pyspark 中的rdd api 编码练习
1,使用pyspark 的rdd api 进行了数据文件的处理,包括构建RDD, 统计分析RDD ,从文件中读取数据RDD,从文件中构建 rdd的模式shema.
然后通过模式,从rdd中生成dataframe。
2,代码
'''
构建sparkSession 和练习数据(RDD 和 KV rdd)
'''
spark = SparkSession.builder.appName("rdd_api_test") \
.master("local[2]") \
.getOrCreate()
sc = spark.sparkContext
rdd1 = sc.parallelize([1, 5, 60, 'a', 9, 'c', 4, 'z', 'f'])
rdd2 = sc.parallelize([('a', 6),
('a', 1),
('b', 2),
('c', 5),
('c', 8),
('c', 11)]) '''
查看rdd元素 , 元素个数, KV对RDD中key的出现次数, 分区个数等常用api
'''
print(rdd2.collect())
print (rdd2.take(2))
print('amount of elements:', rdd2.count())
print('RDD count of key:', rdd2.countByKey())
print('RDD output as map:', rdd2.collectAsMap())
print('RDD number of partitions:', rdd2.getNumPartitions()) '''
数值型rdd ,常用统计函数, 最小,最大 ,平均 , 标准差,方差
'''
rdd5 = sc.parallelize(range(100))
print('RDD Min:', rdd5.min()) # rdd 最小值
print('RDD Max:', rdd5.max())
print('RDD Mean:', rdd5.mean())
print('RDD Standard deviation:', rdd5.stdev())
print('RDD Variance:', rdd5.variance()) '''
从文件读取数据,并且去掉第一行列名,进行显示
数据源:nba.csv
'''
full_csv = sc.textFile('nba.csv')
header = full_csv.first()
print(full_csv.filter(lambda line: line != header).take(4)) # 去掉头行后,看效果 '''
从文档中读出文件头部,设置rdd模式,然后把RDD转化为df
数据源:本地文件:customerheaders.txt
数据样例:
id:string
full_name:string
...
'''
from pyspark.sql.types import IntegerType, DoubleType, StringType, StructType, StructField header_list = sc.textFile('customerheaders.txt') \
.map(lambda line: line.split(":")).collect() # 返回数组,元素为[id string]... def strToType(str): # string 映射到 DataType
if str == 'int':
return IntegerType()
elif str == 'double':
return DoubleType()
else:
return StringType() schema = StructType([StructField(t[0], strToType(t[1]), True) for t in header_list]) # 列表构造器 构造 StructType
for item in schema:
print(item) '''
对原始文件rdd中每一行进行规范化处理
数据举例:
7,Mohandas MacRierie,mmacrierie0@xrea.com,11/24/1990,Fliptune,-7.1309871,111.591546,
254,Rita Slany,rslany1@ucla.edu,8/7/1961,Yodoo,48.7068855,2.3371075,
'''
customers_rdd = sc.textFile('customers.txt') '''
一行字符串的解析函数
逻辑:
1,取出
'''
def parseLine(line):
tokens = zip(line.split(","), header_list) # 打包为元组的列表, [(7, [id string]),(Mohandas, [name string]), ... ]
parsed_tokens = []
for token in tokens:
token_type = token[1][1] # 取到数据的类型,然后转化该类型,并放入parsed_tokens
print('token_type = ', token_type)
if token_type == 'double':
parsed_tokens.append(float(token[0]))
elif token_type == 'int':
parsed_tokens.append(int(token[0]))
else:
parsed_tokens.append(token[0])
return parsed_tokens records = customers_rdd.map(parseLine) # 把文本字符串根据模式中对应的类型,转化为对象 for item in records.take(4):
print(item) df = spark.createDataFrame(records, schema) # rdd --> df
print (df) '''
其他一些API介绍:
rdd.foreach([FUNCTION]): 对每个元素执行函数
rdd.groupBy([CRITERA]): 分组聚合 like: ('a', 1) ('b',2) ('a', 3) --> ('a',Iterable(1,3)) ('b', 2)
rdd.subtract(rdd2): 做差集计算,元素在rdd中出现,没有在rdd2中出现
rdd.subtractByKey(rdd2): 同上,适用于KV rdd
rdd.sortBy([FUNCTION]): 自定义RDD元素排序
rdd.sortByKey(): 按照key 进行排序,其中key的类型必须实现了排序逻辑
rdd.join(rdd2): like : ('a', 1) ('b',2) ('a', 3) --> ('a',(1,3)) ('b', 2) '''
运行结果:
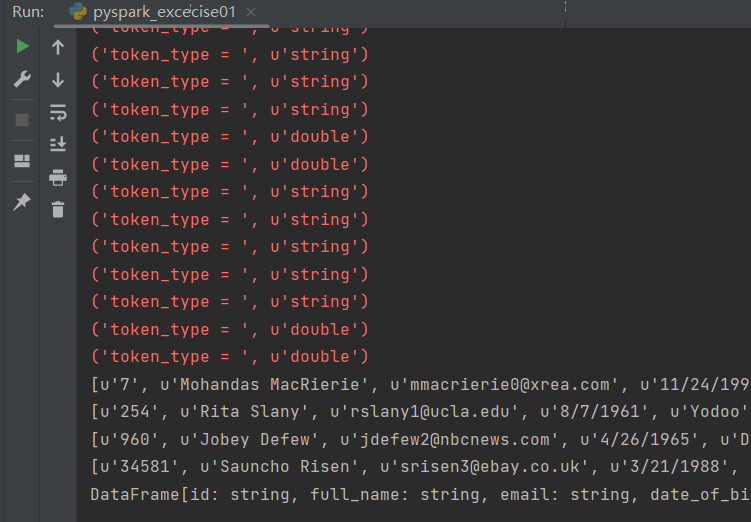
pyspark 中的rdd api 编码练习的更多相关文章
- spark 中的RDD编程 -以下基于Java api
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- Entity Framework 实体框架的形成之旅--Code First模式中使用 Fluent API 配置(6)
在前面的随笔<Entity Framework 实体框架的形成之旅--Code First的框架设计(5)>里介绍了基于Code First模式的实体框架的经验,这种方式自动处理出来的模式 ...
