5.Mongodb聚合
聚合 aggregate
- 聚合(aggregate)主要用于计算数据,类似sql中的sum()、avg()
- 语法
db.集合名称.aggregate([{管道:{表达式}}])
1、管道
- 管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的输入
ps ajx | grep mongo
- 在mongodb中,管道具有同样的作用,文档处理完毕后,通过管道进行下一次处理
- 常用管道
- $group:将集合中的文档分组,可用于统计结果
- $match:过滤数据,只输出符合条件的文档
- $project:修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
- $sort:将输入文档排序后输出
- $limit:限制聚合管道返回的文档数
- $skip:跳过指定数量的文档,并返回余下的文档
- $unwind:将数组类型的字段进行拆分
2、表达式
- 处理输入文档并输出
- 语法
表达式:'$列名'
- 常用表达式
- $sum:计算总和,$sum:1同count表示计数
- $avg:计算平均值
- $min:获取最小值
- $max:获取最大值
- $push:在结果文档中插入值到一个数组中
- $first:根据资源文档的排序获取第一个文档数据
- $last:根据资源文档的排序获取最后一个文档数据
3、$group
- 将集合中的文档分组,可用于统计结果
- _id表示分组的依据,使用某个字段的格式为'$字段'
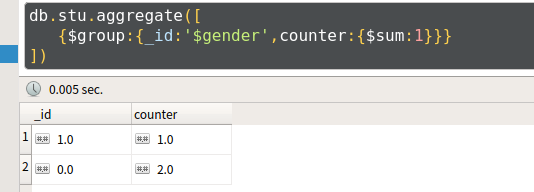
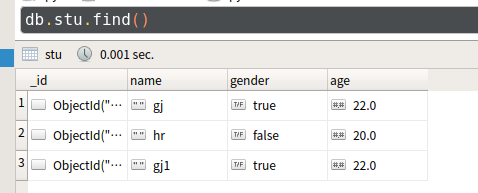
- 例1:统计男生、女生的总人数
db.stu.aggregate([
{$group:
{
_id:'$gender',
counter:{$sum:}
}
}
])
Group by null
- 将集合中所有文档分为一组
- 例2:求学生总人数、平均年龄
db.stu.aggregate([
{$group:
{
_id:null,
counter:{$sum:},
avgAge:{$avg:'$age'}
}
}
])
透视数据
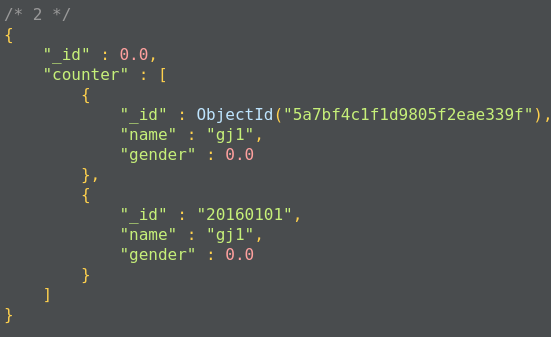
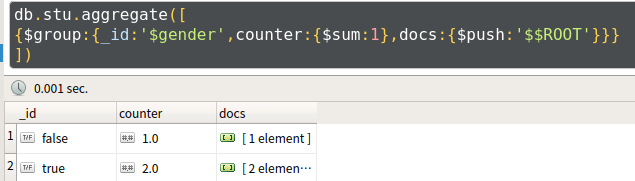
- 例3:统计学生性别及学生姓名
db.stu.aggregate([
{$group:
{
_id:'$gender',
name:{$push:'$name'}
}
}
])

- 使用$$ROOT可以将文档内容加入到结果集的数组中,代码如下
db.stu.aggregate([
{$group:
{
_id:'$gender',
name:{$push:'$$ROOT'}
}
}
])

