机器学习基础02DAY
数据的特征预处理
单个特征
(1)归一化
归一化首先在特征(维度)非常多的时候,可以防止某一维或某几维对数据影响过大,也是为了把不同来源的数据统一到一个参考区间下,这样比较起来才有意义,其次可以程序可以运行更快。 例如:一个人的身高和体重两个特征,假如体重50kg,身高175cm,由于两个单位不一样,数值大小不一样。如果比较两个人的体型差距时,那么身高的影响结果会比较大,k-临近算法会有这个距离公式。
min-max方法
常用的方法是通过对原始数据进行线性变换把数据映射到[0,1]之间,变换的函数为:
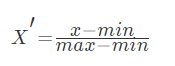
其中min是样本中最小值,max是样本中最大值,注意在数据流场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
- min-max自定义处理
import numpy as np
def data_matrix(file_name):
"""
将文本转化为matrix
:param file_name: 文件名
:return: 数据矩阵
"""
fr = open(file_name)
array_lines = fr.readlines()
number_lines = len(array_lines)
return_mat = zeros((number_lines, 3))
# classLabelVector = []
index = 0
for line in array_lines:
line = line.strip()
list_line = line.split('\t')
return_mat[index,:] = list_line[0:3]
# if(listFromLine[-1].isdigit()):
# classLabelVector.append(int(listFromLine[-1]))
# else:
# classLabelVector.append(love_dictionary.get(listFromLine[-1]))
# index += 1
return return_mat
输出结果为
[[ 4.09200000e+04 8.32697600e+00 9.53952000e-01]
[ 1.44880000e+04 7.15346900e+00 1.67390400e+00]
[ 2.60520000e+04 1.44187100e+00 8.05124000e-01]
...,
[ 2.65750000e+04 1.06501020e+01 8.66627000e-01]
[ 4.81110000e+04 9.13452800e+00 7.28045000e-01]
[ 4.37570000e+04 7.88260100e+00 1.33244600e+00]]
我们查看数据集会发现,有的数值大到几万,有的才个位数,同样如果计算两个样本之间的距离时,其中一个影响会特别大。也就是说飞行里程数对于结算结果或者说相亲结果影响较大,但是统计的人觉得这三个特征同等重要,所以需要将数据进行这样的处理。
这样每个特征任意的范围将变成[0,1]的区间内的值,或者也可以根据需求处理到[-1,1]之间,我们再定义一个函数,进行这样的转换。
def feature_normal(data_set):
"""
特征归一化
:param data_set:
:return:
"""
# 每列最小值
min_vals = data_set.min(0)
# 每列最大值
max_vals = data_set.max(0)
ranges = max_vals - min_vals
norm_data = np.zeros(np.shape(data_set))
# 得出行数
m = data_set.shape[0]
# 矩阵相减
norm_data = data_set - np.tile(min_vals, (m,1))
# 矩阵相除
norm_data = norm_data/np.tile(ranges, (m, 1)))
return norm_data
输出结果为
[[ 0.44832535 0.39805139 0.56233353]
[ 0.15873259 0.34195467 0.98724416]
[ 0.28542943 0.06892523 0.47449629]
...,
[ 0.29115949 0.50910294 0.51079493]
[ 0.52711097 0.43665451 0.4290048 ]
[ 0.47940793 0.3768091 0.78571804]]
这样得出的结果都非常相近,这样的数据可以直接提供测试验证了
- min-max的scikit-learn处理
scikit-learn.preprocessing中的类MinMaxScaler,将数据矩阵缩放到[0,1]之间
>>> X_train = np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
...
