论文解读(MERIT)《Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning》
论文信息
论文标题:Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning
论文作者:Ming Jin, Yizhen Zheng, Yuan-Fang Li, Chen Gong, Chuan Zhou, Shirui Pan
论文来源:2021, IJCAI
论文地址:download
论文代码:download
1 Introduction
创新:融合交叉视图对比和交叉网络对比。
2 Method
算法图示如下:
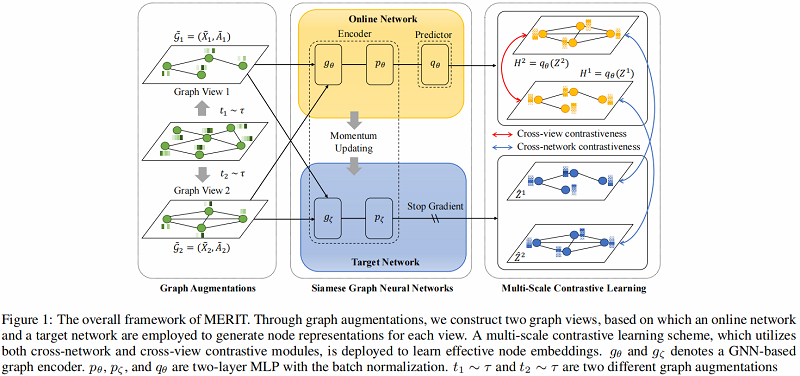
模型组成部分:
- Graph augmentations
- Cross-network contrastive learning
- Cross-view contrastive learning
2.1 Graph Augmentations
- Graph Diffusion (GD)
$S=\sum\limits _{k=0}^{\infty} \theta_{k} T^{k} \in \mathbb{R}^{N \times N}\quad\quad\quad(1)$
这里采用 PPR kernel:
$S=\alpha\left(I-(1-\alpha) D^{-1 / 2} A D^{-1 / 2}\right)^{-1}\quad\quad\quad(2)$
- Edge Modification (EM)
给定修改比例 $P$ ,先随机删除 $P/2$ 的边,再随机添加$P/2$ 的边。(添加和删除服从均匀分布)
- Subsampling (SS)
在邻接矩阵中随机选择一个节点索引作为分割点,然后使用它对原始图进行裁剪,创建一个固定大小的子图作为增广图视图。
- Node Feature Masking (NFM)
给定特征矩阵 $X$ 和增强比 $P$,我们在 $X$ 中随机选择节点特征维数的 $P$ 部分,然后用 $0$ 掩码它们。
在本文中,将 SS、EM 和 NFM 应用于第一个视图,并将 SS+GD+NFM 应用于第二个视图。
2.2 Cross-Network Contrastive Learning
MERIT 引入了一个孪生网络架构,它由两个相同的编码器(即 $g_{\theta}$, $p_{\theta}$, $g_{\zeta}$ 和 $p_{\zeta}$)组成,在 online encoder 上有一个额外的预测器$q_{\theta}$,如 Figure 1 所示。
这种对比性的学习过程如 Figure 2(a) 所示:

其中:
- $H^{1}=q_{\theta}\left(Z^{1}\right)$
- $Z^{1}=p_{\theta}\left(g_{\theta}\left(\tilde{X}_{1}, \tilde{A}_{1}\right)\right)$
- $Z^{2}=p_{\theta}\left(g_{\theta}\left(\tilde{X}_{2}, \tilde{A}_{2}\right)\right)$
- $\hat{Z}^{1}=p_{\zeta}\left(g_{\zeta}\left(\tilde{X}_{1}, \tilde{A}_{1}\right)\right)$
- $\hat{Z}^{2}=p_{\zeta}\left(g_{\zeta}\left(\tilde{X}_{2}, \tilde{A}_{2}\right)\right)$
参数更新策略(动量更新机制):
$\zeta^{t}=m \cdot \zeta^{t-1}+(1-m) \cdot \theta^{t}\quad\quad\quad(3)$
其中,$m$、$\zeta$、$\theta$ 分别为动量参数、target network 参数和 online network 参数。
损失函数如下:
$\mathcal{L}_{c n}=\frac{1}{2 N} \sum\limits _{i=1}^{N}\left(\mathcal{L}_{c n}^{1}\left(v_{i}\right)+\mathcal{L}_{c n}^{2}\left(v_{i}\right)\right)\quad\quad\quad(6)$
其中:
$\mathcal{L}_{c n}^{1}\left(v_{i}\right)=-\log {\large \frac{\exp \left(\operatorname{sim}\left(h_{v_{i}}^{1}, \hat{z}_{v_{i}}^{2}\right)\right)}{\sum_{j=1}^{N} \exp \left(\operatorname{sim}\left(h_{v_{i}}^{1}, \hat{z}_{v_{j}}^{2}\right)\right)}}\quad\quad\quad(4) $
