【Java8新特性】- Stream流
Java8新特性 - Stream流的应用
生命不息,写作不止
继续踏上学习之路,学之分享笔记
总有一天我也能像各位大佬一样
一个有梦有戏的人 @怒放吧德德
分享学习心得,欢迎指正,大家一起学习成长!
简介
stream是java8新出的抽象概念,他可以让你根据你期望的方式来处理集合数据,能够轻松的执行复杂的查找、过滤和映射数据等操作。Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
对于一个集合,首先需要转成stream流,可以使用中间操作(filter过滤器、distinct去重、sorted排序等),但是最后是由终止操作结束(forEach遍历、collect转换、min,max最小最大等)。
Stream流的使用
生成流
在 Java 8 中, 集合接口有两个方法来生成流:
- stream() − 为集合创建串行流,也就是采用单线程执行
- parallelStream() − 为集合创建并行流,也就是采用多线程执行
串行流:单线程的方式操作, 数据量比较少的时候使用
并行流:多线程方式操作,数据量比较大的时候使用
主要原理是:将一个大的任务拆分n多个小的子任务并行执行,
最后在统计结果,有可能会非常消耗cpu的资源,确实可以
提高效率,但是在数据量不多的时候就不要使用并行流。
Stream将list转换为Set
首先将list转成stream流,在通过collect(Collectors.toSet())的方法得到set集合。但是,直接这么操作,set集合是无法去重的。首先需要了解一下set的底层是如何防止重复的key的,我们都知道set底层依赖map防止重复的key,map集合底层依靠equals比较防止重复的key。所以我们需要在实体类型中去重写equals和hashcode的方法。
实体类:
package com.jdk8.demo.lambda.entity;
import java.util.HashMap;
/**
* @author: lyd
* @description: 实体
* @Date: 2022/10/5
*/
public class Student {
private String name;
private Integer score;
// ... 省略get、set、构造方法
@Override
public boolean equals(Object obj) {
if (obj instanceof Student) {
return name.equals(((Student) obj).name) && score == ((Student) obj).score;
}
return false;
}
@Override
public int hashCode() {
return score.hashCode();
}
}
测试代码
public static void main(String[] args) {
// Stream将list转换为Set
ArrayList<Student> students = new ArrayList<>();
students.add(new Student("lyd", 99));
students.add(new Student("lkj", 55));
students.add(new Student("llm", 67));
students.add(new Student("lss", 87));
students.add(new Student("lss", 87));
/**
* set底层依赖map防止重复的key,map集合底层依靠equals比较防止重复的key
*/
Stream<Student> stream = students.stream();
Set<Student> collect = stream.collect(Collectors.toSet());
Iterator<Student> iterator = collect.iterator();
while (iterator.hasNext()) {
Student next = iterator.next();
System.out.println(next.getName() + " -> " + next.getScore());
}
}
结果:

Stream将list转换为Map
list集合转成stream流之后,通过<R, A> R collect(Collector<? super T, A, R> collector),在通过
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper) {
return toMap(keyMapper, valueMapper, throwingMerger(), HashMap::new);
}
来声明key和value。如下代码,可以这么理解,stream.collect(Collectors.toMap(key, value)),key和value都是通过new Function<T, K>,对于key:T指的是Steam流的类型(既Student),而K代表的是map中的key值,因此这里是String类型的,在apply方法中去返回key值,通过student的名字来最为key,因此这里返回student.getName()。而第二个作为map的value,整体操作也是跟key差不多,主要还是需要注意的是,value存的是student,因此需要使用Student类型。
Map<String, Student> map = stream.collect(Collectors.toMap(new Function<Student, String>() {
@Override
public String apply(Student student) {
return student.getName();
}
}, new Function<Student, Student>() {
@Override
public Student apply(Student student) {
return student;
}
}));
最后都可以使用lambda表达式来
public static void main(String[] args) {
// Stream将list转换为Map
ArrayList<Student> students = new ArrayList<>();
students.add(new Student("lyd", 99));
students.add(new Student("lkj", 55));
students.add(new Student("llm", 67));
students.add(new Student("lss", 87));
Stream<Student> stream = students.stream();
Map<String, Student> map = stream.collect(Collectors.toMap(student -> student.getName(), student -> student));
map.forEach((key, value) -> System.out.println("key: " + key + " -> value: " + value));
}
结果

Stream使用Reduce求和
通过使用stream的reduce方法,在里面去new BinaryOperator,代码如下
public static void main(String[] args) {
// Stream使用Reduce求和
ArrayList<Student> students = new ArrayList<>();
students.add(new Student("lyd", 99));
students.add(new Student("lkj", 55));
students.add(new Student("llm", 67));
students.add(new Student("lss", 87));
Stream<Student> stream = students.stream();
Optional<Student> sum = stream.reduce((student, student2) -> {
Student sum1 = new Student("sum", student.getScore() + student2.getScore());
return sum1;
});
System.out.println(sum.get().getName() + " : " + sum.get().getScore());
}
结果