>>> min_max_scaler = preprocessing.MinMaxScaler()
>>> X_train_minmax = min_max_scaler.fit_transform(X_train)
>>> X_train_minmax
array([[ 0.5 , 0. , 1. ],
[ 1. , 0.5 , 0.33333333],
[ 0. , 1. , 0. ]])
(3)标准化
常用的方法是z-score标准化,经过处理后的数据均值为0,标准差为1,处理方法是:
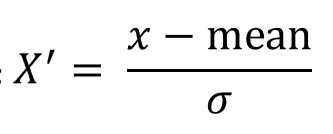
作用于每一列,mean为平均值,σ为标准差(考量数据的稳定性)

它们可以通过现有的样本进行估计,在已有的样本足够多的情况下比较稳定,适合嘈杂的数据场景
sklearn中提供了StandardScalar类实现列标准化:
In [2]: import numpy as np
In [3]: X_train = np.array([[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]])
In [4]: from sklearn.preprocessing import StandardScaler
In [5]: std = StandardScaler()
In [6]: X_train_std = std.fit_transform(X_train)
In [7]: X_train_std
Out[7]:
array([[ 0. , -1.22474487, 1.33630621],
[ 1.22474487, 0. , -0.26726124],
[-1.22474487, 1.22474487, -1.06904497]])
(3)缺失值
由于各种原因,许多现实世界的数据集包含缺少的值,通常编码为空白,NaN或其他占位符。然而,这样的数据集与scikit的分类器不兼容,它们假设数组中的所有值都是数字,并且都具有和保持含义。使用不完整数据集的基本策略是丢弃包含缺失值的整个行和/或列。然而,这是以丢失可能是有价值的数据(即使不完整)的代价。更好的策略是估算缺失值,即从已知部分的数据中推断它们。
(1)填充缺失值 使用sklearn.impute中的SimpleImputerr类进行数据的填充
#导入imputer
from sklearn.impute import SimpleImputer
import numpy as np
data = [[1, 2, np.nan], [4, np.nan, 6], [7, 8, 9]]
#实例化
imp = SimpleImputer(missing_values=np.nan, strategy="mean")
#数据填充
result = imp.fit_transform(data)
result
#结果
array([[1. , 2. , 7.5],
[4. , 5. , 6. ],
[7. , 8. , 9. ]])
数据预处理
归一化处理
In [ ]:
# MinMaxScaler导入包
from sklearn.preprocessing import MinMaxScaler
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
# 实例化 feature_range默认(0,1)
mms = MinMaxScaler(feature_range=(0,1))
#归一化处理
rusult = mms.fit_transform(data)
rusult
Out[ ]:
array([[1. , 0. , 0. , 0. ],
[0. , 1. , 1. , 0.83333333],
[0.5 , 0.5 , 0.6 , 1. ]])
标准化处理
In [ ]:
#导入StandardScaler包
from sklearn.preprocessing import StandardScaler
data = [[ 1., -1., 3.],
[ 2., 4., 2.],
[ 4., 6., -1.]]
#实例化
sds = StandardScaler()
#标准化处理
result = sds.fit_transform(data)
result
Out[ ]:
array([[-1.06904497, -1.35873244, 0.98058068],
[-0.26726124, 0.33968311, 0.39223227],
[ 1.33630621, 1.01904933, -1.37281295]])
In [ ]:
# 查看原始数据中每个特征的平均值
sds.mean_
Out[ ]:
array([2.33333333, 3. , 1.33333333])
In [ ]:
#查看原始数据每列特征的方差
sds.var_
Out[ ]:
array([1.55555556, 8.66666667, 2.88888889])
缺失值处理
In [ ]:
#导入imputer
from sklearn.impute import SimpleImputer
import numpy as np
data = [[1, 2, np.nan], [4, np.nan, 6], [7, 8, 9]]
#实例化
imp = SimpleImputer(missing_values=np.nan, strategy="mean")
#数据填充
result = imp.fit_transform(data)
result
Out[ ]:
array([[1. , 2. , 7.5],
[4. , 5. , 6. ],
[7. , 8. , 9. ]])
机器学习基础02DAY的更多相关文章
- Coursera 机器学习课程 机器学习基础:案例研究 证书
完成了课程1 机器学习基础:案例研究 贴个证书,继续努力完成后续的课程:
- Coursera台大机器学习基础课程1
Coursera台大机器学习基础课程学习笔记 -- 1 最近在跟台大的这个课程,觉得不错,想把学习笔记发出来跟大家分享下,有错误希望大家指正. 一 机器学习是什么? 感觉和 Tom M. Mitche ...