$\mathcal{L}_{c n}^{2}\left(v_{i}\right)=-\log {\large \frac{\exp \left(\operatorname{sim}\left(h_{v_{i}}^{2}, \hat{z}_{v_{i}}^{1}\right)\right)}{\sum_{j=1}^{N} \exp \left(\operatorname{sim}\left(h_{v_{i}}^{2}, \hat{z}_{v_{j}}^{1}\right)\right)}}\quad\quad\quad(5) $
2.3 Cross-View Contrastive Learning
损失函数:
$\mathcal{L}_{c v}^{k}\left(v_{i}\right)=\mathcal{L}_{\text {intra }}^{k}\left(v_{i}\right)+\mathcal{L}_{\text {inter }}^{k}\left(v_{i}\right), \quad k \in\{1,2\}\quad\quad\quad(10)$
其中:
$\mathcal{L}_{c v}=\frac{1}{2 N} \sum\limits _{i=1}^{N}\left(\mathcal{L}_{c v}^{1}\left(v_{i}\right)+\mathcal{L}_{c v}^{2}\left(v_{i}\right)\right)\quad\quad\quad(9)$
$\mathcal{L}_{\text {inter }}^{1}\left(v_{i}\right)=-\log {\large \frac{\exp \left(\operatorname{sim}\left(h_{v_{i}}^{1}, h_{v_{i}}^{2}\right)\right)}{\sum_{j=1}^{N} \exp \left(\operatorname{sim}\left(h_{v_{i}}^{1}, h_{v_{j}}^{2}\right)\right)}}\quad\quad\quad(7) $
$\begin{aligned}\mathcal{L}_{i n t r a}^{1}\left(v_{i}\right) &=-\log \frac{\exp \left(\operatorname{sim}\left(h_{v_{i}}^{1}, h_{v_{i}}^{2}\right)\right)}{\exp \left(\operatorname{sim}\left(h_{v_{i}}^{1}, h_{v_{i}}^{2}\right)\right)+\Phi} \\\Phi &=\sum\limits_{j=1}^{N} \mathbb{1}_{i \neq j} \exp \left(\operatorname{sim}\left(h_{v_{i}}^{1}, h_{v_{j}}^{1}\right)\right)\end{aligned}\quad\quad\quad(8)$
2.4 Model Training
$\mathcal{L}=\beta \mathcal{L}_{c v}+(1-\beta) \mathcal{L}_{c n}\quad\quad\quad(11)$
3 Experiment
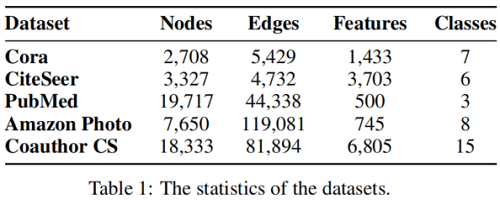
数据集
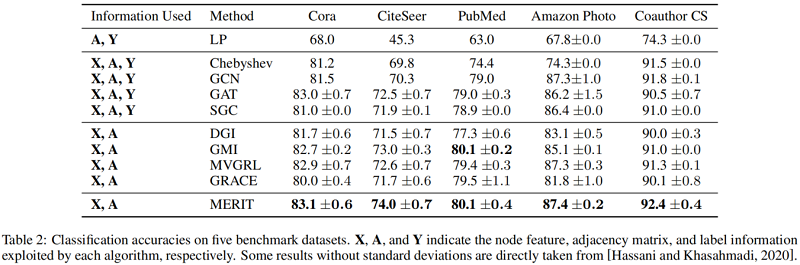
基线实验
论文解读(MERIT)《Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning》的更多相关文章
- 论文解读(SUBG-CON)《Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning》
论文信息 论文标题:Sub-graph Contrast for Scalable Self-Supervised Graph Representation Learning论文作者:Yizhu Ji ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》2
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 论文解读(GMI)《Graph Representation Learning via Graphical Mutual Information Maximization》
Paper Information 论文作者:Zhen Peng.Wenbing Huang.Minnan Luo.Q. Zheng.Yu Rong.Tingyang Xu.Junzhou Huang ...
