如何在代码层面提供CPU分支预测效率
关于分支预测的基本概念和详细算法可以参考我之前写的知乎回答,基本概念不再阐述了~~
https://www.zhihu.com/question/486239354/answer/2410692045
说几个常见的能够提升CPU分支预测效率的方法。
将最常见的条件比较单独从switch中移出
分支预测除了需要预测方向,还需要预测分支的目标地址。目标地址BTA(Branch Target Address)分为两种:
- 直接跳转(PC-relative, direct) : offset以立即数形式固定在指令中,所以目标地址也是固定的。
- 间接跳转(absolute, indirect):目标地址来自通用寄存器,而寄存器的值不固定。
对于直接跳转,使用BTB可以很好的进行预测。但是对于间接跳转,目标地址不固定,更难预测。switch-case的指令实现(类似jmpq *$rax,$rax是case对应label地址)、C++虚函数调用就属于间接跳转。间接跳转如果还用直接跳转的BTB预测,准确率只有50%左右。
很多CPU针对间接跳转都有单独的预测器,比如的Intel的论文The Intel Pentium M Processor: Microarchitecture and Performance中介绍额Indirect Branch Predictor:通过额外引入context-information——Global Branch History来提高间接跳转的目标地址预测准确率。
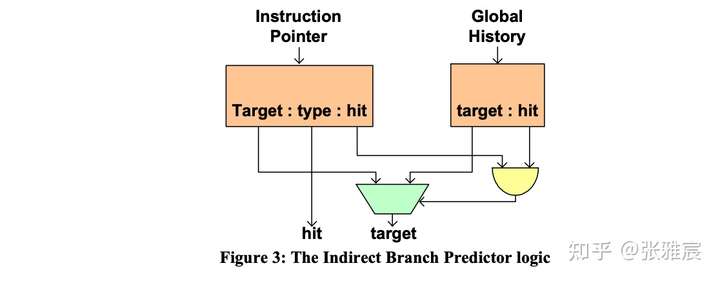
switch-case的优点是将诸多if/else(conditional branch)转换为统一的unconditioal branch,但缺点就是目标地址难以预测。如果某个case的命中率特别高,就可以将其从switch中单独提出来,这样该分支的预测方向 && 目标地址都很好预测。

