ElasticSearch 监控单个节点详解
1、介绍
集群健康 就像是光谱的一端——对集群的所有信息进行高度概述。 而 节点统计值 API 则是在另一端。它提供一个让人眼花缭乱的统计数据的数组,包含集群的每一个节点统计值。
节点统计值 提供的统计值如此之多,在完全熟悉它之前,你可能都搞不清楚哪些指标是最值得关注的。我们将会高亮那些最重要的监控指标(但是我们鼓励你记录接口提供的所有指标——
或者用 Marvel ——因为你永远不知道何时需要某个或者另一个值)。
2、节点统计值命令
GET _nodes/stats
3、结果介绍
1、开头部分
在输出内容的开头,我们可以看到集群名称和我们的第一个节点:
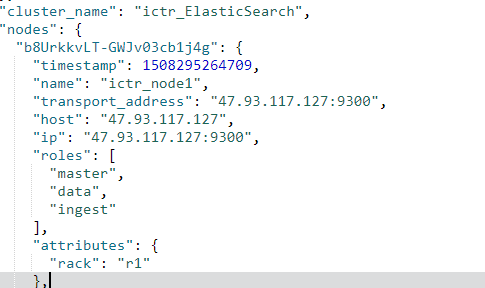
节点是排列在一个哈希里,以节点的 UUID 作为键名。还显示了节点网络属性的一些信息(比如传输层地址和主机名)。这些值对调试诸如节点未加入集群这类自动发现问题很有用。
通常你会发现是端口用错了,或者节点绑定在错误的 IP 地址/网络接口上了。
2、索引部分
索引(indices) 部分列出了这个节点上所有索引的聚合过的统计值 :
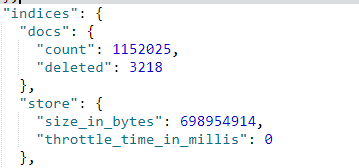
返回的统计值被归入以下部分:
docs 展示节点内存有多少文档,包括还没有从段里清除的已删除文档数量。
store 部分显示节点耗用了多少物理存储。这个指标包括主分片和副本分片在内。如果限流时间很大,那可能表明你的磁盘限流设置得过低(在段和合并里讨论过)。
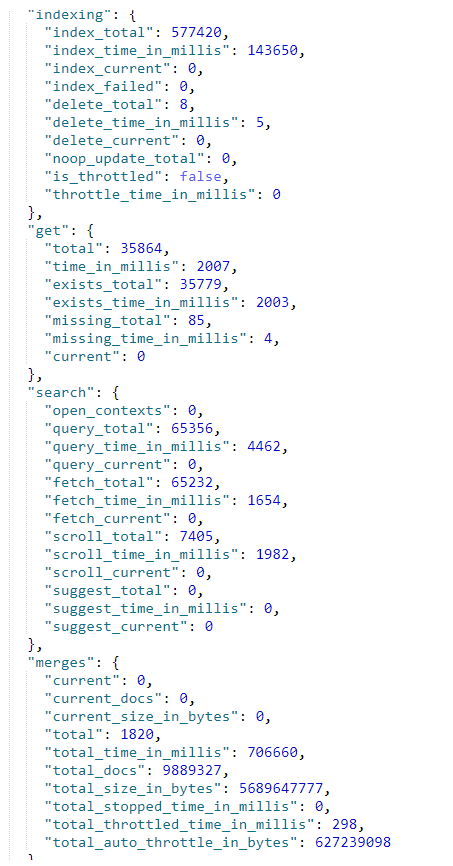
1、 indexing 显示已经索引了多少文档。这个值是一个累加计数器。在文档被删除的时候,数值不会下降。还要注意的是,在发生内部 索引 操作的时候,这个值也会增加,比如说文档更新。
还列出了索引操作耗费的时间,正在索引的文档数量,以及删除操作的类似统计值。
2、get 显示通过 ID 获取文档的接口相关的统计值。包括对单个文档的 GET 和 HEAD 请求。
3、search 描述在活跃中的搜索( open_contexts )数量、查询的总数量、以及自节点启动以来在查询上消耗的总时间。用 query_time_in_millis / query_total 计算的比值,
可以用来粗略的评价你的查询有多高效。比值越大,每个查询花费的时间越多,你应该要考虑调优了。fetch 统计值展示了查询处理的后一半流程(query-then-fetch 里的 fetch )。
如果 fetch 耗时比 query 还多,说明磁盘较慢,或者获取了太多文档,或者可能搜索请求设置了太大的分页(比如, size: 10000 )。
4、merges 包括了 Lucene 段合并相关的信息。它会告诉你目前在运行几个合并,合并涉及的文档数量,正在合并的段的总大小,以及在合并操作上消耗的总时间。
在你的集群写入压力很大时,合并统计值非常重要。合并要消耗大量的磁盘 I/O 和 CPU 资源。如果你的索引有大量的写入,同时又发现大量的合并数,一定要去阅读索引性能技巧。
注意:文档更新和删除也会导致大量的合并数,因为它们会产生最终需要被合并的段 碎片 。
ElasticSearch 监控单个节点详解的更多相关文章
- Linux进程实时IO监控iotop命令详解
介绍 Linux下的IO统计工具如iostat, nmon等大多数是只能统计到per设备的读写情况, 如果你想知道每个进程是如何使用IO的就比较麻烦. iotop 是一个用来监视磁盘 I/O 使用状况 ...