Stream使用Max和Min
实际上就是通过匿名内部类new Comparator()实现public int compare(Student o1, Student o2)比较方法。
public static void main(String[] args) {
// StreamMax和Min
ArrayList<Student> students = new ArrayList<>();
students.add(new Student("lyd", 99));
students.add(new Student("lkj", 55));
students.add(new Student("llm", 67));
students.add(new Student("lss", 87));
Stream<Student> stream = students.stream();
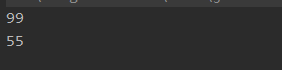
Optional<Student> max = stream.max((o1, o2) -> o1.getScore() - o2.getScore());
System.out.println(max.get().getScore());
Stream<Student> stream2 = students.stream();
Optional<Student> min = stream2.min((o1, o2) -> o1.getScore() - o2.getScore());
// 可以使用方法引入更加简便
// Optional<Student> min = stream2.min(Comparator.comparingInt(Student::getScore));
System.out.println(min.get().getScore());
}
结果
Stream中Match匹配
- anyMatch表示,判断的条件里,任意一个元素成功,返回true
- allMatch表示,判断条件里的元素,所有的都是,返回true
- noneMatch跟allMatch相反,判断条件里的元素,所有的都不是,返回true
public static void main(String[] args) {
ArrayList<Student> students = new ArrayList<>();
students.add(new Student("lyd", 99));
students.add(new Student("lkj", 55));
students.add(new Student("llm", 67));
students.add(new Student("lss", 87));
Stream<Student> stream = students.stream();
boolean allMatch = stream.allMatch(student -> student.getScore() > 60);
System.out.println("allMatch: " + allMatch);
Stream<Student> stream2 = students.stream();
boolean anyMatch = stream2.anyMatch(student -> student.getScore() > 60);
System.out.println("anyMatch: " + anyMatch);
Stream<Student> stream3 = students.stream();
boolean noneMatch = stream3.noneMatch(student -> student.getScore() > 60);
System.out.println("noneMatch: " + noneMatch);
}
结果

Stream的过滤与遍历
stream的过滤是通过filter方法,通过实现匿名内部类new Predicate()的test方法,并且可以使用链式编程,持续过滤并且遍历,因为过滤不是终止运算。然而forEach是实现匿名内部类new Consumer()的accept方法。可以通过new的方式在通过idea来生成lambda表达式。
public static void main(String[] args) {
ArrayList<Student> students = new ArrayList<>();
students.add(new Student("lyd", 99));
students.add(new Student("lkj", 55));
students.add(new Student("llm", 67));
students.add(new Student("lss", 87));
Stream<Student> stream = students.stream();
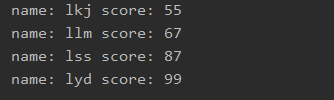
stream.filter(student -> student.getName() != null)
.filter(student -> student.getScore() > 70)
.forEach(student -> System.out.println("name: " + student.getName() + " score: " + student.getScore()));
}
结果

Stream的排序
不仅Arrays以及数组能够实现排序甚至是重写排序规则,Stream流也是提供了相应的方法。通过实现匿名内部类Comparator的compare方法。
public static void main(String[] args) {
ArrayList<Student> students = new ArrayList<>();
students.add(new Student("lyd", 99));
students.add(new Student("lkj", 55));
students.add(new Student("llm", 67));
students.add(new Student("lss", 87));
Stream<Student> stream = students.stream();
stream.sorted(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getScore() - o2.getScore();
}
}).forEach(new Consumer<Student>() {
@Override
public void accept(Student student) {
System.out.println("name: " + student.getName() + " score: " + student.getScore());
}
});
/*lambda*/
stream.sorted((o1, o2) -> o1.getScore() - o2.getScore())
.forEach(student -> System.out.println("name: " + student.getName() + " score: " + student.getScore()));
/*方法引入*/
stream.sorted(Comparator.comparingInt(Student::getScore))
.forEach(student -> System.out.println("name: " + student.getName() + " score: " + student.getScore()));
}
结果
Stream的limit与skip
在SQL中可以通过limit进行分页数据的获取,在java8的stream流中,limit是获取集合中的前几个值,而skip是跳过几个元素。当我们需要获取第二到第三个元素的时候,可以通过skip(1)在通过limit(2)获取。
public static void main(String[] args) {
ArrayList<Student> students = new ArrayList<>();
students.add(new Student("lyd", 99));
students.add(new Student("lkj", 55));
students.add(new Student("llm", 67));
students.add(new Student("lss", 87));
Stream<Student> stream = students.stream();
stream.skip(1).limit(2).forEach(student -> System.out.println("name: " + student.getName() + " score: " + student.getScore()));
}
结果