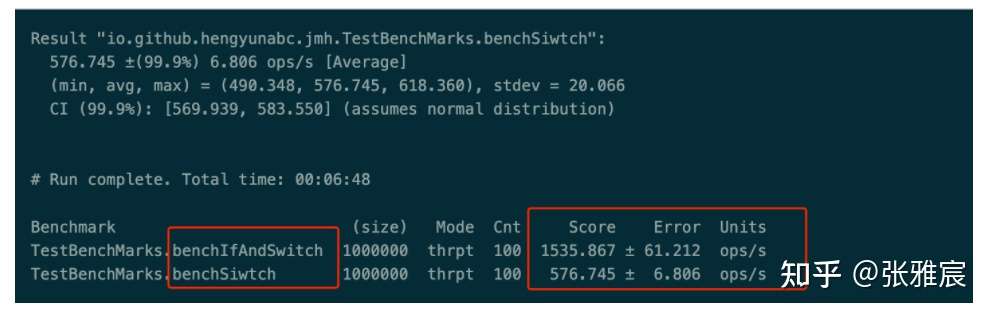
超过99.9%情况state取值都是ChannelState.RECEIVED ,将其单独提出来。官网博客有一个benchmark,性能有很大的改观。
将使用【控制】的条件转移转换为使用【数据】的条件转移
CMOV指令就是典型的例子。CPU无需进行分支预测,但是会计算一个条件的两种结果,然后通过检查条件码,要么更新目的寄存器,要么保持不变。
比如
v = test-expr ? then-expr : else-expr会转换为下列伪代码:
v = then-expr;
ve = else-expr;
t = test-expr;
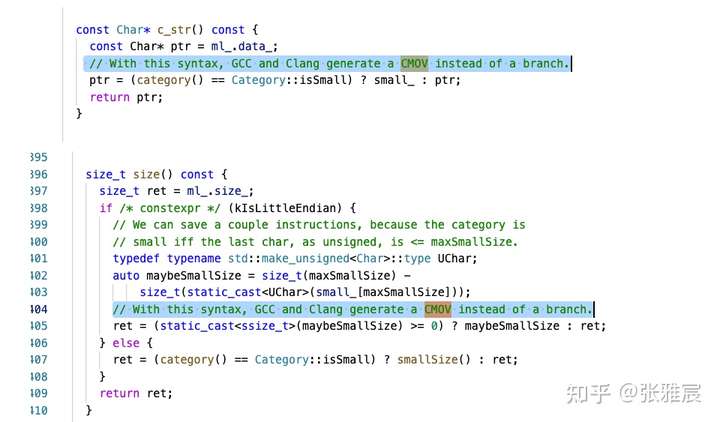
if(!t) v=ve;编译器会倾向于将使用三元运算符且两种结果的计算量不大的表达式转换为CMOV条件数据转移。例如facebook folly中的例子,注意看注释:
当分支的结果完全由外部输入决定,local branch history和global branch history都毫无规律时,效果会更好。下面这个是《Computer Systems A Programmer's Perspective 》5.11.2小节的例子,第二个版本性能是第一个三倍:
/* Rearrange two vectors so that for each i, b[i] >= a[i] */
void minmax1(long a[], long b[], long n) {
long i;
for (i = 0; i < n; i++) {
if (a[i] > b[i]) {
long t = a[i];
a[i] = b[i];
b[i] = t;
}
}
}
/* Rearrange two vectors so that for each i, b[i] >= a[i] */
void minmax2(long a[], long b[], long n) {
long i;
for (i = 0; i < n; i++) {
long min = a[i] < b[i] ? a[i] : b[i];
long max = a[i] < b[i] ? b[i] : a[i];
a[i] = min;
b[i] = max;
}
}使用算数逻辑代替分支
比如ARM优化手册里提到,可以将范围比较转换为无条件计算,编译器有时候也会自动做这个转换:
// origin version
int insideRange1(int v, int min, int max) {
return v >= min && v < max;
}
// optimized version
int insideRange2(int v, int min, int max) {
return (unsigned) (v - min) < (max - min);
}韦易笑大佬针对这个做过更详细的优化和测试,反正我是看晕了:
引用文章内的测试数据:
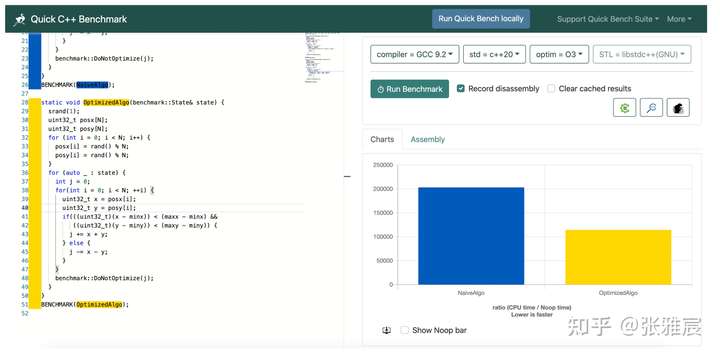
Avoiding Branches里有更多的例子,不过用之前还是做测试更靠谱。
使用template移除分支
2018年Stephen Yang的博士论文NanoLog: A Nanosecond Scale Logging System介绍了一款C++日志库Nanolog,将日志调用开销的中位数降为了个位数纳秒级别。作者在文章NANOLOG: A NANOSECOND SCALE LOGGING SYSTEM中提到了Nanolog的关键技术和优化,第三条就是将printf在运行时的大量分支逻辑利用C++ template优化成编译期的运算。

likely/unlikely
这个很多人已经介绍过了,C++20已经将其标准化,支持将更可能执行的代码放在hot path上,对icache更友好。例如facebook folly中的例子:
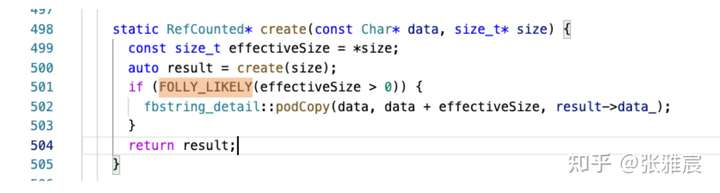
FOLLY_LIKELY是一个包装:

更进一步,有些ISA的分支指令有一个bit,支持programmer去指定分支是否taken。现代CPU使用的TAGE分支预测器,部分实现会使用该bit去初始化predictor(是初始化,不是一直使用programmer指定的跳转结果)。TAGE预测器可以参考下我开头放的回答:https://www.zhihu.com/question/486239354/answer/2410692045

(完)
朋友们可以关注下我的公众号,获得最及时的更新:

如何在代码层面提供CPU分支预测效率的更多相关文章
- CPU 分支预测
去年在安宁庄的时候, 有个同事阐述了一个观点:php中的if else 在执行时考虑到效率的原因,不会按我们的代码的顺序一条一条去试,而是随机找出一个分支,执行,如果不对,再随机找到一个分支 当时由 ...
- 从一段 Dubbo 源码到 CPU 分支预测的一次探险之旅
每个时代,都不会亏待会学习的人. 大家好,我是 yes. 这次本来是打算写一篇 RocketMQ 相关文章的,但是被插队了,我也是没想到的. 说来也是巧最近在看 Dubbo 源码,然后发现了一处很奇怪 ...
- CPU分支预测器
两篇结合就ok啦 1.https://www.jianshu.com/p/be389eeba589 2.https://blog.csdn.net/edonlii/article/details/87 ...
- 现代中央处理器(CPU)是怎样进行分支预测的?
人们一直追求CPU分支预测的准确率,论文Simultaneous Subordinate Microthreading (SSMT)中给了一组数据,如果分支预测的准确率是100%,大多数应用的IPC会 ...
- 【操作系统之十二】分支预测、CPU亲和性(affinity)
一.分支预测 当包含流水线技术的处理器处理分支指令时就会遇到一个问题,根据判定条件的真/假的不同,有可能会产生转跳,而这会打断流水线中指令的处理,因为处理器无法确定该指令的下一条指令,直到分支执行完毕 ...
- 【CPU微架构设计】利用Verilog设计基于饱和计数器和BTB的分支预测器
在基于流水线(pipeline)的微处理器中,分支预测单元(Branch Predictor Unit)是一个重要的功能部件,它负责收集和分析分支/跳转指令的执行结果,当处理后续分支/跳转指令时,BP ...
- GCC的分支预测优化__builtin_expect
智能指针笔记 GCC的原子操作函数 将流水线引入cpu,可以提高cpu的效率.更简单的说,让cpu可以预先取出下一条指令,可以提供cpu的效率.如下图所示: 取指令 执行指令 输出结果 取指令 执行 ...
- __builtin_expect — 分支预测优化
1.引言 在很多源码如Linux内核.Glib等,我们都能看到likely()和unlikely()这两个宏,通常这两个宏定义是下面这样的形式. #define likely(x) __builtin ...
- 通过从代码层面分析Linux内核启动来探知操作系统的启动过程
通过从代码层面分析Linux内核启动来探知操作系统的启动过程 前言说明 本篇为网易云课堂Linux内核分析课程的第三周作业,我将围绕Linux 3.18的内核中的start_kernel到init进程 ...
随机推荐
- 如何运行MATLAB和C++混合编程
在GitHub下载了一个大佬的滤波器程序,包含MATLAB和C++,刚开始直接运行,发现提示如下: 然后,第一步:点击截图访问后面的链接,跳转到如下截图: 第二步:点击上面截图的左下角,R2015b版 ...
- spring-boot-EnvironmentPostProcessor
原理: 1-从启动类入口的run方法进入: public ConfigurableApplicationContext run(String... args) { -SpringApplication ...
- Dubbo 集群容错有几种方案?
集群容错方案 说明 Failover Cluster 失败自动切换,自动重试其它服务器(默认) Failfast Cluster 快速失败,立即报错,只发起一次调用 Failsafe Cluster ...
- 有哪些类型的通知(Advice)?
Before - 这些类型的 Advice 在 joinpoint 方法之前执行,并使用 @Before 注解标记进行配置. After Returning - 这些类型的 Advice 在连接点方法 ...
- Streamlit:快速数据可视化界面工具
目录 Streamlit简介 Streamlit使用指南 常用命令 显示文本 显示数据 显示图表 显示媒体 交互组件 侧边栏 缓存机制 Streamlit使用Hack Streamlit的替代品 相关 ...
- HTML5相关文章和资源
Polyfills HTML5 Cross Browser Polyfills canvas HTML5 JS实现毛玻璃效果(高斯模糊) 高斯模糊的算法Canvas 内部元素添加事件处理 应用场景 P ...
- java中求一下2008年5月31日, 往前倒30天是哪天?
题目9: 2008年5月31日, 往前倒30天是哪天? import java.util.*; public class Test { public static void main(Str ...
- Android:Unable to find explicit activity class报错
错误:Unable to find explicit activity class 原因:没有给activity在AndroidManifest.xml中注册 解决办法: 在AndroidManife ...
- Reflect.has检测对象是否拥有某个属性
Reflect.has({x: 0}, 'x'); // true Reflect.has({x: 0}, 'y'); // false // returns true for properties ...
- JavaScript实现动态表格
运行效果: 源代码: 1 <!DOCTYPE html> 2 <html lang="zh"> 3 <head> 4 <meta char ...