- 论文解读(GRCCA)《 Graph Representation Learning via Contrasting Cluster Assignments》
论文信息 论文标题:Graph Representation Learning via Contrasting Cluster Assignments论文作者:Chun-Yang Zhang, Hon ...
- 论文解读GALA《Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learning》
论文信息 Title:<Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learn ...
- 论文解读(SUGRL)《Simple Unsupervised Graph Representation Learning》
Paper Information Title:Simple Unsupervised Graph Representation LearningAuthors: Yujie Mo.Liang Pen ...
- 论文阅读 Dynamic Graph Representation Learning Via Self-Attention Networks
4 Dynamic Graph Representation Learning Via Self-Attention Networks link:https://arxiv.org/abs/1812. ...
- 论文解读(MVGRL)Contrastive Multi-View Representation Learning on Graphs
Paper Information 论文标题:Contrastive Multi-View Representation Learning on Graphs论文作者:Kaveh Hassani .A ...
- 论文笔记:Deeper and Wider Siamese Networks for Real-Time Visual Tracking
Deeper and Wider Siamese Networks for Real-Time Visual TrackingUpdated on 2019-04-01 16:10:37 Paper ...
随机推荐
- 同一套代码部署多个实例来并行完成mysql某项任务,且避免重复执行
我经常会碰到一些耗时较长的任务,譬如更新5千万条表数据中的某个字段,代码中可以通过分页依次读取db,然后更新即可.但是耗时极长,那么能否通过将代码部署多个实例,譬如启动多个docker来并行执行任务, ...
- kafka分布式的情况下,如何保证消息的顺序?
作者:可期链接:https://www.zhihu.com/question/266390197/answer/772404605来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注 ...
- zookeeper的通知机制
一.znode Zookeeper维护一个类似文件系统的数据结构.简单来说,有点类似windows中注册表的结构,有名称,有树节点,有Key(键)/Value(值)对的关系,可以看做一个树形结构的数据 ...
- 我对arguments.callee的理解
基本理解: 你怎么看待一个函数呢?又如何看待一个函数对象呢?函数和Function之间的关系到底是什么?我觉得理解这些对理解arguments.callee有所帮助. 先说说auguments.cal ...
- 解释 Spring 框架中 bean 的生命周期?
Spring 容器 从 XML 文件中读取 bean 的定义,并实例化 bean. Spring 根据 bean 的定义填充所有的属性. 如果 bean 实现了 BeanNameAware 接口,Sp ...
- Java 中能创建 volatile 数组吗?
能,Java 中可以创建 volatile 类型数组,不过只是一个指向数组的引用,而不 是整个数组.我的意思是,如果改变引用指向的数组,将会受到 volatile 的保护, 但是如果多个线程同时改变数 ...
- 安装ESLint
安装ESLint ESLint是静态代码检查工具,配合TypeScript使用可以帮助检查TypeScript的语法和代码风格. 添加ESLint到当前工程,yarn add -D eslint. 使 ...
- ES6-11学习笔记--Promise
Promise是ES6异步编程解决方案之一,简化以前ajax的嵌套地狱,增加代码可读性. 基本用法: resolve,成功 reject,失败 let p = new Promise((resol ...
- python-班级人员信息统计
输入a,b班的名单,并进行如下统计. 输入格式: 第1行::a班名单,一串字符串,每个字符代表一个学生,无空格,可能有重复字符.第2行::b班名单,一串字符串,每个学生名称以1个或多个空格分隔,可能有 ...
- java中throws子句是怎么用的?工作原理是什么
7.throws子句 马克-to-win:当你的方法里抛出了checked异常,如你不catch,代表你当时不处理(不想处理或没条件处理),但你必须得通过"throws那个异常"告 ...