应该是没有问题的,但是现在集群状态突然变成red了,这就有点懵逼了. 2.查 ...
- Kubernetes 搭建 ES 集群(存储使用 cephfs)
一.集群规划 使用 cephfs 实现分布式存储和数据持久化 ES 集群的 master 节点至少需要三个,防止脑裂. 由于 master 在配置过程中需要保证主机名固定和唯一,所以搭建 master ...
- Kubernetes 搭建 ES 集群(存储使用 local pv)
一.集群规划 由于当前环境中没有分布式存储,所以只能使用本地 PV 的方式来实现数据持久化. ES 集群的 master 节点至少需要三个,防止脑裂. 由于 master 在配置过程中需要保证主机名固 ...
随机推荐
- 英国延长 UKCA 标记截止日期
政府于 2022 年 11 月 14 日宣布,企业将有 2 年的时间来应用新的 UKCA 产品标记.在 2024 年 12 月 31 日之前,企业可以选择使用 UKCA 或 CE 标志,之后企业只能使 ...
- Long类型转换为IP String
package com.barry.iputil.util; public class IPFormat { public static String toIPStr(Long LongIP) { i ...
- 图像处理|Matlab
图像处理 | Matlab 参考博文: 图像处理-平滑滤波 图像去噪-加性噪声(高斯/椒盐)
- 自学JavaDay01
1.Java的特性和优势 简单性 面向对象 可移植性 高性能 分布式 动态性 多线程 安全性 健壮性 2.Java三大版本 JavaSE:标准版(桌面程序,控制台开发......) JavaME:嵌入 ...
- SQLServer数据库执行时间
with kk AS( SELECT TOP 2000 total_worker_time/1000 AS [总消耗CPU 时间(ms)],execution_count [运行次数], qs.tot ...
- ctype.h系列的字符函数
C有一系列专门处理字符的函数,ctype.h头文件包含了这些函数的原型.这些函数接受一个字符作为参数,如果该字符属于某特殊的类别,就返回一个非零值(真):否则返回0(假).这个头文件在判断特定字符类型 ...
- 九九乘法表打印记一次al面试
for (int i = 1; i <= 9; i++) { for (int j = 1; j <= i; j++) { System.out.print(i + "x&quo ...
- python 连接蓝牙设备并接收数据
python 连接蓝牙设备 原始内容 # %% from binascii import hexlify import struct from bluepy.btle import Scanner, ...
- 《Unix/Linux系统编程》第九周学习笔记
<Unix/Linux系统编程>第九周学习笔记 信号和中断 中断"是从I/O设备或协处理器发送到CPU的外部请求,它将CPU从正常执行转移 到中断处理.与发送给CPU的中断请求一 ...
- python print 一个进度条
import time scale=100 print("执行开始".center(scale+28,'-')) start = time.perf_counter() for i ...