4、$match
- 用于过滤数据,只输出符合条件的文档
- 使用MongoDB的标准查询操作
例1:查询年龄大于20的学生
db.stu.aggregate([
{$match:{age:{$gt:}}}
])
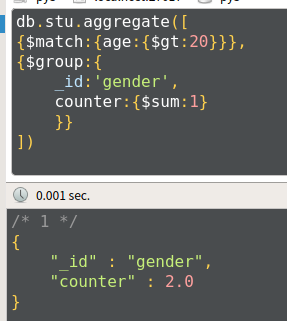
例2:查询年龄大于20的男生、女生人数
db.stu.aggregate([
{$match:{age:{$gt:}}},
{$group:{_id:'$gender',counter:{$sum:}}}
])
5、$project
- 修改输入文档的结构,如重命名、增加、删除字段、创建计算结果
例1:查询学生的姓名、年龄
db.stu.aggregate([
{$project:{_id:,name:,age:}}
])
例2:查询男生、女生人数,输出人数
db.stu.aggregate([
{$group:{_id:'$gender',counter:{$sum:}}},
{$project:{_id:,counter:}}
])

6、$sort
- 将输入文档排序后输出
例1:查询学生信息,按年龄升序
b.stu.aggregate([{$sort:{age:1}}])
例2:查询男生、女生人数,按人数降序
db.stu.aggregate([
{$group:{_id:'$gender',counter:{$sum:}}},
{$sort:{counter:-}}
])

7、$limit
- 限制聚合管道返回的文档数
- 例1:查询2条学生信息
db.stu.aggregate([{$limit:2}])
8、$skip
- 跳过指定数量的文档,并返回余下的文档
例2:查询从第3条开始的学生信息
db.stu.aggregate([{$skip:2}])
例3:统计男生、女生人数,按人数升序,取第二条数据
db.stu.aggregate([
{$group:{_id:'$gender',counter:{$sum:}}},
{$sort:{counter:}},
{$skip:},
{$limit:}
])
- 注意顺序:先写skip,再写limit

9、$unwind
- 将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值
语法1
- 对某字段值进行拆分
db.集合名称.aggregate([{$unwind:'$字段名称'}])
- 构造数据
db.t2.insert({_id:1,item:'t-shirt',size:['S','M','L']})
- 查询
db.t2.aggregate([{$unwind:'$size'}])
语法2
- 对某字段值进行拆分
- 处理空数组、非数组、无字段、null情况
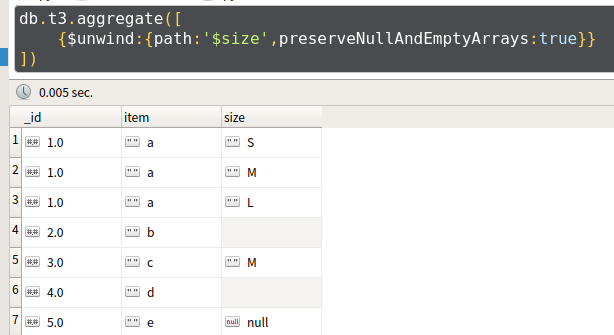
db.inventory.aggregate([{
$unwind:{
path:'$字段名称',
preserveNullAndEmptyArrays:<boolean>#防止数据丢失
}
}])
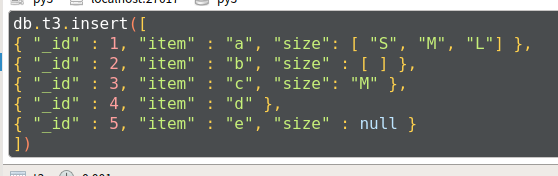
- 构造数据
db.t3.insert([
{ "_id" : , "item" : "a", "size": [ "S", "M", "L"] },
{ "_id" : , "item" : "b", "size" : [ ] },
{ "_id" : , "item" : "c", "size": "M" },
{ "_id" : , "item" : "d" },
{ "_id" : , "item" : "e", "size" : null }
])
- 使用语法1查询
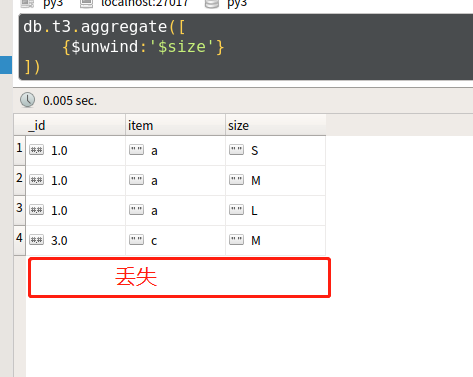
db.t3.aggregate([{$unwind:'$size'}])
- 查看查询结果,发现对于空数组、无字段、null的文档,都被丢弃了
- 问:如何能不丢弃呢?
- 答:使用语法2查询