- ASP.NET MVC4中调用WEB API的四个方法
http://tech.it168.com/a2012/0606/1357/000001357231_all.shtml [IT168技术]当今的软件开发中,设计软件的服务并将其通过网络对外发布,让各 ...
- 【Socket编程】Java中网络相关API的应用
Java中网络相关API的应用 一.InetAddress类 InetAddress类用于标识网络上的硬件资源,表示互联网协议(IP)地址. InetAddress类没有构造方法,所以不能直接new出 ...
- [Spark][Python][DataFrame][RDD]DataFrame中抽取RDD例子
[Spark][Python][DataFrame][RDD]DataFrame中抽取RDD例子 sqlContext = HiveContext(sc) peopleDF = sqlContext. ...
- Spark RDD API扩展开发
原文链接: Spark RDD API扩展开发(1) Spark RDD API扩展开发(2):自定义RDD 我们都知道,Apache Spark内置了很多操作数据的API.但是很多时候,当我们在现实 ...
- Spark RDD API详解之:Map和Reduce
RDD是什么? RDD是Spark中的抽象数据结构类型,任何数据在Spark中都被表示为RDD.从编程的角度来看, RDD可以简单看成是一个数组.和普通数组的区别是,RDD中的数据是分区存储的,这样不 ...
- 【Java8新特性】面试官:谈谈Java8中的Stream API有哪些终止操作?
写在前面 如果你出去面试,面试官问了你关于Java8 Stream API的一些问题,比如:Java8中创建Stream流有哪几种方式?(可以参见:<[Java8新特性]面试官问我:Java8中 ...
- 记一次Hvv中遇到的API接口泄露而引起的一系列漏洞
引言 最近朋友跟我一起把之前废弃的公众号做起来了,更名为鹿鸣安全团队,后面陆续会更新个人笔记,有趣的渗透经历,内网渗透相关话题等,欢迎大家关注 前言 Hvv中的一个很有趣的漏洞挖掘过程,从一个简单的A ...
- WEB开发中的字符集和编码
html,body,div,span,applet,object,iframe,h1,h2,h3,h4,h5,h6,p,blockquote,pre,a,abbr,acronym,address,bi ...
随机推荐
- Python 内置界面开发框架 Tkinter入门篇 丁
如需要转载,请声明原文链接微信公众号「ENG八戒」https://mp.weixin.qq.com/s/X5cqennLrq7i1pzBAAqQ2w 本文大概 2562 个字,阅读需花 15 分钟 内 ...
- Docker安装Tomcat应用服务器
1.安装镜像 1. Install the image: 可以先到https://hub.docker.com/ 搜索镜像 You can get there first. https://hub. ...
- freeRTOS检测栈溢出
将FreeRTOSConfig.h里面的configCHECK_FOR_STACK_OVERFLOW设置为2. 随便一个文件里,加入 #include "task.h" void ...
- Dao包 对数据库的操作
//添加 public static int add(Bean1 bean){ String sql = "insert into classtable(classname,teacher, ...
- EPICS Archiver Appliance在Debian11下安装文档
本文很想标注转发,可是要转发链接,只好标注原创. 首先声明:本文档是合肥光源控制组孙晓康博士踩坑后整理的.我尝试过在Debian11和Rocky下安装,碰到坎过不去,这段时间各种事就没继续了,请教晓康 ...
- 【TS】枚举
ts中,枚举类型就是,枚举里面的每个数据值都可以叫做元素,每个元素都有自己的编号,编号是从0开始的,依次递增加1 , 语法: enum 枚举名 {} 此处定义一个枚举类型,例如: enum Color ...
- vue3.0+echart可视化
vue3.0 + echart可视化 案例1: 案例代码 <template> <div ref="test" style="width:800px;h ...
- JZOJ 4213. 【五校联考1day2】对你的爱深不见底
题目 思路 结论题,我不会证明: 找到第一个 \(|S_n| \leq m + 1\),那么答案就是 \(m - |S_{n-2}|\) 证明?我说了我不会,就当结论用吧 这已经很恶心了 然而这题还要 ...
- 代码随想录算法训练营day21 | leetcode ● 530.二叉搜索树的最小绝对差 ● 501.二叉搜索树中的众数 ● ***236. 二叉树的最近公共祖先
LeetCode 530.二叉搜索树的最小绝对差 分析1.0 二叉搜索树,中序遍历形成一个升序数组,节点差最小值一定在中序遍历两个相邻节点产生 ✡✡✡ 即 双指针思想在树遍历中的应用 class So ...
- VSCode 自定义代码片段
Ctrl+Shift+P 输入"代码片段:配置用户代码片段": 搜索你想要设置的语言代码片段,比如,我设置 .vue 文件的代码片段,选择 vue.json: 可以配置多个代码片段 ...