- 机器学习 —— 基础整理(六)线性判别函数:感知器、松弛算法、Ho-Kashyap算法
这篇总结继续复习分类问题.本文简单整理了以下内容: (一)线性判别函数与广义线性判别函数 (二)感知器 (三)松弛算法 (四)Ho-Kashyap算法 闲话:本篇是本系列[机器学习基础整理]在time ...
- 算法工程师<机器学习基础>
<机器学习基础> 逻辑回归,SVM,决策树 1.逻辑回归和SVM的区别是什么?各适用于解决什么问题? https://www.zhihu.com/question/24904422 2.L ...
- 数据分析之Matplotlib和机器学习基础
一.Matplotlib基础知识 Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形. 通过 Matplotlib,开发者可以仅需 ...
- 【dlbook】机器学习基础
[机器学习基础] 模型的 vc dimension 如何衡量? 如何根据网络结构衡量模型容量?有效容量和模型容量之间的关系? 统计学习理论中边界不用于深度学习之中,原因? 1.边界通常比较松, 2.深 ...
- Python机器学习基础教程-第2章-监督学习之决策树集成
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- Python机器学习基础教程-第2章-监督学习之决策树
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- Python机器学习基础教程-第2章-监督学习之线性模型
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- Python机器学习基础教程-第2章-监督学习之K近邻
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
随机推荐
- Docker学习——Kubernetes(八)
在线阅读:GitBook 下载:pdf Kubernetes 是 Google 团队发起并维护的基于 Docker 的开源容器集群管理系统,它不仅支持常见的云平台,而且支持内部数据中心. 建于 Doc ...
- JDBC概念和基本用法
概念: JDBC (Java DataBase Connectivity):Java数据库连接,Java语言操作数据库.是官方(sun公司)定义的一套操作所有关系型数据库的规则, 即接口.各个 ...
- 链表与malloc的疑惑
1.奇怪点:如果我只是需要一个结点的空间为什么malloc的转换形式写成--Node=(int *)malloc(sizeof(int)) 自我解答:void *malloc(unsigned int ...
- bzoj 3106
好久没写oi系列的题解了 要不是为了大作业我才不会回来学这些奇怪的东西呢 本题对抗搜索就好啦 首先要分析一点,就是由于我们的黑棋每次走两步,白棋只走一步而且是白棋先走,所以除非白棋第一步吃掉黑棋,否则 ...
- Python基础数据类型-Dictionary(字典)
# -- coding: utf-8 -- # @time : 2022/7/19 21:51 # @file : 10pytest基本数据类型-dic.py # @software: pycharm ...
- kubectl使用方法及常用命令小结
Kubectl 是一个命令行接口,用于对 Kubernetes 集群运行命令.kubectl 在 $HOME/.kube 目录中寻找一个名为 config 的文件. kubectl安装方法详见:htt ...
- 1903021126 申文骏 Java 第四周作业 Java分支语句学习
项目 内容 课程班级博客链接 19级信计班(本) 作业要求链接 Java第四周作业 博客名称 1903021126 申文骏 Java 第四周作业 Java分支语句学习 要求 每道题要有题目,代码( ...
- C# core 流、字节、字符串相互转换
/// <summary> /// 将 Stream 转成 byte[] /// </summary> public byte[] StreamToBytes(Stream s ...
- ICMP-ping报错类型
ICMP数据包的包头,两个重要字段Type和Code,如图所示 ICMP消息类型和编码类型 回显请求包,正常为80 回显回复包,正常为00 其余均为报错类型. 超时:对方主机不在线.屏蔽等 传输失败: ...
- Hadoop高可用集群存在的一些共性问题
Hadoop高可用集群存在的一些共性问题 1.NameNode 偶然性挂掉 问题原因: 用群启脚本启动HA集群,启动过程中NameNode要依赖于JournalNode,所以在启动过程中, Nam ...