10、实验

5.Mongodb聚合的更多相关文章
- MongoDB 聚合管道(Aggregation Pipeline)
管道概念 POSIX多线程的使用方式中, 有一种很重要的方式-----流水线(亦称为"管道")方式,"数据元素"流串行地被一组线程按顺序执行.它的使用架构可参考 ...
- Mongodb学习笔记四(Mongodb聚合函数)
第四章 Mongodb聚合函数 插入 测试数据 ;j<;j++){ for(var i=1;i<3;i++){ var person={ Name:"jack"+i, ...
- mongodb MongoDB 聚合 group
MongoDB 聚合 MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*). 基本语法为:db.col ...
- MongoDB 聚合
聚合操作过程中的数据记录和计算结果返回.聚合操作分组值从多个文档,并可以执行各种操作,分组数据返回单个结果.在SQL COUNT(*)和group by 相当于MongoDB的聚集. aggregat ...
- MongoDB聚合
--------------------MongoDB聚合-------------------- 1.aggregate(): 1.概念: 1.简介 ...
- MongoDB 聚合分组取第一条记录的案例及实现
关键字:MongoDB: aggregate:forEach 今天开发同学向我们提了一个紧急的需求,从集合mt_resources_access_log中,根据字段refererDomain分组,取分 ...
- mongodb MongoDB 聚合 group(转)
MongoDB 聚合 MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*). 基本语法为:db.col ...
- mongodb聚合 group
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*). 基本语法为:db.collection.agg ...
- MongoDB 聚合(管道与表达式)
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*). aggregate() 方法 MongoDB中 ...
- 【Mongodb教程 第十一课 】MongoDB 聚合
聚合操作过程中的数据记录和计算结果返回.聚合操作分组值从多个文档,并可以执行各种操作,分组数据返回单个结果.在SQL COUNT(*)和group by 相当于MongoDB的聚集. aggregat ...
随机推荐
- 爆料!如何在Visual Studio 2017上体验五星级云服务
2017 年 3 月初,号称宇宙最强 IDE 之一的 Visual Studio 发布了最新的 2017 版本,遥想自己使用 VC++ 6.0 的当年,看着现在已然稀疏的头发,真是一入 IT 似海深, ...
- webstrom使用
主题 主题下载:http://color-themes.com/?view=index&page=1&order=popular&search=&layout=HTML ...
- 浩顺晶密K-5 打卡时间设置
公司有一台浩顺晶密K-5打卡设备,因为时间异常需要重新调整,设备外部就几个按钮,全部按了一遍发现没有任何变化,所以肯定是哪里操作不对,然后用钥匙打开这个设置,上面有一排文字,分别是设置.+.-.确认等 ...
- API:相关词语笔记
1.SDK 软件开发套件,接口服务器把接口开发之后,把怎么使用的示范代码弄出来给API客户端的开发者参考. 2.头部信息 对头部信息的特殊符号有要求,例如: 持续更新中....
- 屏蔽各类弹窗广告(WPS、智能云输入法)
托盘中的广告“领取双11红包,最高1111元”的罪魁祸首是“智能云输入法” 广告在托盘中闪动: 结束SCSkinInst.exe后,托盘中的广告消失: 智能云输入法的安装路径可参考: C:\Progr ...
- 利用Excel导入数据到SAP C4C
假设要导入一个Account数据到C4C系统. 工作中心Data Workbench,工作中心视图Import,点download metadata: 会下载一个压缩包到本地. 进入文件夹Templa ...
- 119. Pascal's Triangle II (Amazon) from leetcode
Given a non-negative index k where k ≤ 33, return the kth index row of the Pascal's triangle. Note t ...
- iis 7 操作 .net
下面说一下.NET对IIS7操作.IIS7的操作和IIS5/6(using system.DirectoryServices;使用类DirectoryEntry )有很大的不同,在IIS7里增加了 M ...
- hdu-3449 Consumer---有依赖性质的背包
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=3449 题目大意: fj打算去买一些东西,在那之前,他需要一些盒子去装他打算要买的不同的物品.每一个盒 ...
- 使用taobao cnpm 源解决npm无法安装module问题
npm 安装nativescript时出现异常,一直停着不动.应该是源被墙了的问题可以使用淘宝仓库,执行下面的命令: alias cnpm="npm --registry=https://r ...