工作繁忙也需要学习。
创作不易,如有错误请指正,感谢观看!记得点赞哦!
【Java8新特性】- Stream流的更多相关文章
- 这可能是史上最好的 Java8 新特性 Stream 流教程
本文翻译自 https://winterbe.com/posts/2014/07/31/java8-stream-tutorial-examples/ 作者: @Winterbe 欢迎关注个人微信公众 ...
- Java8新特性 Stream流式思想(二)
如何获取Stream流刚开始写博客,有一些不到位的地方,还请各位论坛大佬见谅,谢谢! package cn.com.zq.demo01.Stream.test01.Stream; import org ...
- Java8新特性Stream流应用示例
Java8新特性介绍 过滤集合 List<String> newList = list.stream().filter(item -> item != null).collect(C ...
- java8 新特性Stream流的应用
作为一个合格的程序员,如何让代码更简洁明了,提升编码速度尼. 今天跟着我一起来学习下java 8 stream 流的应用吧. 废话不多说,直入正题. 考虑以下业务场景,有四个人员信息,我们需要根据性 ...
- Java8新特性 Stream流式思想(一)
遍历及过滤集合中的元素使用传统方式遍历及过滤集合中的元素package cn.com.zq.demo01.Stream.test01.Stream; import java.util.ArrayLis ...
- Java8新特性 Stream流式思想(三)
Stream接口中的常用方法 forEach()方法package cn.com.cqucc.demo02.StreamMethods.Test02.StreamMethods; import jav ...
- Java8 新特性 —— Stream 流式编程
本文部分摘自 On Java 8 流概述 集合优化了对象的存储,大多数情况下,我们将对象存储在集合是为了处理他们.使用流可以帮助我们处理对象,无需迭代集合中的元素,即可直接提取和操作元素,并添加了很多 ...
- Java8新特性——stream流
一.基本API初探 package java8.stream; import java.util.Arrays; import java.util.IntSummaryStatistics; impo ...
- java8 新特性 Stream流 分组 排序 过滤 多条件去重
private static List<User> list = new ArrayList<User>(); public static void main(String[] ...
- Java8 新特性 Stream 无状态中间操作
无状态中间操作 Java8 新特性 Stream 练习实例 中间无状态操作,可以在单个对单个的数据进行处理.比如:filter(过滤)一个元素的时候,也可以判断,比如map(映射)... 过滤 fil ...
随机推荐
- 关于标准IO缓冲区的问题
关于标准IO缓冲区的问题 按照标准IO缓冲区可以分为三类: 不缓存类型: 一旦有数据,直接将数据写入到文件 行缓冲类型: 同全缓冲类型 遇到\n时,将数据写入文件 全缓冲类型: 当程序结束,将数据冲洗 ...
- 使用python3.7和opencv4.1来实现人脸识别和人脸特征比对以及模型训练
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_126 OpenCV4.1已经发布将近一年了,其人脸识别速度和性能有了一定的提高,这里我们使用opencv来做一个实时活体面部识别的 ...
- GP查询表状态常用SQL
- EPLAN 中的符号、元件、部件与设备之间的区别
符号(Symbol):电气符号是电器设备(Electrical equipment)的一种图形表达,符号存放在符号库中,是广大电气工程师之间的交流语言,用来传递系统控制的设计思维的.将设计思维体现出来 ...
- MySQL之JDBC编程增删改查
MySQL之JDBC 一.JDBC是什么 Java DatabaseConnectivity (java语言连接数据库) 二.JDBC的本质 JDBC是SUN公司制定的一套接口(interface). ...
- [C#]使用 AltCover 获得代码覆盖率 - E2E Test 和 Unit Test
背景 在 CI/CD 流程当中,测试是 CI 中很重要的部分.跟开发人员关系最大的就是单元测试,单元测试编写完成之后,我们可以使用 IDE 或者 dot cover 等工具获得单元测试对于业务代码的覆 ...
- 在django中前后端传输数据的编码格式(contentType)
写在前面 在django中,针对前后端传输数据的编码格式,我们主要研究的是post请求:因为get请求传输的数据往往是直接放在url的后面的!如: url?username=zhang&pas ...
- Docker 06 部署Nginx
参考源 https://www.bilibili.com/video/BV1og4y1q7M4?spm_id_from=333.999.0.0 https://www.bilibili.com/vid ...
- FTP 基础 与 使用 Docker 搭建 Vsftpd 的 FTP 服务
FTP 基础 与 使用 Docker 搭建 Vsftpd 的 FTP 服务 前言 最近的工作中,需要将手机上的文件发送到公司的 FTP 的服务器.按照从前的思路,自然是,先将文件传到电脑,再由电脑上传 ...
- ArcGIS QGIS学习一:打开shp、geojson地图变形变扁问题(附最新坐标边界下载全国省市区县乡镇)
目录 打开的地图变扁了 修改投影坐标系 等角圆锥投影 Web墨卡托投影 一些要注意的地方 打开的地图变扁了 记得初学GIS软件时,用ArcGIS或QGIS打开省级地图的时候(shp或geojson等格 ...