- 【精】Linux磁盘I/O性能监控之iostat详解
[精]Linux磁盘I/O性能监控之iostat详解 Linux命令详解----iostat 使用iostat分析IO性能
- Zabbix通过进程名监控进程状态配置详解
Zabbix通过进程名监控进程状态配置详解 有时候我们只能通过进程名监控一个进程是否停掉了,因为有的进程并没有对外提供端口号,以下记录了下详细步骤,通过这个示例会学到很多zabbix核心配置相关的东西 ...
- Elasticsearch shield权限管理详解
Elasticsearch shield权限管理详解 学习了:https://blog.csdn.net/napoay/article/details/52201558 现在(20180424)改名为 ...
- Mercury:唯品会全链路应用监控系统解决方案详解(含PPT)
Mercury:唯品会全链路应用监控系统解决方案详解(含PPT) 原创: 姚捷 高可用架构 2016-08-08
- 干货 | Elasticsearch Nested类型深入详解(转)
https://blog.csdn.net/laoyang360/article/details/82950393 0.概要在Elasticsearch实战场景中,我们或多或少会遇到嵌套文档的组合形式 ...
- 干货 | Elasticsearch Nested类型深入详解
在Elasticsearch实战场景中,我们或多或少会遇到嵌套文档的组合形式,反映在ES中称为父子文档. 父子文档的实现,至少包含以下两种方式: 1)父子文档 父子文档在5.X版本中通过parent- ...
- 【elasticsearch】搜索过程详解
elasticsearch 搜索过程详解 本文基于elasticsearch8.1.在es搜索中,经常会使用索引+星号,采用时间戳来进行搜索,比如aaaa-*在es中是怎么处理这类请求的呢?是对匹配的 ...
- WebConfig节点详解
<!-- Web.config配置文件详解(新手必看) 花了点时间整理了一下ASP.NET Web.config配置文件的基本使用方法. 很适合新手参看,由于Web.config在使用很灵活,可 ...
随机推荐
- POJ 1236 Networks of School Tarjan 基础
题目大意: 给一个有向图,一个文件可以从某个点出发传递向他能连的边 现在有两个问题 1.至少需要多少个放文件可以让整个图都有文件 2.可以进行一个操作:给一对点(u,v)连一条u->v的有向边, ...
- 动态规划DP的斜率优化 个人浅解 附HDU 3669 Cross the Wall
首先要感谢叉姐的指导Orz 这一类问题的DP方程都有如下形式 dp[i] = w(i) + max/min(a(i)*b(j) + c(j)) ( 0 <= j < i ) 其中,b, c ...
- 【POJ 2752 Seek the Name, Seek the Fame】
Time Limit: 2000MSMemory Limit: 65536K Description The little cat is so famous, that many couples tr ...
- @Transactional(rollbackFor=Exception.class)的作用
在项目中,@Transactional(rollbackFor=Exception.class),如果类加了这个注解,那么这个类里面的方 法抛出异常,就会回滚,数据库里面的数据也会回滚. 这种设置是因 ...
- 《c程序设计语言》读书笔记-递归实现快速排序算法
#include <stdio.h> void swap(int v[],int i,int j) { int temp; temp = v[i]; v[i] = v[j]; v[j] = ...
- saltstack 实现haproxy+keepalived
1.目录结构规划如下 mkdir -p /srv/salt/prod/haproxy mkdir -p /srv/salt/prod/keepalived mkdir -p /srv/salt/pro ...
- GitHub上README写法暨markdown语法解读
原文: GitHub上README写法暨markdown语法解读 自从开始玩GitHub以来,就 越来越 感觉它有爱.最近对它的 README.md 文件颇为感兴趣.便写下这贴,帮助更多的还不会编写R ...
- Hibernate的之间生成策略
1.assigned 主键由外部程序负责生成,在save()之前必须指定一个.hibernate不负责维护主键生成.与hibernate和底层数据库都无关.在存储对象前,必须使用主键的setter方法 ...
- poj 3744 Scout YYF 1 (概率DP+矩阵快速幂)
F - Scout YYF I Time Limit:1000MS Memory Limit:65536KB 64bit IO Format:%I64d & %I64u Sub ...
- F28379D烧写双核程序(在线&离线)
烧写双核程序前需知在分别对F28379D的CPU1和CPU2两个核进行烧写程序时,需要在CCS中建立两个工程,独立编写两个核的程序.如controlSUITE中提供的双核程序例程: 1. 在线1.1 ...